Linux性能优化从入门到实战:08 内存篇:内存基础
内存主要用来存储系统和应用程序的指令、数据、缓存等。
内存映射
物理内存也称为主存,动态随机访问内存(DRAM)。只有内核才可以直接访问物理内存。
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样,进程就可以很方便地访问内存,更确切地说是访问虚拟内存。虚拟地址空间的内部又被分为内核空间和用户空间两部分。
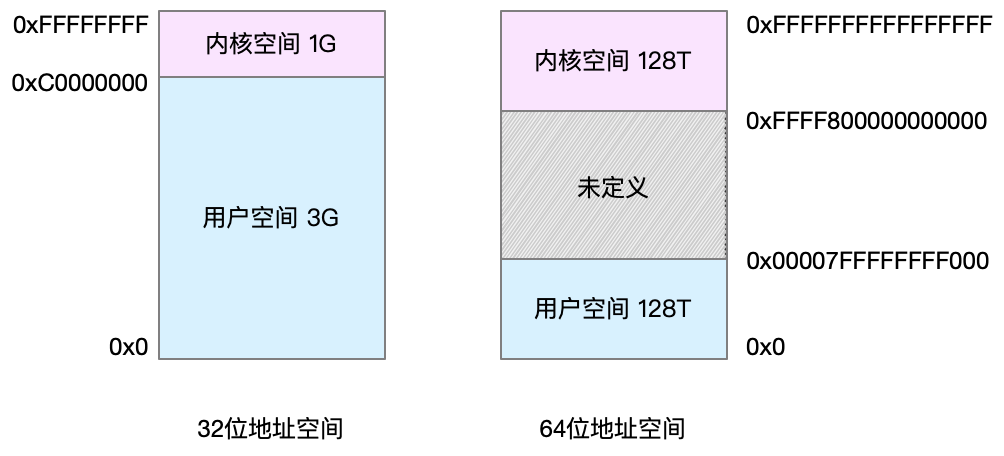
进程在用户态时,只能访问用户空间内存;只有进入内核态后,才可以访问内核空间内存。虽然每个进程的地址空间都包含了内核空间,但这些内核空间,其实关联的都是相同的物理内存,也就是共享动态链接库、共享内存等。当进程切换到内核态后,就可以很方便地访问内核空间内存。
并不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的。内存映射,其实就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系。
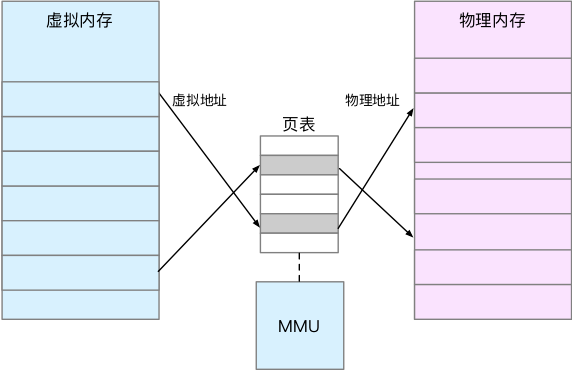
页表实际上存储在 CPU 的内存管理单元 MMU 中,这样,正常情况下,处理器就可以直接通过硬件,找出要访问的内存。而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
CPU 上下文切换中的TLB(Translation Lookaside Buffer,转译后备缓冲器)是 MMU 中页表的高速缓存。由于进程的虚拟地址空间是独立的,而 TLB 的访问速度又比 MMU 快得多,所以,通过减少进程的上下文切换,减少 TLB 的刷新次数,就可以提高 TLB 缓存的使用率,进而提高 CPU 的内存访问性能。
MMU 规定了一个内存映射的最小单位,也就是页,通常是 4 KB 大小。这样,每一次内存映射,都需要关联 4 KB 或者 4KB 整数倍的内存空间。
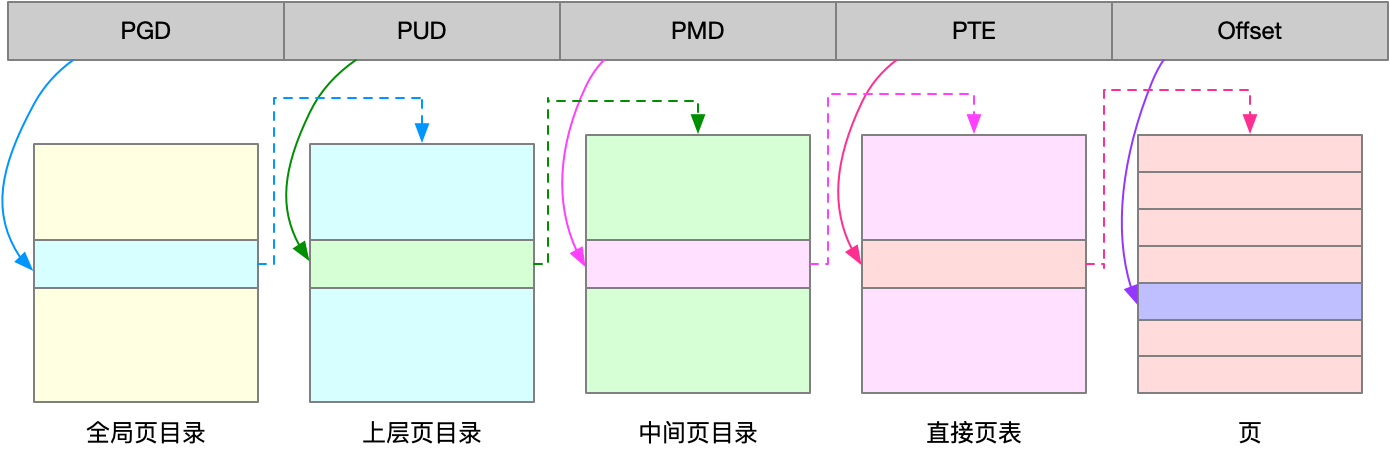
4 KB大小的页,会导致整个页表会变得非常大,比如32位系统4GB/4KB=100多万个页表项。为了解决页表项过多的问题,Linux 提供了两种机制,也就是多级页表和大页(HugePage)。
多级页表就是把内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移。由于虚拟内存空间通常只用了很少一部分,那么,多级页表就只保存这些使用中的区块,这样就可以大大地减少页表的项数。Linux 用四级页表来管理内存页,虚拟地址被分为 5 个部分,前 4 个表项用于选择页,而最后一个索引表示页内偏移。
大页,就是比普通页更大的内存块,常见的大小有 2MB 和 1GB。大页通常用在使用大量内存的进程上,比如 Oracle、DPDK 等。
通过这些机制,在页表的映射下,进程就可以通过虚拟地址来访问物理内存了。
虚拟内存空间分布
用户空间内存被分成五个不同的段。在这五个内存段中,堆和文件映射段的内存是动态分配的。如 C 标准库的 malloc() 或者 mmap() 分别在堆和文件映射段动态分配内存。64 位系统的内存分布也类似,只不过内存空间要大得多。

内存分配与回收
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
对小块内存(小于 128K),C 标准库使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
对大块内存(大于 128K),则直接使用内存映射 mmap() 来分配,也就是在文件映射段找一块空闲内存分配出去。
这两种方式的优缺点:
brk() 方式的缓存,可以减少缺页异常的发生,提高内存访问效率。不过,由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
mmap() 方式分配的内存,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。这也是 malloc 只对大块内存使用 mmap 的原因。
需要注意的是:当这两种调用发生后,其实并没有真正分配内存。这些内存,都只在首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
整体来说,Linux 使用伙伴系统来管理内存分配。前面我们提到过,这些内存在 MMU 中以页为单位进行管理,伙伴系统也一样,以页为单位来管理内存,并且会通过相邻页的合并,减少内存碎片化(比如 brk 方式造成的内存碎片)。
但在实际系统运行中,会有大量比页还小的对象,如不到1K,如果为它们也分配单独的页,会浪费大量的内存,那该怎么分配内存呢?
在用户空间,malloc 通过 brk() 分配的内存,在释放时并不立即归还系统,而是缓存起来重复利用。
在内核空间,Linux 则通过 slab 分配器来管理小内存。你可以把 slab 看成构建在伙伴系统上的一个缓存,主要作用就是分配并释放内核中的小对象。
内存回收:对内存来说,如果只分配而不释放,就会造成内存泄漏,甚至会耗尽系统内存。所以,在应用程序用完内存后,还需要调用 free() 或 unmap() ,来释放这些不用的内存。当然,系统也不会任由某个进程用完所有内存。在发现内存紧张时,系统就会通过一系列机制来回收内存,比如下面这三种方式:
(1)回收缓存,比如使用 LRU(Least Recently Used)算法,回收最近使用最少的内存页面。
(2)回收不常访问的内存,把不常用的内存通过交换分区(Swap)直接写到磁盘中。Swap 其实就是把一块磁盘空间当成内存来用。它可以把进程暂时不用的数据存储到磁盘中(这个过程称为换出),当进程访问这些内存时,再从磁盘读取这些数据到内存中(这个过程称为换入)。Swap 把系统的可用内存变大了,但通常只在内存不足时,才会发生 Swap 交换,并且由于磁盘读写的速度远比内存慢,Swap 会导致严重的内存性能问题。
(3)杀死进程,内存紧张时系统还会通过 OOM(Out of Memory,内核的一种保护机制),直接杀掉占用大量内存的进程.。OOM 监控进程的内存使用情况,并且使用 oom_score 为每个进程的内存使用情况进行评分:
一个进程消耗的内存越大,oom_score 就越大;
一个进程运行占用的 CPU 越多,oom_score 就越小。
这样,进程的 oom_score 越大,代表消耗的内存越多,也就越容易被 OOM 杀死,从而可以更好保护系统。
当然,为了实际工作的需要,管理员可以通过 /proc 文件系统,手动设置进程的 oom_adj,从而调整进程的 oom_score。oom_adj 的范围是 [-17, 15],数值越大,表示进程越容易被 OOM 杀死;数值越小,表示进程越不容易被 OOM 杀死,其中 -17 表示禁止 OOM。如用下面的命令,你就可以把 sshd 进程的 oom_adj 调小为 -16,这样, sshd 进程就不容易被 OOM 杀死。
echo -16 > /proc/$(pidof sshd)/oom_adj
如何查看内存使用情况
free 显示的是整个系统的内存使用情况
$ free
total used free shared buff/cache available
Mem: 8169348 263524 6875352 668 1030472 7611064
Swap: 0 0 0
默认单位是字节,行内容是物理内存 Mem 和交换分区 Swap,列分别为:
第一列,total 是总内存大小;
第二列,used 是已使用内存的大小,包含了共享内存;
第三列,free 是未使用内存的大小;
第四列,shared 是共享内存的大小
第五列,buff/cache 是缓存和缓冲区的大小;
最后一列,available 是新进程可用内存的大小。不仅包含未使用内存,还包括了可回收的缓存,所以一般会比未使用内存更大。不过,并不是所有缓存都可以回收,因为有些缓存可能正在使用中。
top / ps 查看进程内存使用情况:
# 按下 M 切换到内存排序
$ top
...
KiB Mem : 8169348 total, 6871440 free, 267096 used, 1030812 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7607492 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
430 root 19 -1 122360 35588 23748 S 0.0 0.4 0:32.17 systemd-journal
1075 root 20 0 771860 22744 11368 S 0.0 0.3 0:38.89 snapd
1048 root 20 0 170904 17292 9488 S 0.0 0.2 0:00.24 networkd-dispat
1 root 20 0 78020 9156 6644 S 0.0 0.1 0:22.92 systemd
12376 azure 20 0 76632 7456 6420 S 0.0 0.1 0:00.01 systemd
12374 root 20 0 107984 7312 6304 S 0.0 0.1 0:00.00 sshd
...
VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。
SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。
%MEM 是进程使用物理内存占系统总内存的百分比。
注意点:
(1)虚拟内存通常并不会全部分配物理内存。从上面的输出,你可以发现每个进程的虚拟内存都比常驻内存大得多。
(2)共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库,也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
Linux性能优化从入门到实战:08 内存篇:内存基础的更多相关文章
- Linux性能优化从入门到实战:01 Linux性能优化学习路线
我通过阅读各种相关书籍,从操作系统原理.到 Linux内核,再到硬件驱动程序等等. 把观察到的性能问题跟系统原理关联起来,特别是把系统从应用程序.库函数.系统调用.再到内核和硬件等不同的层级贯 ...
- Linux性能优化从入门到实战:16 文件系统篇:总结磁盘I/O指标/工具、问题定位和调优
(1)磁盘 I/O 性能指标 文件系统和磁盘 I/O 指标对应的工具 文件系统和磁盘 I/O 工具对应的指标 (2)磁盘 I/O 问题定位分析思路 (3)I/O 性能优化思路 Step 1:首先采用 ...
- Linux性能优化从入门到实战:07 CPU篇:CPU性能优化方法
性能优化方法论 动手优化性能之前,需要明确以下三个问题: (1)如何评估性能优化的效果? 确定性能的量化指标.测试优化前的性能指标.测试优化后的性能指标. 量化指标的选择.至少要从应用程序 ...
- Linux性能优化从入门到实战:12 内存篇:Swap 基础
内存资源紧张时,可能导致的结果 (1)OOM 杀死大内存CPU利用率又低的进程(系统内存耗尽的情况下才生效:OOM 触发的时机是基于虚拟内存,即进程在申请内存时,如果申请的虚拟内存加上服务器实际已用的 ...
- Linux性能优化从入门到实战:11 内存篇:内存泄漏的发现与定位
用户空间内存包括多个不同的内存段,比如只读段.数据段.堆.栈以及文件映射段等.但会发生内存泄漏的内存段,只有堆和文件映射段中的共享内存. 内存泄漏的危害非常大,这些忘记释放的内存,不仅应用程序 ...
- Linux性能优化从入门到实战:09 内存篇:Buffer和Cache
Buffer 是缓冲区,而 Cache 是缓存,两者都是数据在内存中的临时存储. 避免跟文中的"缓存"一词混淆,而文中的"缓存",则通指内存中的临时存储 ...
- Linux性能优化从入门到实战:10 内存篇:如何利用Buffer和Cache优化程序的运行效率?
缓存命中率 缓存命中率,是指直接通过缓存获取数据的请求次数,占所有数据请求次数的百分比,可以衡量缓存使用的好坏.命中率越高,表示使用缓存带来的收益越高,应用程序的性能也就越好. 实际上,缓存是 ...
- Linux性能优化从入门到实战:17 网络篇:网络基础
网络模型 为了解决网络互联中异构设备的兼容性问题,并解耦复杂的网络包处理流程,国际标准化组织制定了开放式系统互联通信参考模型(Open System Interconnection Reference ...
- Linux性能优化从入门到实战:15 文件系统篇:磁盘 I/O
磁盘 磁盘是可以持久化存储的设备,按照存储介质来分类: (1)机械磁盘(硬盘驱动器,Hard Disk Driver,HDD),主要由盘片和读写磁头组成,数据就存储在盘片的环状磁道中.在读写数 ...
随机推荐
- Ubuntu redis 实战 持久化策略 主从复制 以及 故障恢复
推荐文章 redis数据结构学习 redis持久化 redis主从复制 redis哨兵
- android 小游戏 ---- 数独(二)
> 首先创建一个自己的View类 -->继承SurfaceView并实现SurfaceHolder.Callback接口 --> SurfaceView.getHolder ...
- 730KII 打印机 Win7 2017年11月更新系统补丁后无法打印
卸载11月份编号为KB4048960的系统更新
- UNR#3 Day1——[ 堆+ST表+复杂度分析 ][ 结论 ][ 线段树合并 ]
地址:http://uoj.ac/contest/45 第一题是鸽子固定器. 只会10分.按 s 从小到大排序,然后 dp[ i ][ j ][ k ] 表示前 i 个元素.已经选了 j 个.最小值所 ...
- CG-CTF | MD5
渣渣今天写了一题misc,第一次学习md5的python写法,赶紧记录一波 背景知识: import hashlib md51=hashlib.md5() md52=hashlib.md5() # [ ...
- mvn 与 pom.xml
mvn 安装 wget http://mirrors.hust.edu.cn/apache//maven/maven-3/3.0.5/binaries/apache-maven-3.0.5-bin.t ...
- fedora安装ep,forge,fusion等第三方软件库
fedora安装ep,forge,fusion等第三方软件库 官方的发行版 抛弃了有 版权争议的 软件, 特别是 包括很多第三方的 多媒体软件, 如播放 mp3, flv等的软件 解码器 这就要靠 使 ...
- mysql_Qcahce
.cpu mem disk 如果是固态硬盘ssd那就是高速公路 火箭 高铁 普通公路 mysql 配置文件:windows 下 mysql.ini linux:my.cnf lamp路径:/opt/l ...
- 阶段1 语言基础+高级_1-3-Java语言高级_06-File类与IO流_09 序列化流_1_序列化和反序列化的概述
- 阶段1 语言基础+高级_1-3-Java语言高级_04-集合_01 Collection集合_5_迭代器的代码实现
迭代器的类型和collection一样.都是String类型的 判断集合内是不是有元素 取出第一个元素 多次next获取所有的值 没有元素,再去取就会抛出异常. 适应while for循环的格式了解一 ...