机器学习实战笔记-5-Logistic回归
Logistic回归
| 优缺点 | 适用范围 |
|---|---|
| 优点:计算代价不高,易于理解和实现。 缺点:容易欠拟合,分类精度可能不高。 适用于:数值型和标称型数据。 | 仅用于二分类 |
原理:
每个特征都乘以一个回归系数>>将结果相加>>总和代入到Sigmoid函数,得到范围在(0,1)中的数值>>预测分类结果\(\hat{y}\)。即\(Z= w_{0}x_{0} + w_{1}x_{1} + \ldots + w_{n}x_{n} = \sum_{i = 0}^{n}{w_{i}x_{i} =w^{T}x}\),代入Sigmoid函数即可。
两个类别的分割点是\(Z=0\),即直线\(w_{0}x_{0}+w_{1}x_{1}+\ldots +w_{n}x_{n}=0\)。
\]
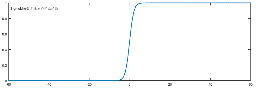
若用\(y’\)表示分类为1的概率,\(P\left( y = 1 \middle| x,w \right) =
y'\),则分类为0的概率为\(P\left( y = 0 \middle| x,w \right) = 1 - y'\)。
极大似然概率为\(L\left( w \right) = \prod_{i =
1}^{m}{ { {(y}_{i}^{'})}^{y_{i} }\left( 1 - y_{i}^{'} \right)^{1 - y_{i} } }\),
取对数后为\(\mathbf{l}\left( \mathbf{w} \right)\mathbf{=}\sum_{\mathbf{i =
1} }^{\mathbf{m} }{\mathbf{(}\mathbf{y}_{\mathbf{i} }\log\left(
\mathbf{y}^{\mathbf{'} } \right)\mathbf{+ (1
-}\mathbf{y}_{\mathbf{i} }\mathbf{)log(1
-}\mathbf{y}_{\mathbf{i} }^{\mathbf{'} }\mathbf{)} }\mathbf{)}\),迭代式为
\(\mathbf{w}_{\mathbf{j} }\mathbf{: =}\mathbf{w}_{\mathbf{j} }\mathbf{+
\alpha}\frac{\mathbf{\partial} }{\mathbf{\partial}\mathbf{w}_{\mathbf{j} } }\mathbf{l(w)}\)
\]
\]
其中用到了 记\(f\left( x \right) = \frac{1}{1 +
e^{g(x)} }\),则\(\frac{\partial}{\partial x}f\left( x \right) = f\left( x
\right)\left( 1 - f\left( x \right) \right)\frac{\partial}{\partial x}g(x)\)
现有一数据集trainMat,记作矩阵X,则\(error = \mathbf{\text{labelMat} } -
\sigma(\mathbf{X} \times \mathbf{w})\)为预测值与实际值的差。
极大似然概率就是要回归的最大值\(l(w)\),并不在代码中体现,迭代式为
\]
\]
梯度上升算法伪代码:
每个回归系数初始化为1
重复R次
计算整个数据集的梯度
使用alpha×gradient更新回归系数的向量
返回回归系数
随机梯度上升算法伪代码:
每个回归系数初始化为1
对数据集中每个样本
计算该样本的梯度
使用alpha×gradient更新回归系数的值
返回回归系数值
知识点:最大似然估计法-本质就是求联合概率的最大值
二项分布的似然函数(某次实验:投n次硬币有m次正面)
\]
二项分布用通俗点的话来说,就是描述了抛10次硬币的结果的概率,其中,“花”出现的概率为\(\theta\)。如{4,5,5,2,7,4}就是6次实验的结果,每个数字表示抛10次硬币出现了几次“花”。
用\(x_{1},x_{2},\ldots,x_{n}\)表示实验结果,则因为每次实验都是独立的,所以似然函数可以写作(得到这个似然函数很简单,独立事件的联合概率,直接相乘就可以得到):
\]
其中\(f\left( x_{n} \middle| \theta\right)\)表示同一参数下的实验结果,也可认为是条件概率。
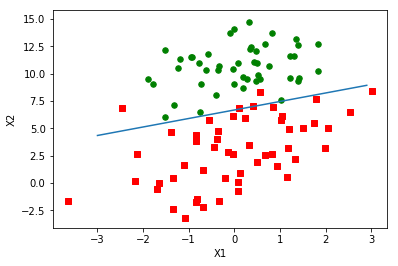
用python画的图
机器学习实战笔记-5-Logistic回归的更多相关文章
- 机器学习实战笔记5(logistic回归)
1:简单概念描写叙述 如果如今有一些数据点,我们用一条直线对这些点进行拟合(改线称为最佳拟合直线),这个拟合过程就称为回归.训练分类器就是为了寻找最佳拟合參数,使用的是最优化算法. 基于sigmoid ...
- 《机器学习实战》-逻辑(Logistic)回归
目录 Logistic 回归 本章内容 回归算法 Logistic 回归的一般过程 Logistic的优缺点 基于 Logistic 回归和 Sigmoid 函数的分类 Sigmoid 函数 Logi ...
- 机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归
机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归 关键字:Logistic回归.python.源码解析.测试作者:米仓山下时间:2018- ...
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
- 机器学习实战 - 读书笔记(05) - Logistic回归
解释 Logistic回归用于寻找最优化算法. 最优化算法可以解决最XX问题,比如如何在最短时间内从A点到达B点?如何投入最少工作量却获得最大的效益?如何设计发动机使得油耗最少而功率最大? 我们可以看 ...
- 机器学习实战读书笔记(五)Logistic回归
Logistic回归的一般过程 1.收集数据:采用任意方法收集 2.准备数据:由于需要进行距离计算,因此要求数据类型为数值型.另外,结构化数据格式则最佳 3.分析数据:采用任意方法对数据进行分析 4. ...
- 机器学习实战笔记(Python实现)-04-Logistic回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-08-线性回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-09-树回归
---------------------------------------------------------------------------------------- 本系列文章为<机 ...
随机推荐
- Codeforces 1163D Mysterious Code(AC自动机+DP)
用 AC自动机 来做有点想不到,捞一手就是学一手. 设 dp[ i ][ j ] 表示字符串 c 中的第 i 位到字典树上节点 j 的最大值是多少, word[ j ] 表示在节点 j 下对答案修改的 ...
- 【题解】1-2-K Game
题目大意 现有\(n\)个东西,每次可以取\(1\)个,\(2\)个或\(k\)个.Alice和Bob轮流取,且Alice先取.问谁是最后一个取的.(\(0 \leq n \leq 10^9\), ...
- Java 异步编程
昨天头儿给的学习文档我还没看完,头儿说:“MongoDB光会简单的添删改查什么的不行,要深入了解,你们连$set和$inc使用场景都分不清.” 确实,学习过一年多SQL,确实对学习MongoDB有点影 ...
- 修复线上bug
1,git branch new_branch 2,git push origin new_branch 以上是线上地址操作,以下是本地仓库操作 3,git fetch 4,git checkout ...
- PC端实现浏览器点击分享到QQ好友,空间,微信,微博等
网上现在比较流行的是JIaThis,但是测试的时候,不能分享给QQ好友,一直卡在输入验证码,以下代码亲测有效,可直接使用 <%@ page language="java" c ...
- 实现斐波那契数列之es5、es6
es5实现斐波拉契函数数列: <script type="text/javascript"> function fibonacci(n) { var one = 1; ...
- vue中搜索关键词,使文本标红
UserHead.vue中搜索框: <!-- 搜索 --> <el-col :span="6" :offset="8" class=" ...
- jpype测试报错,找不到类raise _RUNTIMEEXCEPTION.PYEXC("Class %s not found" % name)
最近用jpype测试java代码 公司电脑跑着没有问题,家里电脑怎么也不行,python,jdk版本啥的都一样,但总是报找不到类名的错误 raise _RUNTIMEEXCEPTION.PYEXC(& ...
- Redis复制实现原理
摘要 我的前一篇文章<Redis 复制原理及特性>已经介绍了Redis复制相关特性,这篇文章主要在理解Redis复制相关源码的基础之上介绍Redis复制的实现原理. Redis复制实现原理 ...
- bzoj3123 [Sdoi2013]森林 树上主席树+启发式合并
题目传送门 https://lydsy.com/JudgeOnline/problem.php?id=3123 题解 如果是静态的查询操作,那么就是直接树上主席树的板子. 但是我们现在有了一个连接两棵 ...