<tf-idf + 余弦相似度> 计算文章的相似度
.png)

.png)
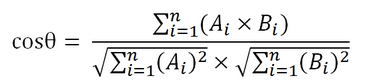
一般情况下,相似度都是归一化到[0,1]区间内,因此余弦相似度表示为cosineSIM=0.5cosθ+0.5
<tf-idf + 余弦相似度> 计算文章的相似度的更多相关文章
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- Python简单实现基于VSM的余弦相似度计算
在知识图谱构建阶段的实体对齐和属性值决策.判断一篇文章是否是你喜欢的文章.比较两篇文章的相似性等实例中,都涉及到了向量空间模型(Vector Space Model,简称VSM)和余弦相似度计算相关知 ...
- java算法(1)---余弦相似度计算字符串相似率
余弦相似度计算字符串相似率 功能需求:最近在做通过爬虫技术去爬取各大相关网站的新闻,储存到公司数据中.这里面就有一个技术点,就是如何保证你已爬取的新闻,再有相似的新闻 或者一样的新闻,那就不存储到数据 ...
- java文章标题及文章相似度计算hash算法实现
参看了 https://github.com/awnuxkjy/recommend-system 对方用了 余弦 函数实现相似度计算,我则用的是 hanlp+hash 算法(Hash算法总结) 再看服 ...
- 两矩阵各向量余弦相似度计算操作向量化.md
余弦相似度计算: \cos(\bf{v_1}, \bf{v_2}) = \frac{\left( v_1 \times v_2 \right)}{||v_1|| * ||v_2|| } \cos(\b ...
- Spark Mllib里相似度度量(基于余弦相似度计算不同用户之间相似性)(图文详解)
不多说,直接上干货! 常见的推荐算法 1.基于关系规则的推荐 2.基于内容的推荐 3.人口统计式的推荐 4.协调过滤式的推荐 协调过滤算法,是一种基于群体用户或者物品的典型推荐算法,也是目前常用的推荐 ...
- 转:Python 文本挖掘:使用gensim进行文本相似度计算
Python使用gensim进行文本相似度计算 转于:http://rzcoding.blog.163.com/blog/static/2222810172013101895642665/ 在文本处理 ...
- 使用 TF-IDF 加权的空间向量模型实现句子相似度计算
使用 TF-IDF 加权的空间向量模型实现句子相似度计算 字符匹配层次计算句子相似度 计算两个句子相似度的算法有很多种,但是对于从未了解过这方面算法的人来说,可能最容易想到的就是使用字符串匹配相关的算 ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
随机推荐
- Python 一行代码实现并行
需求 给定一个list 针对list 中每个元素执行一定的操作(这个操作很费时间,例如爬数据的时候调用某个网站的接口),返回操作后的list 例如 给定 1-10个数,在每个数字后面加个字母a 方 ...
- 利用TokyoTyrant构建兼容Memcached协议、支持故障转移、高并发的分布式Key-value持久存储系统(转)
Tokyo Cabinet 是日本人 平林幹雄 开发的一款 DBM 数据库,该数据库读写非常快,哈希模式写入100万条数据只需0.643秒,读取100万条数据只需0.773秒,是 Berkeley D ...
- SVN插件下载地址及更新地址
SVN插件下载地址及更新地址,你根据需要选择你需要的版本.现在最新是1.8.xLinks for 1.8.x Release:Eclipse update site URL: http://subcl ...
- 每天学点Linux命令之grep 和 wc命令 ---(6/25)
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来.grep全称是Global Regular Expression Print,表示全局正则表达 ...
- ajax 事件使用
error: function (XMLHttpRequest, textStatus, errorThrown) { alert(XMLHttpRequest.status); alert(XMLH ...
- 数字图像处理,图像锐化算法的C++实现
http://blog.csdn.net/ebowtang/article/details/38961399 之前一段我们提到的算法都是和平滑有关, 经过平滑算法之后, 图像锐度降低, 降低到一定程度 ...
- 重置root密码后仍然不能登陆
一.忘记密码:二.输入正确用户名和密码时依旧无法登录. 一.忘记密码 进入单用户模式重置密码: 开机启动时,按‘E’键(倒计时结束前)进入界面 选择第二项,按‘E’键再次进入 在最后一行添加‘ 1’( ...
- c++的格式控制
1: 每个iostream对象维持一个控制IO格式化细节的格式状态.标准库定义了一组操纵符来修改对象的格式状态.所谓操纵符是可用作输入或输出操作符的函数或对象.iostream和iomanip头文件中 ...
- redis_入门网址
redis中文网: http://www.redis.cn/ 可以 试用 以及 下载 redis百度百科:http://baike.baidu.com/link?url=MEkE5MpGAOfJ7ci ...
- 做Webservice时报错java.util.List是接口, 而 JAXB 无法处理接口。
Caused by: com.sun.xml.bind.v2.runtime.IllegalAnnotationsException: 1 counts of IllegalAnnotationExc ...