JVM内存模型及GC回收算法
该篇博客主要对JVM内存模型以及GC回收算法以自己的理解和认识做以记录。
- 内存模型
- GC垃圾回收
1.内存模型
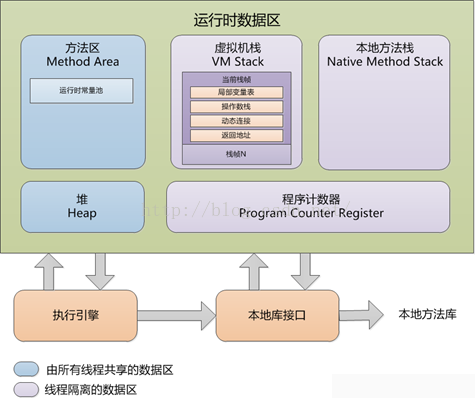
从上图可以看出,JVM分为 方法区,虚拟机栈,本地方法栈,堆,计数器 5个区域。其中最为重要的就是栈和堆。
栈和堆设计的目的是什么呢?
- 栈存储了处理逻辑,堆存储了具体的数据,这样使得栈和堆中处理耦合度降低,也更为清晰
- 栈和堆分离,使得堆可以被多个栈共享
- 栈保存了上下文信息,因此只向上增长,而堆是动态分配
栈的大小可以通过XSs设置,如果栈空间不足,会抛出java.lang.StackOverflowError异常
2.各区域的动能及说明
- 虚拟机栈区
线程私有,栈内的数据线程之间独立,生命周期与线程相同,每个方法的执行都会创建一个栈帧(stack frame)用于存放
a.局部变量表:是一组变量值的存储空间,用于存放方法参数和局部变量,在Class文件方法表的Code属性的max_locals指定了该方法所需局部变量的最大容量,有关
b.操作数栈:也称为操作栈,是一个后入先出栈。在Class文件的Code属性的max_stacks制订了执行过程中最大的栈深度,java虚拟机的解释执行引擎为“基于栈的执行引擎”,这里的栈指的就是操作数栈。
方法执行中进行算术运算或者是调用其他的方法进行参数传递的时候是通过操作数栈进行的。
在概念模型中,两个栈是互相独立的,但是大多数虚拟机都会进行优化,令两个栈帧出现一部分重合,令下面的部分操作数栈和与上面的局部变量表重叠在一起,这样方法调用的时候可以共用一部分数据,无需进行额外的参数传递。
c.动态链接:每个栈帧都包含一个执行运行时常量池中该栈帧所属方法的引用,持有这个引用就是为了支持方法调用过程中的动态链接(Dynamic Linking)。
d.方法返回地址:当一个方法开始执行后,有两种方式可以退出当前方法:
① 当执行遇到返回指令,会将返回值传递给上层的调用者,这种退出的方式称为正常完成出口(Normal Method Invocation Completion),一般来说,调用者的PC计数器可以作为返回地址。
② 当执行遇到异常,并且当前方法内没有得到处理,就会导致方法退出,此时是没有返回值的,称为异常完成出口(Abrupt Method Invocation Completion),返回地址要通过异常处理器表来确定。
当方法返回时,可能进行3个操作:
① 恢复上层方法的局部表量表和操作数栈
② 把返回值压入调用者栈帧的操作数栈
③ 调整PC计数器的值,以指向方法调用指令后面的一条指令
e.附加信息:虚拟机规范并没有规范虚拟机实际包含什么附加信息,这部分的内容完全取决于具体实现,在实际开发中,一般会把动态链接,方法返回地址和附加信息全部归位一类,称为栈帧信息
注:Java虚拟机栈主要出现两种异常:
① StackOverFlowError 若虚拟机栈的内存大小不允许扩展,那么当线程请求栈的深度超过当前Java虚拟机栈的最大深度的时候,就会抛出StackOverFlowError
② OutOfMemoryError 若虚拟机内存大小允许扩展,切当线程请求栈时内存用完了,无法再扩展了,此时会抛出OutOfMemoryError
这两种Error的异同:
StackOverFlowError 表示当前线程申请的栈超过了事先定好的栈的最大深度,但内存空间可能还有很多
OutOfMemoryError 是指当前线程申请栈时发现栈已经满了,而且内存也全部用完了
每个栈帧进栈和出栈对应的是一个方法进入和退出,当出栈的时候空间自动释放,垃圾回收并不在栈内回收!!!!
- 本地方法栈
本地方法栈和Java虚拟机栈实现的功能类似,只不过本地方法栈是本地方法运行的内存模型
本地方法运行的时候,在本地方法栈也会创建一个栈帧,用于存放本地方法的局部表量表,操作数栈,动态链接,方法出口信息。
方法执行完毕后,相应的栈帧也会出栈,并释放内存空间
- 堆
存放对象实例,所有的对象的内存都在这里分配,垃圾回收主要就是作用于这里的,JVM只有一个堆区,被所有线程共享
- 堆的初始内存由Xms指定,默认为物理内存的1/64;最大内存由-Xmx指定,默认是物理内存的1/4
- 默认空余的内存小于40%时,就会增大,直到-Xmx设置的内存大小,具体的比例由-XX:MinHeapFreeRatio指定
- 空余的内存大于70%时,内存就会减小,直到-Xms设置的内存大小,具体的比例由-XX:MaxHeapFreeRatio指定
因此,一般建议都把-XX:MinHeapFreeRatio和-XX:MinHeapFreeRatio设置成一样大,可以避免JVM不断调整大小
堆的特点:
a. 线程共享:整个Java虚拟机只有一个堆,而程序计数器、Java虚拟机栈,本地方法栈 都是一个线程对应一个的。
b. 在虚拟机启动时创建
c. 可进一步分为:新生代和老年代,新生代又可划分为 Eden,From SurVior,To Survior,不同的区域存放着具有不同生命周期额对象,这样可以根据不同区域使用不同的垃圾回收算法,从而更具有针对性, 从而更高效。
d. 堆的大小可以固定也可以扩展,但主流的虚拟机堆的大小是可扩展的,因此当线程请求分配内存,但堆已满,切内存已满无法再扩展时,就抛出OutOfMemoryError
- 计数器
程序计数器是一块较小的内存空间,可以把它看成是当前线程正在执行的字节码的行号指示器,也就是说,程序计数器里面记录的是当前正在执行的那一条字节码指令的地址。
字节码:java文件编译后的class文件,也及时16进制的字节。有关字节码的资料,参考 http://www.importnew.com/24088.html
注:但是,如果当前正在执行的是一个本地方法,那么此时程序计数器为空。
a. 程序计数器特点:
① 是一块较小的存储空间,
② 线程私有,每条线程都有一个程序计数器
③ 是唯一一个不会出现OutOfMemoryError的内存区域
④ 生命周期随着线程的创建而创建,随着线程的结束而结束
b. 程序计数器的作用:
① 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行,选择,循环,异常处理
② 在多线程的情况下,程序计数器用于记录当前线程的执行位置,从而当线程切换回来的时候能知道该线程上次运行到哪儿了。
- 方法区
Java虚拟机规范中定义的方法区是堆的一个逻辑部分。方法区存放已经被虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等。
方法区的特点:
① 线程共享:方法区是堆的一个逻辑部分,因此和堆一样,都是线程共享的,整个虚拟机中只有一个方法区。
② 永久代:方法区中的信息一般需要长期存在,而他又是堆的逻辑部分,因此用堆的划分方法,我们把方法区称为老年代
③ 内存回收率低:
方法区中的信息一般需要长期存在,回收一边内存之后,只可能只有少量信息无效。
对于方法区的内存回收的主要目的是:对常量池的回收和对类型的卸载
④ Java虚拟机规范对方法区的要求比较宽松 : 和堆一样,允许固定大小,还允许不实现垃圾回收。
运行时常量池:方法区中存放三种数据:类信息,常量,静态变量,即时编译器编译后的代码,其中常量存储在运行时常量池中。我们一般用public static final 声明一个常量,运行期间,可以向常量池中添加新的常量,如:String 类的 intern()方法就能在运行期间向常量池中添加字符串常量。当运行时常量池中的某些常量没有被对象引用,同时也没有被变量引用,那么久需要垃圾收集器回收。
- 直接内存
直接内存是除Java虚拟机以外的内存,但也有可能被Java使用。
在NIO中引入了一种基于通道和缓冲的IO方式,它可以通过调用本地方法直接分配Java虚拟机之外的内存,然后通过一个存储在Java对中的DirectByteBuffer对象直接操作该内存,而无需先将外面内存中的数据复制到堆中再操作,从而提升了操作的效率。
直接内存的大小不受Java虚拟机的控制,但既然是内存,当内存不足时就会抛出OOM
3.简单总结
① Java虚拟机的内存模型中一共有两个“栈”,分别是:Java虚拟机栈和本地方法栈。
两个“栈”的功能类似,都是方法运行过程的内存模型。并且两个“栈”内部构造相同,都是线程私有。
只不过Java虚拟机栈描述的是Java方法运行过程的内存模型,而本地方法栈是描述Java本地方法运行过程的内存模型。
② Java虚拟机的内存模型中一共有两个“堆”,一个是原本的堆,一个是方法区。方法区本质上是属于堆的一个逻辑部分。堆中存放对象,方法区中存放类信息、常量、静态变量、即时编译器编译的代码。
堆是Java虚拟机中最大的一块内存区域,也是垃圾收集器主要的工作区域。
③ 程序计数器、Java虚拟机栈、本地方法栈是线程私有的,即每个线程都拥有各自的程序计数器、Java虚拟机栈、本地方法区。并且他们的生命周期和所属的线程一样。
而堆、方法区是线程共享的,在Java虚拟机中只有一个堆、一个方法栈。并在JVM启动的时候就创建,JVM停止才销毁。
4.查看JVM
用-verbose:gc 或者 -Xloggc 选项调用 JVM那么每次 GC 运行时在控制台上或者日志文件中会打印出一个诊断信息,包括它所花费的时间、当前堆使用情况以及恢复了多少内存
有工具可以利用 GC 日志输出并以图形方式将它显示出来,JTune 就是这样的一种工具
5.垃圾收集器
在介绍垃圾收集器之前,需要明确一点,就是在新生代采用的停止复制算法中,停止的意思是在回收内存时,需要暂停其他所有线程的执行,这个是很低效的,现在各种新生代的收集器越来越优化这一点,但仍然知识停止的时间变短,并未彻底取消掉。
- Serial收集器:新生代收集器,使用停止复制算法,使用一个线程进行GC,其它工作线程暂停。使用-XX:+UseSerialGC可以使用Serial+Serial Old模式运行进行内存回收(这也是虚拟机在Client模式下运行的默认值)
- ParNew收集器:新生代收集器,使用停止复制算法,Serial收集器的多线程版,用多个线程进行GC,其它工作线程暂停,关注缩短垃圾收集时间。使用-XX:+UseParNewGC开关来控制使用ParNew+Serial Old收集器组合收集内存;使用-XX:ParallelGCThreads来设置执行内存回收的线程数。
- Parallel Scavenge 收集器:新生代收集器,使用停止复制算法,关注CPU吞吐量,即运行用户代码的时间/总时间,比如:JVM运行100分钟,其中运行用户代码99分钟,垃 圾收集1分钟,则吞吐量是99%,这种收集器能最高效率的利用CPU,适合运行后台运算(关注缩短垃圾收集时间的收集器,如CMS,等待时间很少,所以适 合用户交互,提高用户体验)。使用-XX:+UseParallelGC开关控制使用 Parallel Scavenge+Serial Old收集器组合回收垃圾(这也是在Server模式下的默认值);使用-XX:GCTimeRatio来设置用户执行时间占总时间的比例,默认99,即 1%的时间用来进行垃圾回收。使用-XX:MaxGCPauseMillis设置GC的最大停顿时间(这个参数只对Parallel Scavenge有效)
- Serial Old收集器:老年代收集器,单线程收集器,使用标记整理(整理的方法是Sweep(清理)和Compact(压缩),清理是将废弃的对象干掉,只留幸存 的对象,压缩是将移动对象,将空间填满保证内存分为2块,一块全是对象,一块空闲)算法,使用单线程进行GC,其它工作线程暂停(注意,在老年代中进行标 记整理算法清理,也需要暂停其它线程),在JDK1.5之前,Serial Old收集器与ParallelScavenge搭配使用。
- Parallel Old收集器:老年代收集器,多线程,多线程机制与Parallel Scavenge差不错,使用标记整理(与Serial Old不同,这里的整理是Summary(汇总)和Compact(压缩),汇总的意思就是将幸存的对象复制到预先准备好的区域,而不是像Sweep(清 理)那样清理废弃的对象)算法,在Parallel Old执行时,仍然需要暂停其它线程。Parallel Old在多核计算中很有用。Parallel Old出现后(JDK 1.6),与Parallel Scavenge配合有很好的效果,充分体现Parallel Scavenge收集器吞吐量优先的效果。使用-XX:+UseParallelOldGC开关控制使用Parallel Scavenge +Parallel Old组合收集器进行收集。
- CMS(Concurrent Mark Sweep)收集器:老年代收集器,致力于获取最短回收停顿时间,使用标记清除算法,多线程,优点是并发收集(用户线程可以和GC线程同时工作),停顿小。使用-XX:+UseConcMarkSweepGC进行ParNew+CMS+Serial Old进行内存回收,优先使用ParNew+CMS(原因见后面),当用户线程内存不足时,采用备用方案Serial Old收集。
CMS收集的方法是:先3次标记,再1次清除,3次标记中前两次是初始标记和重新标记(此时仍然需要停止(stop the world)), 初始标记(Initial Remark)是标记GC Roots能关联到的对象(即有引用的对象),停顿时间很短;并发标记(Concurrent remark)是执行GC Roots查找引用的过程,不需要用户线程停顿;重新标记(Remark)是在初始标记和并发标记期间,有标记变动的那部分仍需要标记,所以加上这一部分 标记的过程,停顿时间比并发标记小得多,但比初始标记稍长。在完成标记之后,就开始并发清除,不需要用户线程停顿。
所以在CMS清理过程中,只有初始标记和重新标记需要短暂停顿,并发标记和并发清除都不需要暂停用户线程,因此效率很高,很适合高交互的场合。
CMS也有缺点,它需要消耗额外的CPU和内存资源,在CPU和内存资源紧张,CPU较少时,会加重系统负担(CMS默认启动线程数为(CPU数量+3)/4)。
另外,在并发收集过程中,用户线程仍然在运行,仍然产生内存垃圾,所以可能产生“浮动垃圾”,本次无法清理,只能下一次Full GC才清理,因此在GC期间,需要预留足够的内存给用户线程使用。所以使用CMS的收集器并不是老年代满了才触发Full GC,而是在使用了一大半(默认68%,即2/3,使用-XX:CMSInitiatingOccupancyFraction来设置)的时候就要进行Full GC,如果用户线程消耗内存不是特别大,可以适当调高-XX:CMSInitiatingOccupancyFraction以降低GC次数,提高性能,如果预留的用户线程内存不够,则会触发Concurrent Mode Failure,此时,将触发备用方案:使用Serial Old 收集器进行收集,但这样停顿时间就长了,因此-XX:CMSInitiatingOccupancyFraction不宜设的过大。
还有,CMS采用的是标记清除算法,会导致内存碎片的产生,可以使用-XX:+UseCMSCompactAtFullCollection来设置是否在Full GC之后进行碎片整理,用-XX:CMSFullGCsBeforeCompaction来设置在执行多少次不压缩的Full GC之后,来一次带压缩的Full GC。
新生代收集器:
1.Serial收集器,单线程收集器,采用复制算法,由于单线程,所有在java服务器端开发中,肯定不会去用它。
2.ParNew收集器,是Serial的多线程版本,采用复制算法,可以说是java服务器端首选收集器。
3.Parallel Scavenge收集器,多线程,采用复制算法,此收集器最大的特点在可控制垃圾回收的吞吐量,此垃圾收集器适用于非实时和用户交互的服务器,适用于后台跑算法,跑job的服务器。
老年代收集器:
1.Serial old, Serial的老年版本。单线程的,采用标记-整理算法,很遗憾,同样不适合服务器中使用。
2.Parallel old,Parallel Scavenge的老年版本。多线程,标记-整理算法,此收集器和Parallel Scavenge特点一样,这2种收集器搭配,对于跑job的服务器来说,是很不错的,不过还的侃实际应用来配置,万一job任务的时间间隔很短,这时候在gc,可能就有问题,所以也不能一味最求吞吐量。
3.cms收集器,标记-清除算法,此收集器特点是,垃圾回收停顿时间短,重视服务器响应速度,给用户带来好的体验。
最后是新生代和老年代通吃的收集器,G1收集器。G1可以说非常强悍,除了吞吐量需求大的,其它的都可以被g1代替了。总之,以后服务器要体验好的,就用g1收集器,要吞吐量大的就用Parallel套装。
JVM内存模型及GC回收算法的更多相关文章
- JVM内存模型,垃圾回收算法
JVM内存模型总体架构图 程序计数器多线程时,当线程数超过CPU数量或CPU内核数量,线程之间就要根据时间片轮询抢夺CPU时间资源.因此每个线程有要有一个独立的程序计数器,记录下一条要运行的指令.线程 ...
- JVM内存模型及垃圾回收算法
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- JVM内存模型与GC算法
1.JVM内存模型 JVM内存模型如上图,需要声明一点,这是<Java虚拟机规范(Java SE 7版)>规定的内容,实际区域由各JVM自己实现,所以可能略有不同.以下对各区域进行简短说明 ...
- JVM内存模型与GC算法(简介)
JVM内存模型如上图,需要声明一点,这是<Java虚拟机规范(Java SE 7版)>规定的内容,实际区域由各JVM自己实现,所以可能略有不同.以下对各区域进行简短说明. 1.1程序计数器 ...
- JVM的stack和heap,JVM内存模型,垃圾回收策略,分代收集,增量收集
(转自:http://my.oschina.net/u/436879/blog/85478) 在JVM中,内存分为两个部分,Stack(栈)和Heap(堆),这里,我们从JVM的内存管理原理的角度来认 ...
- 程序猿的日常——JVM内存模型与垃圾回收
Java开发有个很基础的问题,虽然我们平时接触的不多,但是了解它却成为Java开发的必备基础--这就是JVM.在C++中我们需要手动申请内存然后释放内存,否则就会出现对象已经不再使用内存却仍被占用的情 ...
- JVM内存模型以及垃圾回收
JAVA堆的描述如下: 内存由Perm和Heap组成.其中Heap = {Old + NEW = { Eden , from, to } } JVM内存模型中分两大块: NEW Generation: ...
- JVM内存模型和垃圾回收
Java开发有个很基础的问题,虽然我们平时接触的不多,但是了解它却成为Java开发的必备基础——这就是JVM.在C++中我们需要手动申请内存然后释放内存,否则就会出现对象已经不再使用内存却仍被占用的情 ...
- 【Java_基础】JVM内存模型与垃圾回收机制
1. JVM内存模型 Java虚拟机在程序执行过程会把jvm的内存分为若干个不同的数据区域来管理,这些区域有自己的用途,以及创建和销毁时间. JVM内存模型如下图所示 1.1 程序计数器 程序计数器( ...
随机推荐
- BZOJ3331 BZOJ2013 压力
考前挣扎 圆方树这么早就出现了嘛... 要求每个点必须被经过的次数 所以就是路径上的割点/端点++ 由于圆方树上所有非叶子圆点都是割点 所以就是树上差分就可以辣. 实现的时候出了一点小问题. 就是这里 ...
- SQL执行顺序和coalesce以及case when的用法
1.mysql的执行顺序 from on join where group by having select distinct union //UNION 操作符用于合并两个或多个 SELECT ...
- POJ 3525 Most Distant Point from the Sea (半平面交)
Description The main land of Japan called Honshu is an island surrounded by the sea. In such an isla ...
- jQuery 问题收集
1.页面动态生成的dom元素,监听事件失效.需用事件代理进行监听. 对于动态绑定元素可以这样写 $(document).on('click', '.xxx', function() { // do s ...
- ubuntu 配置jre后出现问题Error occurred during initialization of VM
百度了好久,找到了一个可以解决的办法. https://blog.51cto.com/chris2013/1313117 就是在usr/java/jre/lib/rt.pack需要解压成rt.jar ...
- Map-Amap:货运解决方案
ylbtech-Map-Amap:货运解决方案 1.返回顶部 1. http://lbs.amap.com/smart/truck/ 2. 2.返回顶部 1. 2. 3.返回顶部 4.返回顶部 ...
- docker安装部署命令
一.安装工具包 $ sudo yum install -y yum-utils #安装工具包,缺少这些依赖将无法完成 二.设置远程仓库 $sudo yum-config-manager --add-r ...
- Linux操作系统(四)_部署MySQL
一.部署过程 1.当前服务器的内核版本和发行版本 cat /etc/issue uname -a 2.检查系统有没有自带mysql,并卸载自带版本 yum list installed | grep ...
- T1373:鱼塘钓鱼(fishing)
原题链接:1373:鱼塘钓鱼(fishing) 解题思路: 由于在走路时,鱼的数量不会减少,那我们此时可以先减去路上可能花掉的时间,用剩下的时间来找最多的鱼,然后从左向右走,k枚举能到达的最远的鱼塘, ...
- Linear Regression and Gradient Descent (English version)
1.Problem and Loss Function Linear Regression is a Supervised Learning Algorithm with input matrix ...