常州模拟赛d7t3 水管

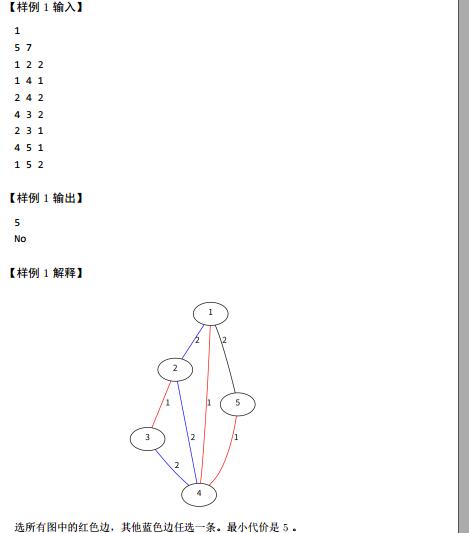
分析:第一问还是很好做的,关键是怎么做第二问.我们可以每次删掉最小生成树上的一条边,然后再求一次最小生成树,看边权和大小和原来的是不是一样的,不过这个做法效率很低.
考虑Kruskal算法的原理,每次加边权最小的边,如果边上的两个点不连通.如果在最小生成树的基础上把不是上面的边给加上去,就会形成环,在环上找除了这条边之外的最大边权,如果等于新加入的这条边,那么就有多个最小生成树.为什么这样呢?我们把最大边拿掉,添加进这条边,两个点还是连通的,边权和一定,只是在Kruskal的时候先考虑了那条最大边而已.
接下来只需要求出若干对点路径上的最大边权就可以了,我们可以用倍增算法来求.
写这道题的时候把w数组写成了e[i].w,挂惨了......以后要对同名数组多留意.
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm> using namespace std; const int maxn = ; int T, n, m, head[maxn], nextt[maxn], to[maxn], w[maxn], tot = ,fa[maxn],d[maxn],f[maxn][],dmax[maxn][];
long long ans;
bool flag = false; struct node
{
int u, v, w,use;
}e[maxn]; void add(int x, int y, int z)
{
w[tot] = z;
to[tot] = y;
nextt[tot] = head[x];
head[x] = tot++;
} bool cmp(node a, node b)
{
return a.w < b.w;
} int find(int x)
{
if (x == fa[x])
return x;
return fa[x] = find(fa[x]);
} void dfs(int u, int depth,int from)
{
d[u] = depth;
f[u][] = from;
for (int i = head[u]; i; i = nextt[i])
{
int v = to[i];
if (v != from)
{
dmax[v][] = w[i];
dfs(v, depth + , u);
}
}
} int LCA(int x, int y)
{
if (x == y)
return ;
if (d[x] < d[y])
swap(x, y);
int maxx = ;
for (int i = ; i >= ; i--)
if (d[f[x][i]] >= d[y])
{
maxx = max(maxx, dmax[x][i]);
x = f[x][i];
} if (x == y)
return maxx; for (int i = ; i >= ; i--)
if (f[x][i] != f[y][i])
{
maxx = max(maxx, max(dmax[x][i], dmax[y][i]));
x = f[x][i];
y = f[y][i];
}
maxx = max(maxx, max(dmax[x][], dmax[y][]));
return maxx;
} int main()
{
scanf("%d", &T);
while (T--)
{
memset(head, , sizeof(head));
tot = ;
ans = ;
flag = false;
scanf("%d%d", &n, &m);
memset(d, , sizeof(d));
memset(f, , sizeof(f));
memset(dmax, , sizeof(dmax));
for (int i = ; i <= n; i++)
fa[i] = i;
for (int i = ; i <= m; i++)
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
e[i].u = a;
e[i].v = b;
e[i].w = c;
e[i].use = ;
}
sort(e + , e + + m, cmp);
for (int i = ; i <= m; i++)
{
int fx = find(e[i].u), fy = find(e[i].v);
if (fx != fy)
{
add(e[i].u, e[i].v, e[i].w);
add(e[i].v, e[i].u, e[i].w);
fa[fx] = fy;
ans += e[i].w;
e[i].use = ;
}
}
printf("%lld\n", ans);
dfs(, ,);
for (int j = ; j <= ; j++)
for (int i = ; i <= n; i++)
{
f[i][j] = f[f[i][j - ]][j - ];
dmax[i][j] = max(dmax[i][j - ], dmax[f[i][j - ]][j - ]);
}
for (int i = ; i <= m; i++)
if (!e[i].use && LCA(e[i].u, e[i].v) == e[i].w)
{
flag = ;
break;
}
if (flag)
puts("No");
else
puts("Yes");
} return ;
}
常州模拟赛d7t3 水管的更多相关文章
- 常州模拟赛d4t1 立方体
题目描述 立方体有 6 个面,每个面上有一只奶牛,每只奶牛都有一些干草.为了训练奶牛的合作精神,它 们在玩一个游戏,每轮:所有奶牛将自己的干草分成 4 等份,分给相邻的 4 个面上的奶牛. 游戏开始, ...
- 常州模拟赛d6t3 噪音
FJ有M个牛棚,编号1至M,刚开始所有牛棚都是空的.FJ有N头牛,编号1至N,这N头牛按照编号从小到大依次排队走进牛棚,每一天只有一头奶牛走进牛棚.第i头奶牛选择走进第p[i]个牛棚.由于奶牛是群体动 ...
- bzoj3743 [Coci2015]Kamp 常州模拟赛d6t2
3743: [Coci2015]Kamp Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 484 Solved: 229[Submit][Status ...
- 常州模拟赛d5t2 mogician
分析:一个暴力的思想是枚举g,然后枚举每个数ai,看能不能符合要求,这样复杂度是O(nA)的,直接T掉了.也没什么其他的办法了,在暴力的基础上优化一下,优化的关键是要如何快速统计出不满足要求的数的个数 ...
- 常州模拟赛d5t1 journalist
分析:出题人丧心病狂卡spfa......只能用dijkstar+堆优化. 主要的难点是字典序的处理上,一个想法是在做最短路的时候处理,边松弛边记录,比个大小记录最佳答案.具体的思路大概和最短路计数差 ...
- 常州模拟赛d4t3 字符串划分
题目描述 给你一串由小写字母组成的字符串,希望你把它划分成一些小段,使得每一小段字符串中的字母 都不相同,并且希望分的段数尽量少. 然后,把这些小段按字典序排序后输出,中间由一个空格分隔. 例如:字符 ...
- 常州模拟赛d4t2 陶陶摘苹果
题目描述 陶陶家的院子里有一棵苹果树,每到秋天树上就会结出 n 个苹果.苹果成熟的时候,陶陶就会 跑去摘苹果. 陶陶的手不能弯 (他仅能把手伸直),当且仅当陶陶达到的高度与苹果的高度相等的时候,陶陶 ...
- 常州模拟赛d3t3 两只怪物心心相印
题目背景 从前我是一位无名的旅人,旅途中我得到了某样东西:贤者之石.我因此得到悠久的时光和漂泊的生命.1897年冬天,我一时兴起舍弃了旅人的生活. 贤者之石创造出来的,是货真价实的黄金.我的名声传遍了 ...
- 常州模拟赛d3t2 灰狼呼唤着同胞
题目背景 我的母亲柯蒂丽亚,是一个舞者.身披罗纱,一身异国装扮的她,来自灰狼的村子. 曾经在灰狼村子担任女侍的她,被认定在某晚犯下可怕的罪行之后,被赶出了村子. 一切的元凶,都要回到母亲犯下重罪的那一 ...
随机推荐
- CSP201409-2:画图
引言:CSP(http://www.cspro.org/lead/application/ccf/login.jsp)是由中国计算机学会(CCF)发起的"计算机职业资格认证"考试, ...
- VBA基础之Excel 工作表(Sheet)的操作(二)
二. Excel 工作表(Sheet)的操作1. Excel 添加工作表(Sheet) 方法名 参数 参数值 说明 Add Before 工作表名称 在指定的工作表前面插入新的工作表 After 工作 ...
- es6从零学习(二):promise
es6从零学习(二):promise 一:promise的由来 某些情况下,回调嵌套很多时,代码就会非常繁琐,会给我们的编程带来很多的麻烦,这种情况俗称——回调地狱.由此,Promise的概念就由社区 ...
- css重修之书(一):如何用css制作比1px更细的边框
如何用css制作比1px更细的边框 在项目的开发过程中,我们常常会使用到border:1px solid xxx,来对元素添加边框: 可是1px的border看起来还是粗了一些粗,不美观,那么有什么方 ...
- jQuery实现仿京东商城图片放大镜
效果图: 不废话直接上代码: <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- 自测之Lesson10:管道
题目:建立双向管道,实现:父进程向子进程传送一个字符串,子进程对该字符串进行处理(小写字母转为大写字母)后再传回父进程. 实现代码: #include <stdio.h> #include ...
- 20145214 《Java程序设计》第7周学习总结
20145214 <Java程序设计>第7周学习总结 教材学习内容总结 时间的度量 格林威治标准时间(GMT),现已不作为标准时间使用,即使标注为GMT(格林威治时间),实际上谈到的的是U ...
- python执行linux命令的两种方法
python执行linux命令有两种方法: 在此以Linux常用的ls命令为例: 方法一:使用os模块 1 2 3 shell# python >> import os >> ...
- 第三次寒假作业 sketch 了解
什么是sketch? sketch 是一种基于散列的数据结构,可以在高速网络环境中,实时地存储流量特征信息,只占用较小的空间资源,并且具备在理论上可证明的估计精度与内存的平衡特性. 通过设置散列函数, ...
- iOS开发应用程序更新
#import "ViewController.h" //1一定要先配置自己项目在商店的APPID,配置完最好在真机上运行才能看到完全效果哦 #define STOREAPPID ...