python 解析 XML文件
如下使用xml.etree.ElementTree模块来解析XML文件。ElementTree模块中提供了两个类用来完成这个目的:
- ElementTree表示整个XML文件(一个树形结构)
- Element表示树中的一个元素(结点)
我们操作如下XML文件:migapp.xml

我们可以通过如下方式导入ElementTree模块: import xml.etree.ElementTree as ET
或者也可以仅导入parse解析器: from xml.etree.ElementTree import parse
首先需要打开一个xml文件,本地文件使用open函数,如果是互联网文件,则使用urlopen:
f = open('migapp.xml', 'rt', encoding='utf-8')
然后对XML进行解析。
1 解析XML文件
1.1 解析根元素
tree = ET.parse(f)
root = tree.getroot()
print('root.tag =', root.tag)
print('root.attrib =', root.attrib)

1.2 解析根的儿子
for child in root: # 仅可以解析出root的儿子,不能解析出root的子孙
print(child.tag)
print(child.attrib) # attrib is a dict

1.3 通过索引解析根的子孙
print(root[1][1].tag)
print(root[1][1].text)

1.4 迭代解析出所有的指定element
for element in root.iter('environment'):
print(element.attrib)

1.5 几个有用的方法
# element.findall()解析出指定element的所有儿子
# element.find()解析出指定element的第一个儿子
# element.get()解析出指定element的属性attrib
for environment in root.findall('environment'):
first_variable = environment.find('variable')
print(first_variable.get('name'))

2 修改XML文件
假设我们需要给每个text元素添加一个属性size="50",修改其text为"Benxin Tuzi",添加一个子元素date="2016/01/16"
for text in root.iter('text'):
text.set('size', '')
text.text = 'Benxin Tuzi'
text.append(ET.Element('date', attrib={}, text='2016/01/16'))
tree.write('output.xml')
migapp.xml中的部分:
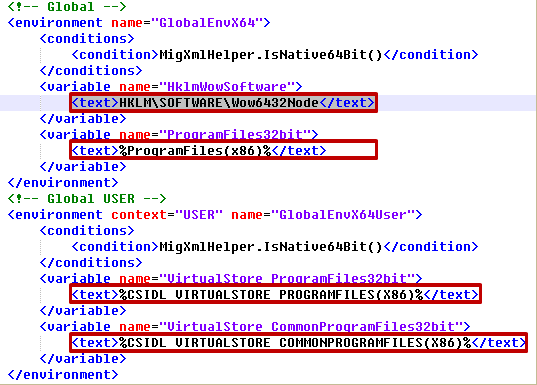
output.xml中对应的部分:

3 说明事项
- 不要使用xml.py作为文件名,否则此时会发生如下错误:
ImportError: No module named 'xml.etree'; 'xml' is not a package
分析:
这是由于import时会先在当前路径下寻找,此时发现存在xml.py模块,而我们自己写的xml.py当然不是一个package
注意:
删除xml.py后仍然不能成功解释,那是因为当前路径中还生成了xml.pyc,而该文件的优先级要高于xml.py,因此解释器还是优先在xml.pyc中寻找,因此必须将该文件也删除掉,成功解决问题。
结论:
文件名尽量不要与包名或者模块名同名,即使你在脚本中不使用该模块或者包,否则可能发生奇怪的错误。
- ElementTree模块中提供的很多解析函数都需要预先将整个XML文档读入内存中,这对于大型XML解析而言,不是一件好事,尤其是当我们从网络、管道中读取XML时,非阻塞式的解析非常重要。此时,我们可以使用ElementTree模块中的XMLPullParse类来处理。当然我们也可以选择ElementTree模块的iterparse()来代替,该方法在解析大型XML时也不需要全部读入内存。
python 解析 XML文件的更多相关文章
- python 解析xml 文件: Element Tree 方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- python 解析xml 文件: DOM 方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- python 解析xml 文件: SAX方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- 遍历文件 创建XML对象 方法 python解析XML文件 提取坐标计存入文件
XML文件??? xml即可扩展标记语言,它可以用来标记数据.定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言. 里面的标签都是可以随心所欲的按照他的命名规则来定义的,文件名为roi.xm ...
- Python 解析 XML 文件生成 HTML
XML文件result.xml,内容如下: <ccm> <metric> <complexity>1</complexity> <unit> ...
- 【TensorFlow】Python解析xml文件
最近在项目中使用TensorFlow训练目标检测模型,在制作自己的数据集时使用了labelimg软件对图片进行标注,产生了VOC格式的数据,但标注生成的xml文件标签值难免会产生个别错误造成程序无法跑 ...
- Python解析xml文件遇到的编码解析的问题
使用python对xml文件进行解析的时候,假设xml文件的头文件是utf-8格式的编码,那么解析是ok的,但假设是其它格式将会出现例如以下异常: xml.parsers.expat.ExpatErr ...
- [转载] python 解析xml 文件: SAX方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- python解析xml文件时使用ElementTree和cElementTree的不同点;iter
在python中,解析xml文件时,会选用ElementTree或者cElementTree,那么两者有什么不同呢? 1.cElementTree速度上要比ElementTree快,比较cElemen ...
随机推荐
- 【前端】JavaScript
一.JavaScript概述 1.JavaScript的历史 1992年Nombas开发出C-minus-minus(C--)的嵌入式脚本语言(最初绑定在CEnvi软件中).后将其改名ScriptEa ...
- C# Oracle.ManagedDataAccess 批量更新表数据
这是我第一次发表博客.以前经常到博客园查找相关技术和代码,今天在写一段小程序时出现了问题, 但在网上没能找到理想的解决方法.故注册了博客园,想与新手分享(因为本人也不是什么高手). vb.net和C# ...
- scrapy抓取的中文结果乱码解决办法
使用scrapy抓取的结果,中文默认是Unicode,无法显示中文. 中文默认是Unicode,如: \u5317\u4eac\u5927\u5b66 在setting文件中设置: FEED_EXPO ...
- .Net并行编程高级教程(二)-- 任务并行
前面一篇提到例子都是数据并行,但这并不是并行化的唯一形式,在.Net4之前,必须要创建多个线程或者线程池来利用多核技术.现在只需要使用新的Task实例就可以通过更简单的代码解决命令式任务并行问题. 1 ...
- 点滴积累【C#】---验证码,ajax提交
效果: 思路: 借用ashx文件创建四位验证,首先生成四位随机数字.然后创建画布,再将创建好的验证码存入session,然后前台进行button按钮将文本框中的值进行ajax请求到后台,和sessio ...
- SecureCRT终端上使用spark-shell时按退格键无反应的解决方法
问题:用SecureCRT远程连接至Spark集群,启动spark-shell却发现输错命令后却无法用退格键删除. 解决方法: 第一步: 在SecureCRT的菜单栏选择“OPtions(选项)”按钮 ...
- atitit.提取zip rar文件列表 java php c# 的原理与设计
atitit.java提取zip rar文件列表 1. 取zip rar文件的场景问题 1 1.1. 多重压缩的问题 1 1.2. 文件名编码的问题 1 1.3. 目录的判定 1 2. rar的解析 ...
- 3.selenium模块
本节内容: 介绍 安装 基本使用 选择器 等待元素被加载 元素交互操作 其他 项目练习 一.介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行Ja ...
- 安装gstreamer开发环境
ubuntu中安装gstreamer开发环境: * 安装gstreamer基本库,工具,以及插件 sudo apt--dev gstreamer-tools gstreamer0.-tools gst ...
- 解决:std::ostream operator<< should have been declared inside 'xxx'
用VS的NMAKE构建,不会报错,但是用GNU MAKE构建,就会报错.(尝试删除Toast.h中第24行的声明) 因此在遇到类似的情况的时候,记得不仅class里面要有friend声明,namesp ...