JindoFS解析 - 云上大数据高性能数据湖存储方案
JindoFS背景
计算存储分离是云计算的一种发展趋势,传统的计算存储相互融合的的架构存在一定的问题, 比如在集群扩容的时候存在计算能力和存储能力相互不匹配的问题,用户在某些情况下只需要扩容计算能力或者存储能力,传统的融合架构不能单独的扩充计算或者存储能力, 而计算存储分离可以很好的解决这个问题,用户只需要关心整个集群的计算能力。
基于OSS 计算存储分离
EMR 现有的计算存储分离方案是基于OSS提供兼容Hadoop文件系统的OssFS, 用户通过OssFS 可以访问OSS 上的数据, 因此OssFS 保留了OSS的一些优势,比如提供海量存储,成本低,高可靠等,同时也存在一些问题比如文件重命名操作慢, OSS 带宽限制,高频访问的数据消耗过多的OSS带宽。而JindoFS 除了可以保留上述OssFS的优势,还克服上述OssFS的问题。
JindoFS 介绍
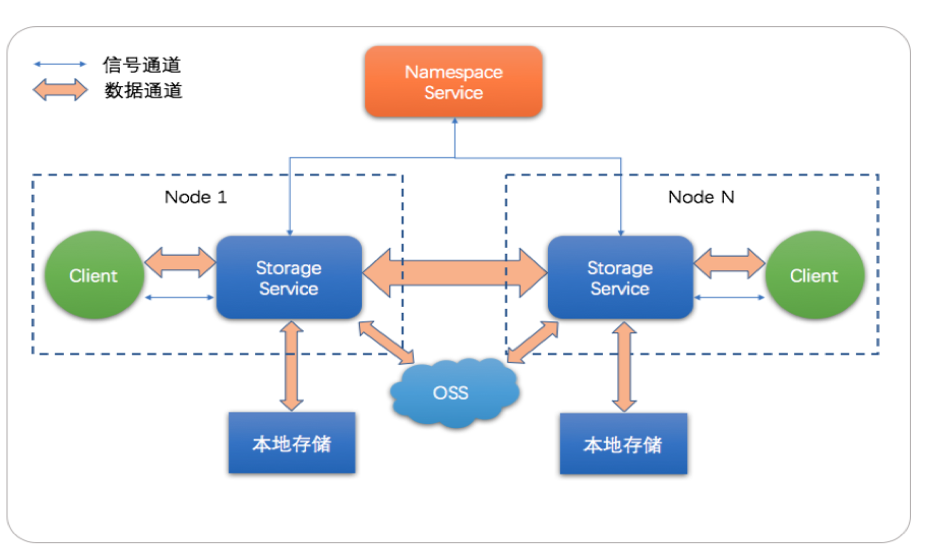
JindoFS 主要包含两个服务组件:Namespace的服务以及Storage 服务,Namespace服务主要JindoFS 元数据管理以及 Storage 服务的管理, Storage 服务主要负责 用户数据的管理包含本地数据的管理和OSS上数据的管理, JindoFS是云原生的文件系统,可以提供本地存储的性能以及OSS的超大容量。下面我们分别介绍下这两个服务的主要功能。
Namespace 主要用来管理用户的元数据,这部分元数据包含JindoFS 文件系统的元数据, Block 的元数据以及 Storage 服务的元数据,JindoFS Namespace服务可以在单个集群上支持不同的Namespace, 用户可以根据不同的业务划分不同的Namespace,不同的Namespace存放不同业务数据。 此外Namespace可以设置不同存储后端现阶段主要支持RocksDB,OTS的支持预计在下个版本发布,针对Namespace的性能我们支持大量的优化,比如支持目录级别的并发控制,元数据的缓存等等。
Storage 服务主要负责实际的数据管理,本地缓存的数据管理以及OSS数据管理,可以支持不同的存储后端以及存储介质,存储后端现阶段主要支持本地文件系统以及OSS, 本地存储系统可以支持HDD/SSD/DCPM等存储介质,用以提供缓存加速,另外Storage 服务针对用户的小文件较多的场景进行优化,避免过多的小文件给本地文件系统带来过大的压力造成整体性能的下降。
此外在整个生态方面,JindoFS 支持EMR 框架的所有计算引擎,包括Hadoop, Hive, Spark, Flink, Impala, Presto 以及 HBase, 用户只要替换文件访问路径的模式为jfs就可以使用JindoFS,另外在机器学习方面下个版本JindoFS将会推出Python SDK, 方便机器学习用户可以高效率的访问JindoFS上的数据,另外JindoFS 与 EMR Spark高度集成优化,支持基于Spark的物化视图以及Cube的优化,实现秒级Adhoc的分析
JindoFS 使用模式
JindoFS Block模式
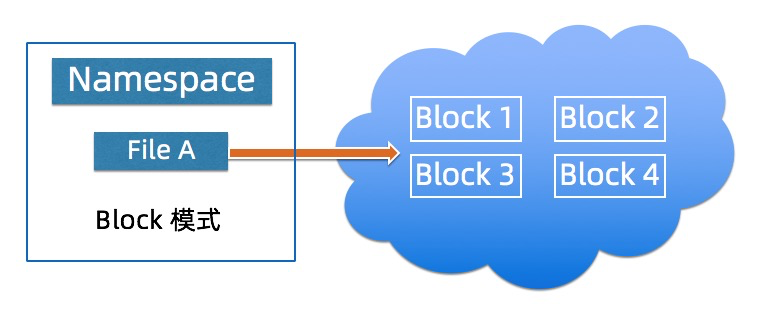
Block模式将JindoFS的文件切分的Block的形式存放本地磁盘以及OSS上,用户通过OSS 只能看到Block的数据,本地的Namespace服务负责管理元数据,通过本地元数据以及Block数据构建出文件数据,该模式相对与后一种模式该模式下JindoFS的性能是最佳的, Block模式适用用户对数据以及元数据都有一定的性能要求的场景,Block模式需要用户将数据迁移到JindoFS。
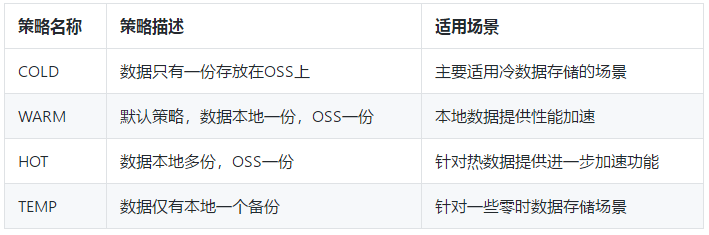
Block模式为用户提供不同的存储策略适配用户不同的应用场景
对比HDFS, JindoFS的Block 模式提供以下优势:
- 利用OSS 的廉价和无限容量 JindoFS 提可以 OSS 优势成本以及容量的优势
- 冷热数据自动分离,计算透明,冷热数据自动迁移的时候逻辑位置不变,无须修改表元数据 location 信息
- 维护简单,无须 decommission,节点坏掉或者下掉就去掉,数据 OSS 上有,不会丢失
- 系统快速升级/重启/恢复,没有 block report
- 原生支持小文件,避免小文件过程造成文件系统过大的压力
JindoFS Cache模式
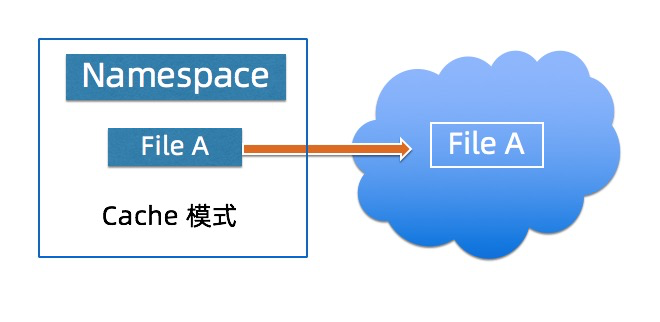
Cache模式将JindoFS文件以对象的形式存在OSS,用户可以通过OSS 看到原有的目录结构以及文件,该模式提供数据以及元数据的缓存加速用户的读写数据的性能,该模式下用户无需迁移数据到OSS,但是性能相对Block模式有一定的性能损失。 在元数据同步方面用户可以根据不同的需求选择不同的元数据同步策略。
对比OssFS, JindoFS的Cache模式提供以下优势:
- 由于本地备份存在,读写吞吐与HDFS相当
- 能够支持全部 HDFS 接口, 支持更多的场景,如Delta Lake,支持 HBase on JindoFS
- JindoFS作为数据以及元数据的缓存, 用户在读写数据以及List/Status操作相对OssFS有性能提升
- JindoFS作为数据缓存, 可以加速用户的数据读写
JindoFS 外部客户端
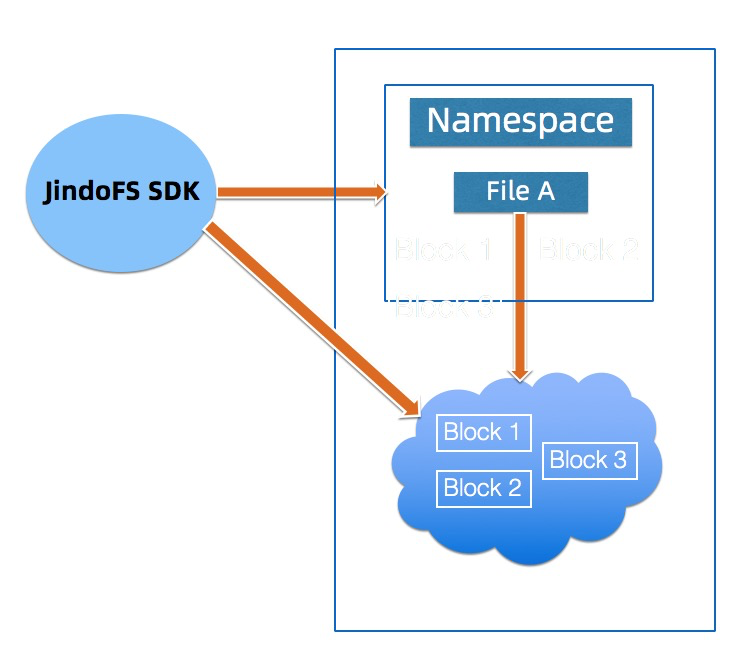
外部客户端提供用户在EMR 集群外访问 JindoFS的一种方式,现阶段该客户端只支持JindoFS的Block模式,客户端的权限与OSS 权限绑定,用户需要有相应OSS的权限才能够通过外部客户端访问JindoFS的数据。
JindoFS + DCPM 性能
测试环境

性能
下面主要JindoFS + DCPM的性能,测试主要分为三部分:Micro-benchmark, TPC-DS查询在JindoFS上的性能以及 SSB在Spark Relational Cache + JindoFS 上的性能。 其中DCPM 为Intel 傲腾数据中心级可持久化内存。
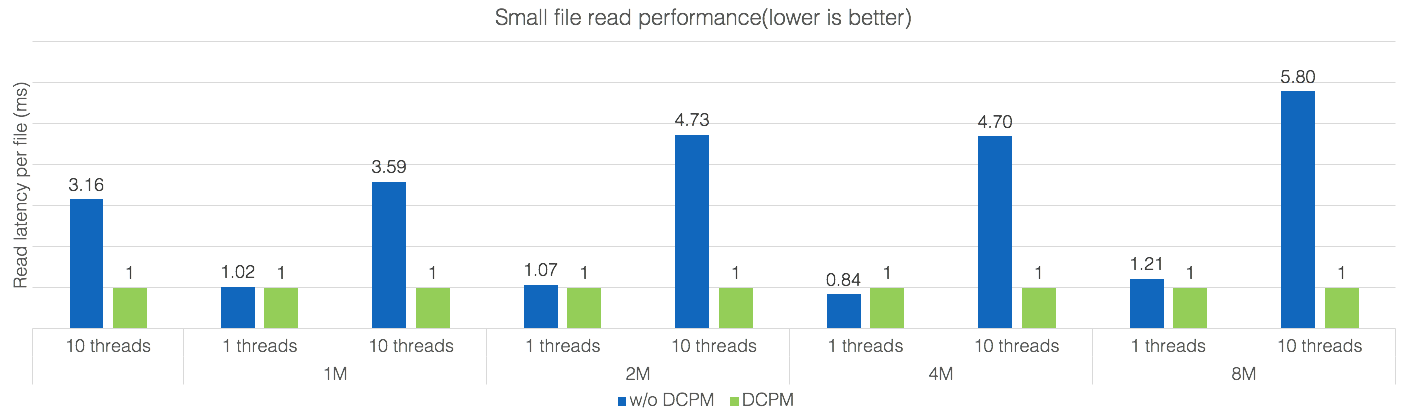
上图为Micro-benchmark的性能,主要测试了不同文件大小( 512K, 1M, 2M, 4M and 8M )和不同并行度(1-10)下的100个小文件读操作,从图中可以看出DCPM为小文件读带来了性能的显著提高,文件越大,并行度越高,性能提升的也更明显。
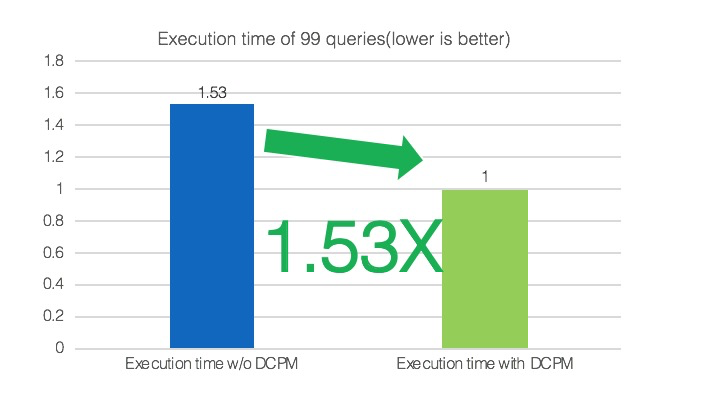
上图TPC-DS的测试结果,TPC-DS数据量为2TB,测试整个TPC-DS的99个查询。基于归一化时间,DCPM总体上带来了1.53倍的性能提升。

上图SSB在Spark Relational Cache + JindoFS 测试结果,其中SSB( 星型基准测试 )是基于TPC-H的针对星型数据库系统性能的测试基准。Relational Cache是EMR Spark支持的一个重要特性,主要通过对数据进行预组织和预计算加速数据分析,提供了类似传统数据仓库物化视图的功能。 在SSB测试中,使用1TB数据来单独执行每个查询,并在每个查询之间清除系统cache。基于归一化时间,总体上DCPM 能带来2.7倍的性能提升。对于单个query,性能提升在1.9倍至3.4倍。
作者介绍:殳鑫鑫,花名辰石,阿里巴巴计算平台事业部EMR团队技术专家,目前从事大数据存储以及Spark相关方面的工作。
阿里云双11领亿元补贴,拼手气抽iPhone 11 Pro、卫衣等好礼,点此参与:http://t.cn/Ai1hLLJT
本文作者:殳鑫鑫
本文为云栖社区原创内容,未经允许不得转载。
JindoFS解析 - 云上大数据高性能数据湖存储方案的更多相关文章
- Lambda plus: 云上大数据解决方案
本文会简述大数据分析场景需要解决的技术挑战,讨论目前主流大数据架构模式及其发展.最后我们将介绍如何结合云上存储.计算组件,实现更优的通用大数据架构模式,以及该模式可以涵盖的典型数据处理场景. 大数据处 ...
- Quick BI助力云上大数据分析---深圳云栖大会
在3月29日深圳云栖大会的数据分析与可视化专场中,阿里云产品专家陌停对大数据智能分析产品 Quick BI 进行了深入的剖析.大会现场的精彩分享也赢得观众们的一直认可和热烈的反响. 大数据分析之路的挑 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 巨杉数据库数据高性能数据导入迁移实践
SequoiaDB 一款自研金融级分布式数据库产品,支持标准SQL和分布式事务功能.支持复杂索引查询,兼容 MySQL.PGSQL.SparkSQL等SQL访问方式.SequoiaDB 在分布式存储功 ...
- k8s 开船记-故障公告:自建 k8s 集群在阿里云上大翻船
非常非常抱歉,新年上班第一天, 在今天阿里云上气候突变情况下,由于我们开船技术差,在今天 10:15~12:00 左右的访问高峰,我们竟然把船给开翻了,造成近2个小时整个博客站点无法访问,由此给您带来 ...
- 一文读懂云上DevOps能力体系
简介: 阿里云ECS自动化运维套件架构师,深度拆解云上运维能力体系建设:自动化运维等级金字塔.自动化运维的进阶模式.DevOps的基础核心.云上标准化部署三大能力-- 序言 云计算行业已经有十多年的发 ...
- 手把手教你:将 ClickHouse 集群迁至云上
前言 随着云上 ClickHouse 服务完善,越来越多的用户将自建 ClickHouse 服务迁移至云上.对于不同数据规模,我们选择不同的方案: 对于数据量比较小的表,通常小于10GB 情况下,可以 ...
- 腾讯云EMR大数据实时OLAP分析案例解析
OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值.本文基于QQ音乐海量大数据实时分析场景,通过QQ音乐与腾 ...
- 一面数据: Hadoop 迁移云上架构设计与实践
背景 一面数据创立于 2014 年,是一家领先的数据智能解决方案提供商,通过解读来自电商平台和社交媒体渠道的海量数据,提供实时.全面的数据洞察.长期服务全球快消巨头(宝洁.联合利华.玛氏等),获得行业 ...
- HP PCS 云监控大数据解决方案
——把数据从分散统一集中到数据中心 基于HP分布式并行计算/存储技术构建的云监控系统即是通过“云高清摄像机”及IaaS和PaaS监控系统平台,根据用户所需(SaaS)将多路监控数据流传送给“云端”,除 ...
随机推荐
- python之字符串切分
在工作中,经常遇到字符串切分,尤其是操作linux命令,返回一段文本,如下面这种格式 Filesystem Size Used Avail Use% Mounted on /dev/vda1 40G ...
- spring-cloud:Hystrix熔断的使用示例
1.运行环境 开发工具:intellij idea JDK版本:1.8 项目管理工具:Maven 4.0.0 2.GITHUB地址 https://github.com/nbfujx/springCl ...
- SQL注入的简单认识
写在前面 MYSQL5.0之后的版本,默认在数据库中存放一个information_schema的数据库,其中应该记住里面的三个表SCHEMATA.TABLES.COLUMNS SCHEMATA表:存 ...
- crontab不能正常执行的五种原因
1 crond服务未启动 crontab不是Linux内核的功能,而是依赖一个crond服务,这个服务可以启动当然也可以停止.如果停止了就无法执行任何定时任务了,解决的方法是打开它: crond 或 ...
- iview+vue 表格中添加图片
开门见山,话不多说,要在表格中添加图片,可以使用td: <table " width="100%"> <tr class="tr-style ...
- 嵌入式C语言3.4 关键字---类型描述符auto/register/static/const/extern/volatile/
对内存资源存放位置的限定 1. auto 默认值---分配的内存都是可读可写的区域 auto int a; 区域如果出现 {} 我们认为在栈空间 2. register register int a; ...
- checkBox的全选与全不选
//初始加载 $(function () { LoadCart(); }); var RMB = 0; var Index = 0; var shu = 0; var ResultStr = &q ...
- centos7下查看cup核数
centos7下查看cup核数 # 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 # 查看物理CPU个数cat ...
- k8s 组件介绍-API Server
API Server简介 k8s API Server提供了k8s各类资源对象(pod,RC,Service等)的增删改查及watch等HTTP Rest接口,是整个系统的数据总线和数据中心. kub ...
- [FW]修复ubutnu12.04+win7的grub2引导
[转]修复ubutnu12.04+win7的grub2引导 原文位置:http://wenku.baidu.com/view/b6b7c9926bec0975f465e2f8.html ps:我使用的 ...