Sql排名和分组排名
在很多时候,都有排名这个功能,比如排行榜,并且还需要分页的功能,一般可以再select的时候按照某一字段 oorder by XX desc,这样limit 查找就可以得到排名信息,但是有时候是需要多表连接,或者是有一个随机查看,在页面上并不是按照排名升降序。这个时候就需要用SQL来实现排名。
先准备测试数据:
Table:
CREATE TABLE `test` (
`Score` int(255) NOT NULL,
`Name` varchar(255) NOT NULL,
`Type` varchar(255) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of test
-- ----------------------------
INSERT INTO `test` VALUES ('', '张三', '数学');
INSERT INTO `test` VALUES ('', '张三', '语文');
INSERT INTO `test` VALUES ('', '张三', '英语');
INSERT INTO `test` VALUES ('', '李四', '数学');
INSERT INTO `test` VALUES ('', '李四', '语文');
INSERT INTO `test` VALUES ('', '李四', '英语');
INSERT INTO `test` VALUES ('', '王五', '数学');
INSERT INTO `test` VALUES ('', '王五', '语文');

如果要查询数学科目的排名,可以用以下sql语句:
select a.*,@a := @a+1 as rank from test a,(select @a:=0) b where type=' 数学 ' order by a.score desc;
结果如下:
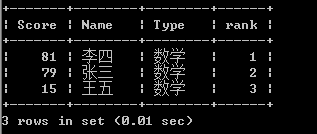
也就是使用a变量,按照order by的顺序递增。这个很好理解,但是如果有分组排序的需求呢?
例如在Test表中,要用一条sql查出数学、语文、英语三个科目各自的排名呢?
首先可以想到方法还是类似查询单科排名,先将所有记录按照科目、得分排序,Order by Type,Score。然后自定义变量递增,但是关键就在于需要判断科目的记录有多少条,也即自定义变量归零重新递增的临界点。
简单排名使用一个变量a,那么在分组排序中可以考虑使用两个变量,a、b
先执行如下sql
select a.* from test a order by type,score;
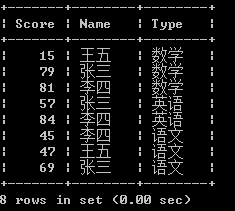
现在加上排名,先使用一个变量看得到什么效果:
select a.*,(@a := @a + 1) as rank from test a,(select @a := 0) b order by type,score;
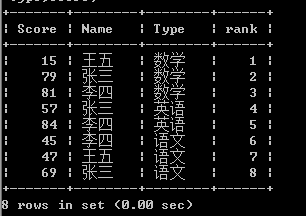
现在排名并没有按照科目的不同重新计算,我们只要解决排名何时归0,就可以得到分组排序的结果了。
再加一个中间变量nowType试试?让这个中间变量nowType等于Type(科目),只要下一条记录与这个中间变量nowType相等,rank就加1,不相等的话,rank就归零,来看下这条SQL:
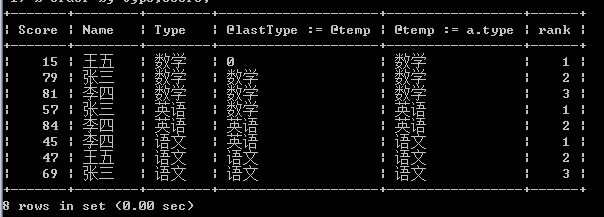
select a.*,@lastType := @nowType,@ nowType:= a.type,if(@lastType = @nowType,@rank := @rank + 1,@rank := 0) as rank from test a,(select @a := 0,@ nowType:= 0,@rank := 0) b order by type,score;
现在看来是不是比较简单了,lastType用于记录上一条记录的Type,nowType是当前记录的Type,只要nowType=lastType,就说明是同一科目,rank加+,反之,rank归零。
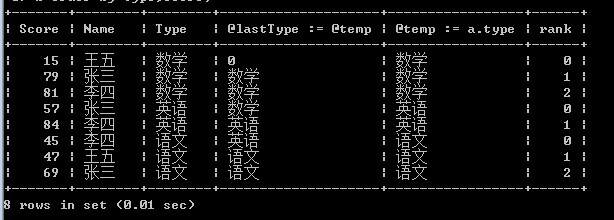
但是我们看到同样是将rank初始化为0,为什么上面是从1开始,而这次是从0开始呢?再分析下sql,在第一条记录的时候,lastType=0.而nowType=数学,肯定不相等,所以输出0,rank从0开始,只要将rank初始化为1就好了。
select a.*,@lastType := @temp,@temp := a.type,if(@lastType = @temp,@rank := @rank + 1,@rank := 1) as rank from test a,(select @a := 0,@temp := 0,@rank := 0) b order by type,score;
Sql排名和分组排名的更多相关文章
- SQL Server 分析函数和排名函数
分析函数基于分组,计算分组内数据的聚合值,经常会和窗口函数OVER()一起使用,使用分析函数可以很方便地计算同比和环比,获得中位数,获得分组的最大值和最小值.分析函数和聚合函数不同,不需要GROUP ...
- MySQL 排名、分组后组内排名、取各组的前几名 及排名后更新插入数据表中
一.排名 /*普通排名:从1开始,顺序往下排*/ AS rank ) r ORDER BY score; /*并列排名:相同的值是相同的排名*/ SELECT cs.* , CASE WHEN @p= ...
- MySQL 排名、分组后组内排名、取各组的前几名
一.排名 /*普通排名:从1开始,顺序往下排*/ AS rank ) r ORDER BY score; /*并列排名:相同的值是相同的排名*/ SELECT cs.* , CASE WHEN @p= ...
- sql server 中用于排名的三个函数 row_number() ,RANK() 和 DENSE_RANK()
row_number() ,RANK() 和 DENSE_RANK() 三个配合over() 使用排名 只是只是计算方式不一样,语法基本一样 语法: ROW_NUMBER() OVER (OR ...
- sql按天分组
sql按天分组,这都不会 晕!!!!!!! ) ;
- SQL Server温故系列(5):SQL 查询之分组查询 GROUP BY
1.GROUP BY 与聚合函数 2.GROUP BY 与 HAVING 3.GROUP BY 扩展分组 3.1.GROUP BY ROLLUP 3.2.GROUP BY CUBE 3.3.GROUP ...
- [MSSQL]SQL疑难杂症实战记录-巧妙利用PARTITION分组排名递增特性解决合并连续相同数据行
问题提出 先造一些测试数据以说明题目: DECLARE @TestData TABLE(ID INT,Col1 VARCHAR(20),Col2 VARCHAR(20)) INSERT INTO @T ...
- ROWNUMBER() OVER( PARTITION BY COL1 ORDER BY COL2)用法,先分组,然后在组内排名,分组计算,主表与附表一对多取唯一等
ROWNUMBER() OVER( PARTITION BY COL1 ORDER BY COL2)用法 今天在使用多字段去重时,由于某些字段有多种可能性,只需根据部分字段进行去重,在网上看到了row ...
- SQL Server排名函数与排名开窗函数
什么是排名函数?说实话我也不甚清楚,我知道 order by 是排序用的,那么什么又是排名函数呢? 接下来看几个示例就明白了. 首先建立一个表,随便插入一些数据. ROW_NUMBER 函数:直接排序 ...
随机推荐
- Android虚拟机GenyMotion-- 遇到的问题
问题: android studio 检测不到 genymotion 原因:没有设置genymotion的adb,也就是sdk的路径. 解决方法:打开genymotion的主页面,设置sdk的位置为你 ...
- OC中的单例设计模式及单例的宏抽取
// 在一个对象需要重复使用,并且很频繁时,可以对对象使用单例设计模式 // 单例的设计其实就是多alloc内部的allocWithZone下手,重写该方法 #pragma Person.h文件 #i ...
- Visual Studio 2010 单元测试目录
单元测试的重要性这里我就不多说了,以前大家一直使用NUnit来进行单元测试,其实早在Visual Studio 2005里面,微软就已经集成了一个叫Test的专门测试插件,经过几年的发展,这个工具现在 ...
- C++ 性能剖析 (三):Heap Object对比 Stack (auto) Object
通常认为,性能的改进是90 ~ 10 规则, 即10%的代码要对90%的性能问题负责.做过大型软件工程的程序员一般都知道这个概念. 然而对于软件工程师来说,有些性能问题是不可原谅的,无论它们属于10% ...
- 【USACO 1.5.4】跳棋的挑战
[问题描述] 检查一个如下的6 x 6的跳棋棋盘,有六个棋子被放置在棋盘上,使得每行,每列,每条对角线(包括两条主对角线的所有对角线)上都至多有一个棋子,如下例,就是一种正确的布局. 上面的布局可以用 ...
- jdk-动态代理
1.HelloWorld package reflect.proxy; public interface HelloWorld { void print(); } 2.HelloWorldImpl p ...
- Python自动化运维之16、线程、进程、协程、queue队列
一.线程 1.什么是线程 线程是操作系统能够进行运算调度的最小单位.它被包含在进程之中,是进程中的实际运作单位. 一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行 ...
- linux内核移植 I
根据tx2440的文档, 目标也比较简单, 先编译成功, 再烧录, 根文件系统, busybox 这些. A. 准备 1. 解压tar, 修改根Makefile ARCH ?= arm CROSS_C ...
- WinDebug 常用命令表【摘】
启动, 附加进程, 执行和退出(Starting, Attaching, Executing and Exiting) ======================= Start -> All ...
- XML SAX解析
SAX是一种占用内存少且解析速度快的解析器,它采用的是事件驱动,它不需要解析完整个文档,而是按照内容顺序,看文档某个部分是否符合xml语法,如果符合就触发相应的事件.所谓的事件就是些回调方法( cal ...