volatile并不能保证数据同步、只能保证读取到最新主内存数据
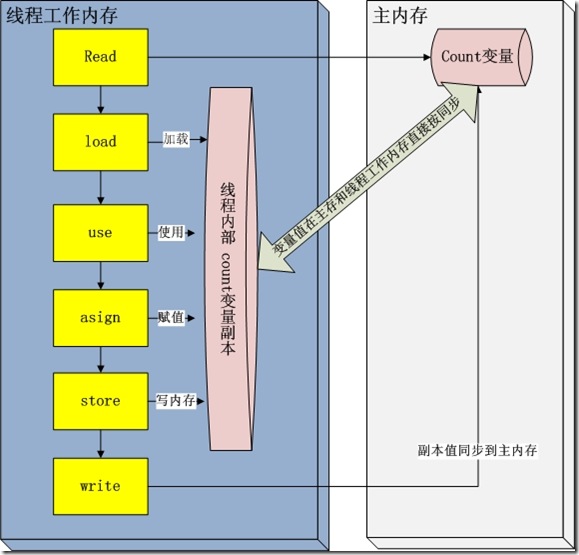
在 java 垃圾回收整理一文中,描述了jvm运行时刻内存的分配。其中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,
线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存
变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,
在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。下面一幅图
描述这写交互
volatile关键字在Java编程中,应用的比较少,主要原因无外乎两点,一是因为Java1.5之前该关键字在不同的系统下的表现没有统一,所带来的问题就是程序的可移植性比较差,其二,就是因为非常难设计,而且误用比较多,所以导致volatile的名誉受损。
我们都知道,每个线程都运行在栈内存之中,每个线程都有自己的工作内存空间,比如说寄存器,高速缓冲储存器等,线程的计算一般是 通过在工作内存进行交互的,我们来看一下图片,来更明确这一点:

从图上,我们很清楚的知道了线程读入变量的时候是从主内存加载到工作内存中的值,线程的写也是在这一个工作内存中,之后在刷新到主内存中,这样就会产生一个问题,就是线程读取的值是不新鲜的值,会出现不同线程所持有的“相同”公共变量不同步的情况。
应对这种情况的办法还是很多的,比如说在更新和读取时使用synchronized的同步代码,或者使用Lock解决该问题,不过,Java可以使用非常 简单的方法实现该问题,比如说,这篇文章的主角,volatile,加上该关键字之后,可以确保每一条线程在对改制进行操作的时候是面向主内存中的值,而 不是工作内存的值,示意图:

这就是volatile的原理,但是,这是不是就能保证数据的同步性呢?
答案是,当然不能。
以下代码可以尝试运行一下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
public class Main { public volatile static int count = 0; /** * @param _something * @author mikecoder * @throws InterruptedException */ public static void main(String[] _something) throws InterruptedException{ class UnsafeThread implements Runnable{ @Override public void run() { for (int i = 0; i < 10000; i++) { Math.hypot(Math.pow(92456789, i), Math.cos(i)); } count ++; } public int getCount(){ return count; } } int value = 1000; int loops = 0; ThreadGroup threadGroup = Thread.currentThread().getThreadGroup(); while(loops++ < value){ UnsafeThread unsafeThread = new UnsafeThread(); for (int i = 0; i < 1000; i++) { new Thread(new UnsafeThread()).start(); } do { Thread.sleep(5); } while (threadGroup.activeCount() != 1); if (unsafeThread.getCount() != value) { System.out.println("Loops:" + loops + " Unsafe!"); System.out.println("Count:" + unsafeThread.getCount()); System.exit(0); } count = 0; System.out.println("Loops:" + loops + " Safe!"); } }} |
恩,这就是一个线程不安全的程序,当然,出现不安全的时候需要一定的条件,比如说CPU负担过重,具体的线程调度就不扯了,基本上也就是单核和多核的区别.这是我的运行结果:

在第12次循环的时候出现了线程不安全的情况.所以,volatile并不能保证数据是同步的,只能保证线程得到的数据是最新的.
那么,我们应该在什么情况下使用volatile关键字呢?
其实很简单.只要符合以下两个条件就能使用volatile,并且能收到很不错的效果.
1.对变量的写入不依赖变量的当前值,或者只有一个线程更新变量的值.
2.该变量不会和其他状态变量一起被列为不变性条件中(注1).
那么,本文的这个问题该怎么解决呢?其实很简单,在修改变量的时候进行同步或者加锁就行.具体的实现方法就不说了,相信大家也都知道了.
volatile并不能保证数据同步、只能保证读取到最新主内存数据的更多相关文章
- redis秒杀系统数据同步(保证不多卖)
东西不多卖 秒杀系统需要保证东西不多卖,关键是在多个客户端对库存进行减操作时,必须加锁.Redis中的Watch刚好可以实现一点.首先我们需要获取当前库存,只有库存中的食物小于购物车的数目才能对库存进 ...
- 基于 MySQL Binlog 的 Elasticsearch 数据同步实践 原
一.背景 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数据可以 ...
- 基于MySQL Binlog的Elasticsearch数据同步实践
一.为什么要做 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数 ...
- Redis 高可用篇:你管这叫主从架构数据同步原理?
在<Redis 核心篇:唯快不破的秘密>中,「码哥」揭秘了 Redis 五大数据类型底层的数据结构.IO 模型.线程模型.渐进式 rehash 掌握了 Redis 快的本质原因. 接着,在 ...
- linux下实现web数据同步的四种方式(性能比较)
实现web数据同步的四种方式 ======================================= 1.nfs实现web数据共享2.rsync +inotify实现web数据同步3.rsyn ...
- java数据同步陷阱
并发,我的理解就是同时运行多个程序.同时,难以避免的就是数据的同步问题,如果数据同步问题处理不好就很容易造成程序出现bug,当然,对于其造成的危害,不加详述. 首先,来看一个简单的例子,当然,这个例子 ...
- 总结:基于Oracle Logminer数据同步
第 1 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan LogMiner 配置使用手册 1 Logminer 简介 1.1 LogMin ...
- 基于datax的数据同步平台
一.需求 由于公司各个部门对业务数据的需求,比如进行数据分析.报表展示等等,且公司没有相应的系统.数据仓库满足这些需求,最原始的办法就是把数据提取出来生成excel表发给各个部门,这个功能已经由脚本转 ...
- Caffe源码理解2:SyncedMemory CPU和GPU间的数据同步
目录 写在前面 成员变量的含义及作用 构造与析构 内存同步管理 参考 博客:blog.shinelee.me | 博客园 | CSDN 写在前面 在Caffe源码理解1中介绍了Blob类,其中的数据成 ...
随机推荐
- Scala学习笔记(五)—— 元组和集合
1. 映射 映射Java中的Map,即Key/Value的数据形式 映射的创建,有以下两种方法 scala> val map =Map("Lisa" -> 90 , & ...
- Java设计模式(23)——行为模式之访问者模式(Visitor)
一.概述 概念 作用于某个对象群中各个对象的操作.它可以使你在不改变这些对象本身的情况下,定义作用于这些对象的新操作. 引入 试想这样一个场景,在一个Collection中放入了一大堆的各种对象的引用 ...
- Tomcat7 调优及 JVM 参数优化
Tomcat 的缺省配置是不能稳定长期运行的,也就是不适合生产环境,它会死机,让你不断重新启动,甚至在午夜时分唤醒你.对于操作系统优化来说,是尽可能的增大可使用的内存容量.提高CPU 的频率,保证 ...
- Java设计模式(7)——结构型模式之适配器模式(Adapter)
一.概述 概念 其实,举个生活中的例子的话,适配器模式可以类比转接头,比如typeC和USB的转接头,把原本只能接typeC的接口,拓展为可以接普通USB:这里的转接头一方面需要查在typeC上,一方 ...
- VR中为什么需要把游戏音频放在聚光灯里?
VR中为什么需要把游戏音频放在聚光灯里? 本文章由cartzhang编写,转载请注明出处. 所有权利保留. 文章链接:http://blog.csdn.net/cartzhang/article/de ...
- BZOJ1066_蜥蜴_KEY
题目传送门 经过长时间的旅行,很长时间没写过博客了,这次把上次WA的题目过了. 由于每次蜥蜴从石柱上跳下时,石柱的高度会-1,可以看做占了一格的流量. 建图: 1.建超级源和超级汇,设超级源连到每只蜥 ...
- 更改steam的游戏库
用记事本打开steam/steamapps/libraryfolders.vdf,然后按照格式添加条目 "LibraryFolders"{ "TimeNextStatsR ...
- myeclipse 配置堆内存
2.非堆内存分配 JVM使用-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64:由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4. 打开myeclipse ...
- TPO-11 C2 Work for the biology committee
committee 委员会 representative 代表 department secretary 系里的秘书 applicant 申请人 TPO-11 C2 Work for the biol ...
- flume-kafka-storm-hdfs-hadoop-hbase
# bigdata-demo 项目地址: https://github.com/windwant/bigdata-demo.git hadoop: hadoop hdfs操作 log输出到flume ...