Name Disambiguation in AMiner-Clustering, Maintenance, and Human in the Loop
1. 挑战
- 如何量化不同数据源中实体的相似性
- 可能没有重叠信息,需要设计一种量化规则
- 如何确定同名人数
- 现有方案通常预先指定
- 如何整合连续的数据
- 为确保作者经历,需要最小化作者职业生涯中的时间和文章间的间隔,保证其连续性
- 如何实现一个循环的系统
- 没有任何人为交互的消歧系统不够充实,利用人的反馈实现高的消歧准确性
2. 整体框架介绍

- 量化相似性
- 提出了一种结合全局度量和局部链接的学习算法,将每个实体投影到低维的公共空间,可直接计算其相似性
- 确定簇数
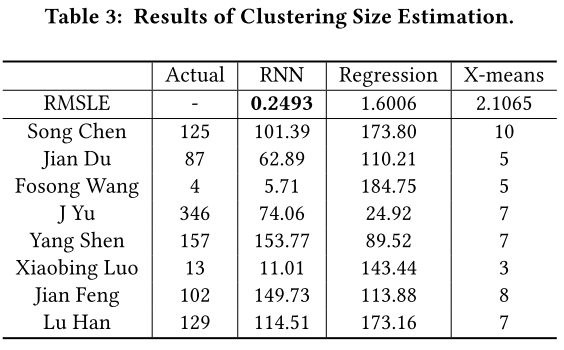
- 提出一种端到端的模型,使用递归神经网络直接估算簇数
- 结合人的参与
- 定义了来自用户/注释的6个潜在特征,将其结合到框架的不同组件中以改善消歧准确性
3. 相关研究
- 基于特征的方法
- 利用监督学习方法,基于文档特征向量学习每对文档间的距离函数
- Huang:首先使用块技术将具有相似名称的候选文档组合,然后通过 SVM 学习文档间距离,使用 DBSCAN 聚类文档
- Yoshida:提出两阶段聚类方法,在初次聚类后学习更好的特征
- Han:提出基于 SVM 和 Naive Bayes 的监督消歧方法
- Louppe:使用分类器学习每对的相似度并使用半监督层次聚类
- 基于链接的方法
- 利用来自邻居的拓扑和信息
- GHOST 仅通过共同作者构建文档图
- Tang 使用隐马尔科夫随机场模拟统一概率框架中的节点和边缘特征
- Zhang 通过基于文档相似度和共同作者关系从三个图中学习图嵌入
- 估计簇大小
- 之前为预设值
- 使用 DBSCAN 之类方法避免指定k
- 使用 X-means 变体基于贝叶斯信息准测测量聚类质量迭代估计最优 K
4. 参数设置
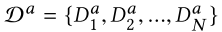
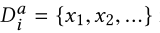
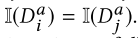

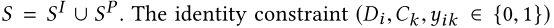

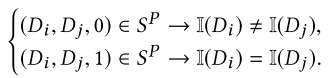
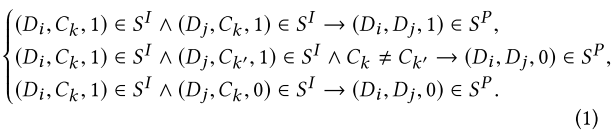
5. 框架
5.1. 表示学习
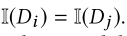
5.1.1. 全局度量学习

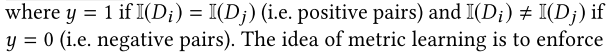

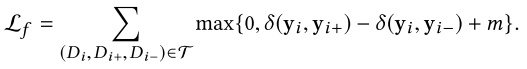
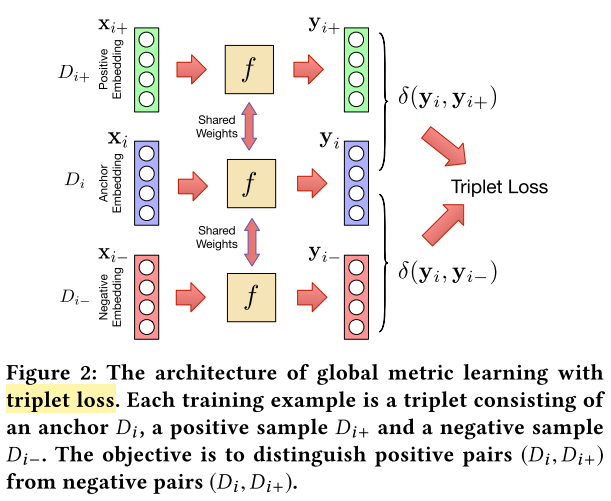
5.1.2. 本地链接学习



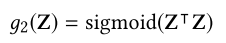
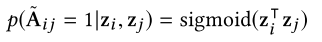
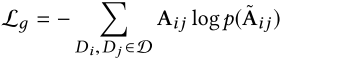
5.2. 簇估计
- 对每个第t步的训练,首先在[Kmin, Kmax] 间选取簇数 kt
- 从 C 中选取 Kt个集群构建伪候选集 Ct
- DCt:表示 C 中所有文档
- z: 表示固定样本大小
- 从DCt 中采样 z 个文档 Dt进行替换
- Dt 可能包含重复文档且 Dt 的顺序是任意的
- 通过此方式可从 C 中构建无数的训练集
- 使用一个神经网络框架使得 h(Dt)-->r
5.3. 连续集成
- 将新文档以下列方式贪婪的分配给现有的配置文件:
- 根据作者姓名和关联在系统中到排序搜索一组配置文件,每个配置文件对应一篇文章
- 如果有多个匹配,检索文档列表 Di 的全局嵌入 yi,并构建一个本地 KNN 分类器用于查找每个 Ck 的最佳分配
- 每一个 Ck 是一个类别, {(yi,}是一组带有标签的数据点
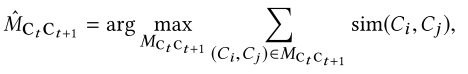
5.4. 利用人工注释
- 删除
- 删除文档
- 插入
- 将文档Di 添加到 Ck
- 拆分
- 注释为过度合并并请求聚类
- 合并
- 将 Ck 与 Ck‘ 合并
- 创建
- 确认
- 从Sp基于采样约束(Di,Dj,yij)
- 如果 yij = 0 则基于约束(Di,Dl,1)从 Sp 中采样,并生成三元组(Di,Dl,Dj)
- 否则,从整个文档空间中随机采样并生成三元组

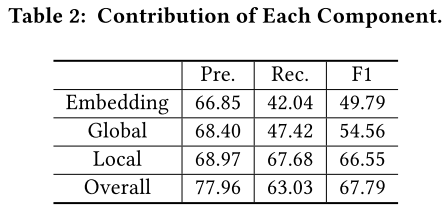
6. 效果

Name Disambiguation in AMiner-Clustering, Maintenance, and Human in the Loop的更多相关文章
- On-demand diverse path computation for limited visibility computer networks
In one embodiment, a source device detects a packet flow that meets criteria for multi-path forwardi ...
- CRM 价格批导
日了,好多代码....COPY别人的,懒得改了 *----------------------------------------------------------------------* *** ...
- AAAI |如何保证人工智能系统的准确性?
|如何保证人工智能系统的准确性?" title="AAAI |如何保证人工智能系统的准确性?"> 注:本文译自AI is getting smarter; ...
- 微软发布Microsoft Concept Graph和Microsoft Concept Tagging模型
Concept Graph和Microsoft Concept Tagging模型"> 当我们在讨论人工智能时,请注意,我们通常在讨论弱人工智能. 虽然我们现有的资源与之前可谓不同 ...
- 产品 线上 保持 和 支持 服务 (Support and maintenance solutions)
Maintenance and support are the key factors for the smooth functioning of ERP solutions. ERP mainten ...
- 漫谈 Clustering (2): k-medoids
上一次我们了解了一个最基本的 clustering 办法 k-means ,这次要说的 k-medoids 算法,其实从名字上就可以看出来,和 k-means 肯定是非常相似的.事实也确实如此,k-m ...
- 文献阅读 | Resetting histone modifications during human parental-to-zygotic transition
Resetting histone modifications during human parental-to-zygotic transition 人类亲本-合子转变中组蛋白修饰重编程 sci-h ...
- Bayesian Non-Exhaustive Classification A case study:online name disambiguation using temporal record streams
一 摘要: name entity disambiguation:将对应多个人的记录进行分组,使得每个组的记录对应一个人. 现有的方法多为批处理方式,需要将所有的记录输入给算法. 现实环境需要1:以o ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
随机推荐
- Android 解决setRequestedOrientation之后手机屏幕的旋转不触发onConfigurationChanged方法
最近在做播放器的时候遇到一个问题,在屏幕方向改变之后需要切换播放器全屏/非全屏的时候,在重写了onConfigurationChanged方法并在manifest.xml配置文件中添加 android ...
- BZOJ1858:[SCOI2010]序列操作——题解
https://www.lydsy.com/JudgeOnline/problem.php?id=1858 lxhgww最近收到了一个01序列,序列里面包含了n个数,这些数要么是0,要么是1,现在对于 ...
- 【Codeforces 506E】Mr.Kitayuta’s Gift&&【BZOJ 4214】黄昏下的礼物 dp转有限状态自动机+矩阵乘法优化
神题……胡乱讲述一下思维过程……首先,读懂题.然后,转化问题为构造一个长度为|T|+n的字符串,使其内含有T这个子序列.之后,想到一个简单的dp.由于是回文串,我们就增量构造半个回文串,设f(i,j, ...
- 【树状数组】【P3608】平衡的照片
传送门 Description FJ正在安排他的N头奶牛站成一排来拍照.(1<=N<=100,000)序列中的第i头奶牛的高度是h[i],且序列中所有的奶牛的身高都不同. 就像他的所有牛的 ...
- jq的$.each遍历数组
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- JavaScript中的函数与栈
Javascript中会经常用到setTimeout来推迟一个函数的执行,如: setTimeout(function(){ alert("Hello World"); },100 ...
- squid总结
squid可以完成的工作: 代理服务器 反向代理服务器 防火墙 缓存功能 透明代理 squid和varnish的对比,以及squid的优缺点说明: 缓存到硬盘,容易遇到I/O瓶颈 V3.2以下不支持多 ...
- 02.树的序列化与反序列化(C++)
1.二叉树的序列化 输入的一棵树: //二叉树的先序遍历-序列化 #include <iostream> #include <string> #include <sstr ...
- 002.比较vector对象是否相等
1.使用vector模板 //编写一段程序,比较vector对象是否相等 //注:该例类似于一个[彩票游戏] #include <iostream> #include <ctime& ...
- js中style,currentStyle和getComputedStyle的区别以及获取css操作方法
在js中,之前我们获取属性大多用的都是ele.style.border这种形式的方法,但是这种方法是有局限性的,该方法只能获取到行内样式,获取不了外部的样式.所以呢下面我就教大家获取外部样式的方法,因 ...