【spark】连接Hbase
0.我们有这样一个表,表名为Student

1.在Hbase中创建一个表

表明为student,列族为info
2.插入数据
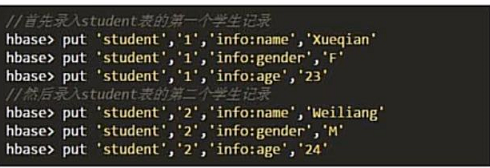
我们这里采用put来插入数据
格式如下 put ‘表命’,‘行键’,‘列族:列’,‘值’
我们知道Hbase 四个键确定一个值,
一般查询的时候我们需要提供 表名、行键、列族:列名、时间戳才会有一个确定的值。
但是这里插入的时候,时间戳自动被生成,我们并不用额外操作。
我们不用表的时候可以这样删除

注意,一定要先disable 再drop,不能像RDMS一样直接drop
3.配置spark
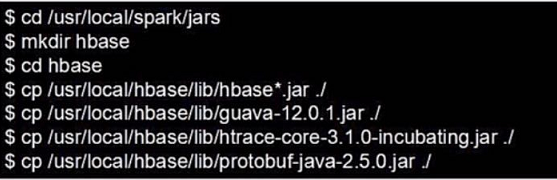
我们需要把Hbase的lib目录下的一些jar文件拷贝到Spark中,这些都是编程中需要引进的jar包。
需要拷贝的jar包包括:所有hbase开头的jar文件、guava-12.0.1.jar、htrace-core-3.1.0-incubating.jar和protobuf-java-2.5.0.jar
我们将文件拷贝到Spark目录下的jars文件中
4.编写程序
(1)读取数据

我们程序中需要的jar包如下

我们这里使用Maven来导入相关jar包
我们需要导入hadoop和spark相关的jar包
spark方面需要导入的依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
hadoop方面需要导入的依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
hbase方面需要导入的依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
我们使用的org.apache.hadoop.hbase.mapreduce是通过hbase-server导入的。
具体的程序如下
import org.apache.hadoop.hbase._
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.{SparkConf, SparkContext}
object SparkOperateHbase{
def main(args:Array[String]): Unit ={
//建立Hbase的连接
val conf = HBaseConfiguration.create();
//设置查询的表名student
conf.set(TableInputFormat.INPUT_TABLE,"student")
//通过SparkContext将student表中数据创建一个rdd
val sc = new SparkContext(new SparkConf());
val stuRdd = sc.newAPIHadoopRDD(conf,classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result]);
stuRdd.cache();//持久化
//计算数据条数
val count = stuRdd.count();
println("Student rdd count:"+count);
//遍历输出
//当我们建立Rdd的时候,前边全部是参数信息,后边的result才是保存数据的数据集
stuRdd.foreach({case (_,result) =>
//通过result.getRow来获取行键
val key = Bytes.toString(result.getRow);
//通过result.getValue("列族","列名")来获取值
//注意这里需要使用getBytes将字符流转化成字节流
val name = Bytes.toString(result.getValue("info".getBytes,"name".getBytes));
val gender = Bytes.toString(result.getValue("info".getBytes,"gender".getBytes));
val age = Bytes.toString(result.getValue("info".getBytes,"age".getBytes));
//打印结果
println("Row key:"+key+" Name:"+name+" Gender:"+gender+" Age:"+age);
});
}
}
(2)存入数据
import org.apache.hadoop.hbase.client.{Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.{SparkConf, SparkContext}
object HbasePut{
def main(args:Array[String]): Unit = {
//建立sparkcontext
val sparkConf = new SparkConf().setAppName("HbasePut").setMaster("local")
val sc = new SparkContext(sparkConf)
//与hbase的student表建立连接
val tableName = "student"
sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE,tableName)
//建立任务job
val job = new Job(sc.hadoopConfiguration)
//配置job参数
job.setOutputKeyClass(classOf[ImmutableBytesWritable])
job.setOutputValueClass(classOf[Result])
job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
//要插入的数据,这里的makeRDD是parallelize的扩展版
val indataRdd = sc.makeRDD(Array("3,zhang,M,26","4,yue,M,27"))
val rdd = indataRdd.map(_.split(",")).map(arr=>{
val put = new Put(Bytes.toBytes(arr(0))) //行键的值
//依次给列族info的列添加值
put.add(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(arr(1)))
put.add(Bytes.toBytes("info"),Bytes.toBytes("gender"),Bytes.toBytes(arr(2)))
put.add(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(arr(3)))
//必须有这两个返回值,put为要传入的数据
(new ImmutableBytesWritable,put)
})
rdd.saveAsNewAPIHadoopDataset(job.getConfiguration)
}
}
5.Maven打包
我们用命令行打开到项目的根目录,输入mvn clean package -DskipTests=true
打包成功后我们到项目目录下的target文件下就会找到相应的jar包
6.提交任务

【spark】连接Hbase的更多相关文章
- Spark操作hbase
于Spark它是一个计算框架,于Spark环境,不仅支持单个文件操作,HDFS档,同时也可以使用Spark对Hbase操作. 从企业的数据源HBase取出.这涉及阅读hbase数据,在本文中尽快为了尽 ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
前言 在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误.我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了.因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题. 说明: ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- [Spark] 04 - HBase
BHase基本知识 基本概念 自我介绍 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”. ...
- Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作
Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作 1.sparkstreaming实时写入Hbase(saveAsNewAPIHadoopDataset方法 ...
- MapReduce和Spark写入Hbase多表总结
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 大家都知道用mapreduce或者spark写入已知的hbase中的表时,直接在mapreduc ...
- spark 操作hbase
HBase经过七年发展,终于在今年2月底,发布了 1.0.0 版本.这个版本提供了一些让人激动的功能,并且,在不牺牲稳定性的前提下,引入了新的API.虽然 1.0.0 兼容旧版本的 API,不过还是应 ...
- docker 安装 hbase安装 java连接hbase (mac环境)
docker 安装 https://hub.docker.com/editions/community/docker-ce-desktop-mac 下载地址 下载完之后,安装app一样安装就好 安装完 ...
- Spark读Hbase优化 --手动划分region提高并行数
一. Hbase的region 我们先简单介绍下Hbase的架构和Hbase的region: 从物理集群的角度看,Hbase集群中,由一个Hmaster管理多个HRegionServer,其中每个HR ...
- spark读写hbase性能对比
一.spark写入hbase hbase client以put方式封装数据,并支持逐条或批量插入.spark中内置saveAsHadoopDataset和saveAsNewAPIHadoopDatas ...
随机推荐
- 部门人员能力模型的思考:海军 or 海盗——By Me
我们欢迎您的加入,与我们一起推动安全可视化团队的成长,实现技术上共同进步和感情上的更多互相支持!
- ORACLE性能优化- Buffer cache 的调整与优化
Buffer Cache是SGA的重要组成部分,主要用于缓存数据块,其大小也直接影响系统的性能.当Buffer Cache过小的时候,将会造成更多的 free buffer waits事件. 下面将具 ...
- 剑指offer(第2版)刷题 Python版汇总
剑指offer面试题内容 第2章 面试需要的基础知识 面试题1:赋值运算符函数 面试题2:实现Singleton模式 解答 面试题3:数组中重复的数字 解答 面试题4:二维数组中的查找 解答 面试题 ...
- beego——构造查询
QueryBuilder提供了一个简单.流畅的SQL查询构造器.在不影响代码可读性的前提下用来快速的建立SQL语句. QueryBuilder在功能上与ORM重合,但是个由利弊,ORM更适合用于简单的 ...
- 其他机器访问本机redis服务器
- CentOS中nginx负载均衡和反向代理的搭建
1: 修改centos命令行启动(减少内存占用): vim /etc/inittab :initdefault: --> 修改5为3 若要界面启动使用 startx 2:安装jdk )解压:jd ...
- PAT 天梯赛 L1-012. 计算指数 【水】
题目链接 https://www.patest.cn/contests/gplt/L1-012 AC代码 #include <iostream> #include <cstdio&g ...
- gitlab + jenkins + docker + k8s
总体流程: 在开发机开发代码后提交到gitlab 之后通过webhook插件触发jenkins进行构建,jenkins将代码打成docker镜像,push到docker-registry 之后将在k8 ...
- 优秀 H5 案例收集 vol.1(不定期更新)
一生要历经的三种战斗http://datang.wearewer.com/ 雍正去哪儿http://news.163.com/college/special/craftsman_h5/ 比Emoji更 ...
- [pixhawk笔记]2-飞行模式
本文翻译自px4官方开发文档:https://dev.px4.io/en/concept/flight_modes.html ,有不对之处,敬请指正. pixhawk的飞行模式如下: MANUAL( ...