redis进阶知识
原文地址:https://my.oschina.net/u/4052893/blog/3001173
一、缓存雪崩
1.1什么是缓存雪崩?
回顾一下我们为什么要用缓存(Redis):
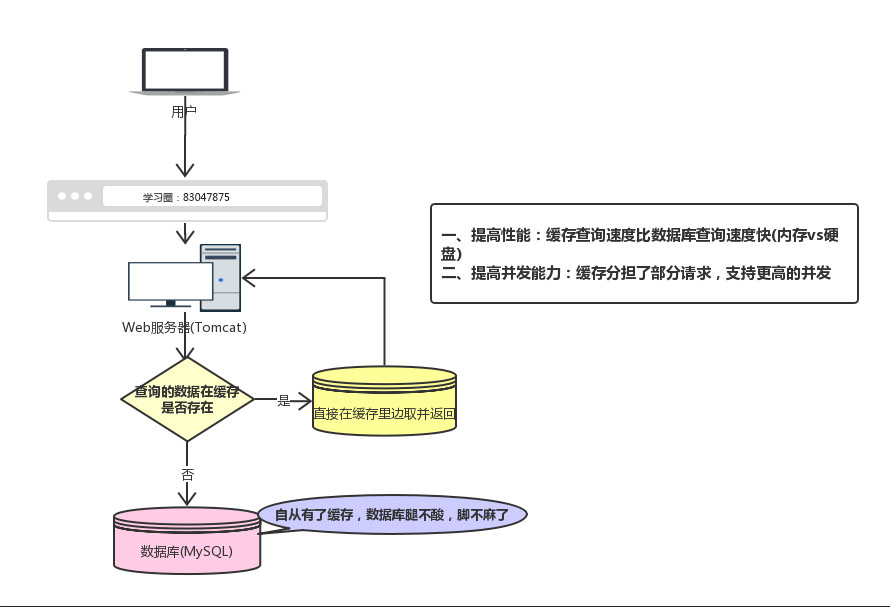
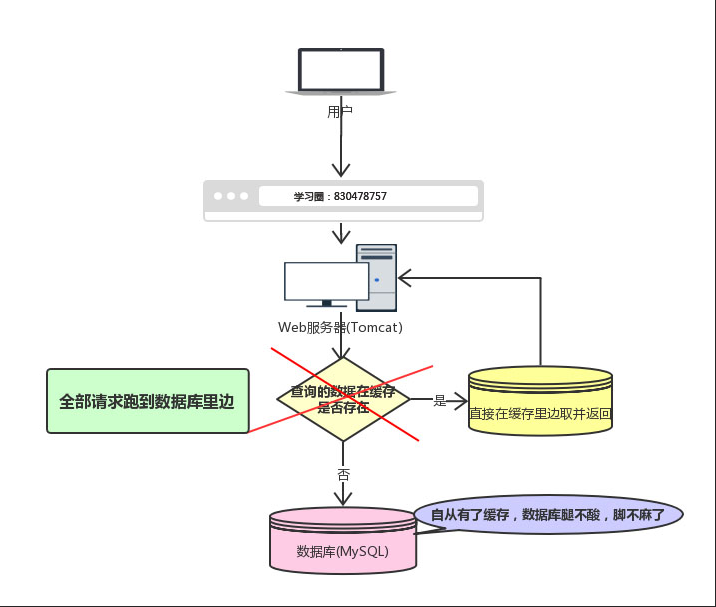
现在有个问题,如果我们的缓存挂掉了,这意味着我们的全部请求都跑去数据库了。
在前面学习我们都知道Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据设置过期时间,并采用的是惰性删除+定期删除两种策略对过期键删除。
如果缓存数据设置的过期时间是相同的,并且Redis恰好将这部分数据全部删光了。这就会导致在这段时间内,这些缓存同时失效,全部请求到数据库中。
这就是缓存雪崩:
- Redis挂掉了,请求全部走数据库。
- 对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。
缓存雪崩如果发生了,很可能就把我们的数据库搞垮,导致整个服务瘫痪!
1.2如何解决缓存雪崩?
对于“对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。”这种情况,非常好解决:
- 解决方法:在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
对于“Redis挂掉了,请求全部走数据库”这种情况,我们可以有以下的思路:
- 事发前:实现Redis的高可用(主从架构+Sentinel 或者Redis Cluster),尽量避免Redis挂掉这种情况发生。
- 事发中:万一Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
- 事发后:redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
二、缓存穿透
2.1什么是缓存穿透
比如,我们有一张数据库表,ID都是从1开始的(正数):

但是可能有黑客想把我的数据库搞垮,每次请求的ID都是负数。这会导致我的缓存就没用了,请求全部都找数据库去了,但数据库也没有这个值啊,所以每次都返回空出去。
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。

这就是缓存穿透:
- 请求的数据在缓存大量不命中,导致请求走数据库。
缓存穿透如果发生了,也可能把我们的数据库搞垮,导致整个服务瘫痪!
2.1如何解决缓存穿透?
解决缓存穿透也有两种方案:
- 由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者压缩filter提前拦截,不合法就不让这个请求到数据库层!
- 当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。
- 这种情况我们一般会将空对象设置一个较短的过期时间。
三、缓存与数据库双写一致
3.1对于读操作,流程是这样的
上面讲缓存穿透的时候也提到了:如果从数据库查不到数据则不写入缓存。
一般我们对读操作的时候有这么一个固定的套路:
- 如果我们的数据在缓存里边有,那么就直接取缓存的。
- 如果缓存里没有我们想要的数据,我们会先去查询数据库,然后将数据库查出来的数据写到缓存中。
- 最后将数据返回给请求
3.2什么是缓存与数据库双写一致问题?
如果仅仅查询的话,缓存的数据和数据库的数据是没问题的。但是,当我们要更新时候呢?各种情况很可能就造成数据库和缓存的数据不一致了。
- 这里不一致指的是:数据库的数据跟缓存的数据不一致

从理论上说,只要我们设置了键的过期时间,我们就能保证缓存和数据库的数据最终是一致的。因为只要缓存数据过期了,就会被删除。随后读的时候,因为缓存里没有,就可以查数据库的数据,然后将数据库查出来的数据写入到缓存中。
除了设置过期时间,我们还需要做更多的措施来尽量避免数据库与缓存处于不一致的情况发生。
3.3对于更新操作
一般来说,执行更新操作时,我们会有两种选择:
- 先操作数据库,再操作缓存
- 先操作缓存,再操作数据库
首先,要明确的是,无论我们选择哪个,我们都希望这两个操作要么同时成功,要么同时失败。所以,这会演变成一个分布式事务的问题。
所以,如果原子性被破坏了,可能会有以下的情况:
- 操作数据库成功了,操作缓存失败了。
- 操作缓存成功了,操作数据库失败了。
如果第一步已经失败了,我们直接返回Exception出去就好了,第二步根本不会执行。
下面我们具体来分析一下吧。
3.3.1操作缓存
操作缓存也有两种方案:
- 更新缓存
- 删除缓存
一般我们都是采取删除缓存缓存策略的,原因如下:
- 高并发环境下,无论是先操作数据库还是后操作数据库而言,如果加上更新缓存,那就更加容易导致数据库与缓存数据不一致问题。(删除缓存直接和简单很多)
- 如果每次更新了数据库,都要更新缓存【这里指的是频繁更新的场景,这会耗费一定的性能】,倒不如直接删除掉。等再次读取时,缓存里没有,那我到数据库找,在数据库找到再写到缓存里边(体现懒加载)
基于这两点,对于缓存在更新时而言,都是建议执行删除操作!
3.3.2先更新数据库,再删除缓存
正常的情况是这样的:
- 先操作数据库,成功;
- 再删除缓存,也成功;
如果原子性被破坏了:
- 第一步成功(操作数据库),第二步失败(删除缓存),会导致数据库里是新数据,而缓存里是旧数据。
- 如果第一步(操作数据库)就失败了,我们可以直接返回错误(Exception),不会出现数据不一致。
如果在高并发的场景下,出现数据库与缓存数据不一致的概率特别低,也不是没有:
- 缓存刚好失效
- 线程A查询数据库,得一个旧值
- 线程B将新值写入数据库
- 线程B删除缓存
- 线程A将查到的旧值写入缓存
要达成上述情况,还是说一句概率特别低:
因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
对于这种策略,其实是一种设计模式:Cache Aside Pattern

删除缓存失败的解决思路:
- 将需要删除的key发送到消息队列中
- 自己消费消息,获得需要删除的key
- 不断重试删除操作,直到成功
3.3.3先删除缓存,再更新数据库
正常情况是这样的:
- 先删除缓存,成功;
- 再更新数据库,也成功;
如果原子性被破坏了:
- 第一步成功(删除缓存),第二步失败(更新数据库),数据库和缓存的数据还是一致的。
- 如果第一步(删除缓存)就失败了,我们可以直接返回错误(Exception),数据库和缓存的数据还是一致的。
看起来是很美好,但是我们在并发场景下分析一下,就知道还是有问题的了:
- 线程A删除了缓存
- 线程B查询,发现缓存已不存在
- 线程B去数据库查询得到旧值
- 线程B将旧值写入缓存
- 线程A将新值写入数据库
所以也会导致数据库和缓存不一致的问题。
并发下解决数据库与缓存不一致的思路:
- 将删除缓存、修改数据库、读取缓存等的操作积压到队列里边,实现串行化。

3.4对比两种策略
我们可以发现,两种策略各自有优缺点:
- 先删除缓存,再更新数据库
- 在高并发下表现不如意,在原子性被破坏时表现优异
- 先更新数据库,再删除缓存(
Cache Aside Pattern设计模式)- 在高并发下表现优异,在原子性被破坏时表现不如意
3.5其他保障数据一致的方案与资料
可以用databus或者阿里的canal监听binlog进行更新。
redis进阶知识的更多相关文章
- Redis进阶知识一览
Redis的持久化机制 RDB: Redis DataBase 什么是RDB RDB∶每隔一段时间,把内存中的数据写入磁盘的临时文件,作为快照,恢复的时候把快照文件读进内存.如果宕机重启,那么内存里的 ...
- 【进阶之路】Redis基础知识两篇就满足(一)
导言 大家好,我是南橘,一名练习时常两年半的java练习生,这是我在博客园的第一篇文章,当然,都是要从别处搬运过来的,不过以后新的文章也会在博客园同步发布,希望大家能多多支持^_^ 这篇文章的出现,首 ...
- 【进阶之路】Redis基础知识两篇就满足(二)
导言 大家好,我是南橘,一名练习时常两年半的java练习生,这是我在博客园的第二篇文章,当然,都是要从别处搬运过来的,不过以后新的文章也会在博客园同步发布,希望大家能多多支持^_^ 这篇文章的出现,首 ...
- Spring实战3:装配bean的进阶知识
主要内容: Environments and profiles Conditional bean declaration 处理自动装配的歧义 bean的作用域 The Spring Expressio ...
- Redis进阶实践之十三 Redis的Redis-trib.rb文件详解
一.简介 事先说明一下,本篇文章不涉及对redis-trib.rb源代码的分析,只是从使用的角度来阐述一下,对第一次使用的人来说很重要.redis-trib.rb是redis官方推出的管理re ...
- Redis进阶实践之十六 Redis大批量增加数据
一.介绍 有时,Redis实例需要在很短的时间内加载大量先前存在或用户生成的数据,以便尽可能快地创建数百万个键.这就是所谓的批量插入,本文档的目标是提供有关如何以尽可能快的速度向Redis提 ...
- Redis进阶实践之十八 使用管道模式加速Redis查询
一.引言 学习redis 也有一段时间了,该接触的也差不多了.后来有一天,以为同事问我,如何向redis中批量的增加数据,肯定是大批量的,为了这主题,我从新找起了解决方案.目前 ...
- Redis基础知识小结
Redis是一个高性能的key-value型数据库.Redis能读的速度是110000次/s,写的速度是81000次/s ,性能极高.Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全 ...
- Redis进阶实践之十三 Redis的Redis-trib.rb脚本文件使用详解
转载来源:http://www.cnblogs.com/PatrickLiu/p/8484784.html 一.简介 事先说明一下,本篇文章不涉及对redis-trib.rb源代码的分析,只是从使用的 ...
随机推荐
- docker小知识
1,docker 使用普通用户 添加用户组: sudo groupadd docker 加入docker 组 sudo gpasswd -a ${USER} docker 或 usermod -aG ...
- druid配置以及监控
1.druid监控的功能: . 数据源 . SQL监控 对执行的MySQL语句进行记录,并记录执行时间.事务次数等 . SQL防火墙 对SQL进行预编译,并统计该条SQL的数据指标 . Web应用 对 ...
- npm 安装与卸载模块
1. 只卸载模块 由于之前安装过,在 package.json 中的记录仍然存在 npm uninstall lodash 2. --save 参数使用 卸载模块的同时删除在 package.json ...
- 病毒 x
04:病毒 查看 提交 统计 提问 总时间限制: 1000ms 内存限制: 65535kB 描述 有一天,小y突然发现自己的计算机感染了一种病毒!还好,小y发现这种病毒很弱,只是会把文档中的所有字 ...
- k8s安装报错 Error: unknown flag: --experimental-upload-certs
今天安装k8sV1.16的版本时候,执行突然发现命令不对,之前安装V1.15的时候是可以的,可能是版本升级的原因. 解决: unknown flag: --experimental-upload-ce ...
- 修改docker下mysql配置
1.在/home/smile/docker/mysql/config/目录下增加一个文件 my.cnf # Copyright (c) , Oracle and/or its affiliates. ...
- webpack前置知识2(JavaScript项目初始化)
所有的JavaScript项目都是在终端输入npm init -y进行项目初始化,如果要自定义项目规则,去掉 -y 参数. vscode终端快捷键ctrl+` 初始化 运行上述命令后,项目内会新建一个 ...
- ObjectDataSource.ObjectCreating 事件
ObjectCreating 事件在创建由 TypeName 属性标识的对象之前发生. 命名空间:System.Web.UI.WebControls程序集:System.Web(在 system.we ...
- 1、node-webkit 的概念,node-webkit 的下载
node-webkit是一个基于node.js和chromium的应用程序运行环境,通过它我们可以把建立在chrome浏览器和node.js上的web应用打包成桌面应用,而且还可以跨平台的哦.很显然比 ...
- SPEL 表达式解析
Spring Expression Language 解析器 SPEL解析过程 使用 ExpressionParser 基于 ParserContext 将字符串解析为 Expression, Exp ...