Newsgroups数据集研究
1.数据集介绍
20newsgroups数据集是用于文本分类、文本挖据和信息检索研究的国际标准数据集之一。
数据集收集了大约20,000左右的新闻组文档,均匀分为20个不同主题的新闻组集合。
一些新闻组的主题特别相似(e.g. comp.sys.ibm.pc.hardware/ comp.sys.mac.hardware),还有一些却完全不相关 (e.g misc.forsale /soc.religion.christian)。
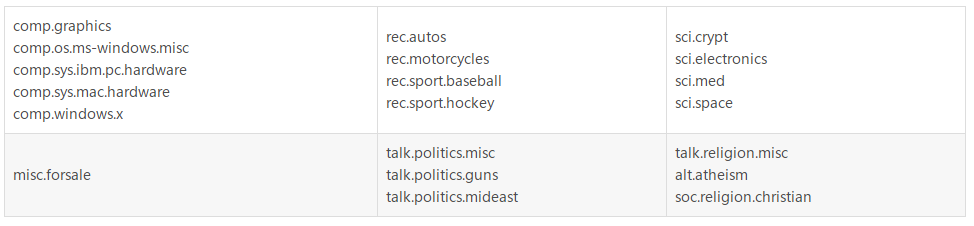
20newsgroups数据集有三个版本:
第一个版本19997是原始的并没有修改过的版本:20news-19997.tar.gz –原始20 Newsgroups数据集
第二个版本bydate是按时间顺序分为训练(60%)和测试(40%)两部分数据集,不包含重复文档和新闻组名(新闻组,路径,隶属于,日期):20news-bydate.tar.gz –按时间分类; 不包含重复文档和新闻组名(18846 个文档)
第三个版本18828不包含重复文档,只有来源和主题:20news-18828.tar.gz– 不包含重复文档,只有来源和主题 (18828 个文档)
在sklearn中,该模型有两种装载方式:
第一种是sklearn.datasets.fetch_20newsgroups,返回一个可以被文本特征提取器(如sklearn.feature_extraction.text.CountVectorizer)自定义参数提取特征的原始文本序列;
第二种是sklearn.datasets.fetch_20newsgroups_vectorized,返回一个已提取特征的文本序列,即不需要使用特征提取器。
2.数据集下载
使用ptyhon进行下载:
from sklearn.datasets import fetch_20newsgroups
corpus_path = './corpora_data'
data_train = fetch_20newsgroups(data_home=corpus_path, subset='train', categories=categories, shuffle=True, random_state=0, remove=remove)
data_test = fetch_20newsgroups(data_home=corpus_path, subset='test', categories=categories, shuffle=True, random_state=0, remove=remove)
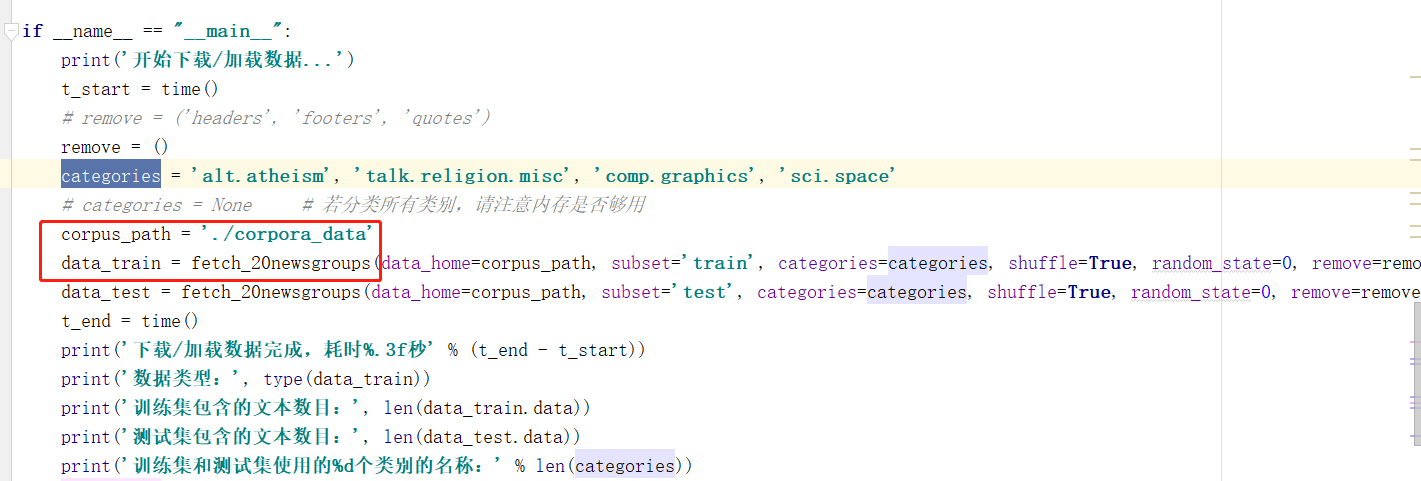
发现真的很卡。。。放弃
3.使用本地数据集
采取第二种方案:
1.下载文件
点击它给出的链接:20news-bydate.tar.gz –按时间分类; 不包含重复文档和新闻组名(18846 个文档)
2.路径修改
(1)下载后直接放在d:盘路径下
(2)
- 找到文件Anaconda3\Lib\site-packages\sklearn\datasets\twenty_newsgroups.py
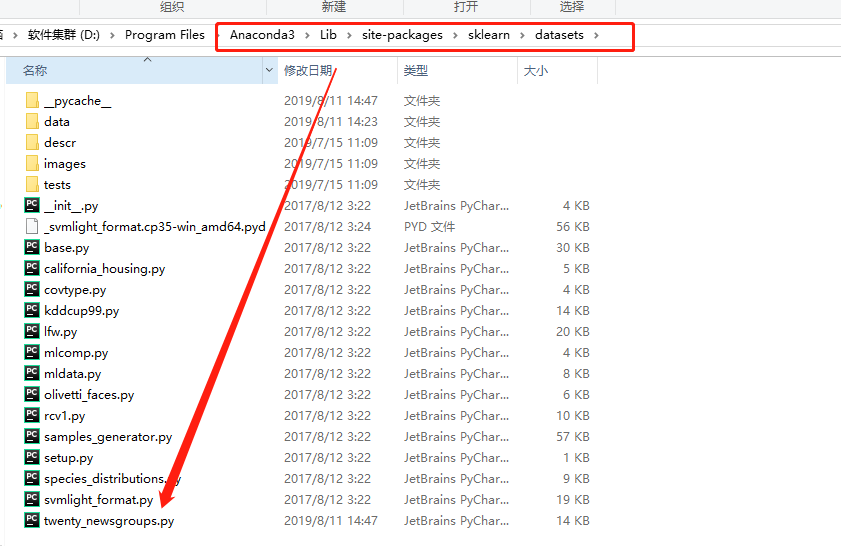
- 修改把在下载的代码注销(红色),增加路径(蓝色)
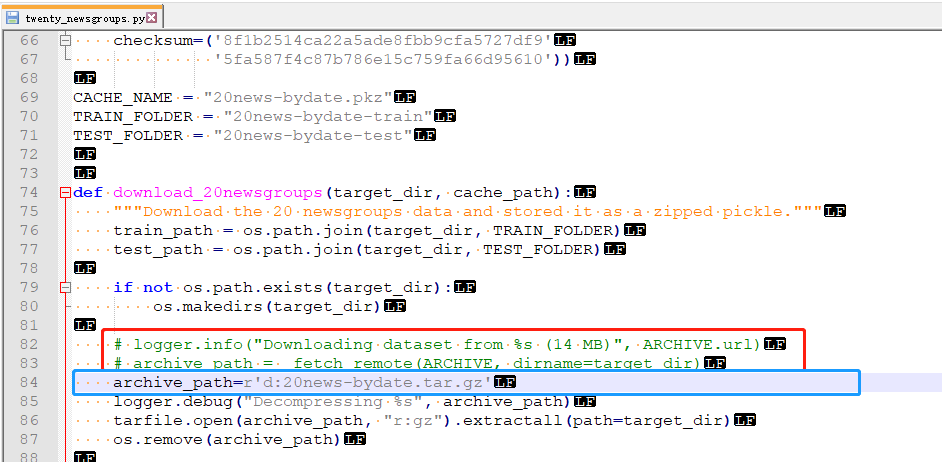
- 检查是否成功:如果在当前项目有如下路径则成功
Newsgroups数据集研究的更多相关文章
- Natural Language Generation/Abstractive Summarization
调研目的: 了解生成式文本摘要的常用技术和当前的发展趋势,明确当前项目有什么样的摘要需求,判断现有技术能否用于满足当前的需求,进一步明确毕业设计方向及其可行性 调研方向: 项目中需要用到摘要的地方以及 ...
- MLLib实践Naive Bayes
引言 本文基于Spark (1.5.0) ml库提供的pipeline完整地实践一次文本分类.pipeline将串联单词分割(tokenize).单词频数统计(TF),特征向量计算(TF-IDF),朴 ...
- 《mahout实战》
<mahout实战> 基本信息 原书名:Mahout in action 作者: (美)Sean Owen Robin Anil Ted Dunning Ellen Fr ...
- 2020厦门大学综述翻译:3D点云深度学习(Remote Sensiong期刊)
目录 摘要 1.引言: 2.点云深度学习的挑战 3.基于结构化网格的学习 3.1 基于体素 3.2 基于多视图 3.3 高维晶格 4.直接在点云上进行的深度学习 4.1 PointNet 4.2 局部 ...
- R语言重要数据集分析研究——需要整理分析阐明理念
1.R语言重要数据集分析研究需要整理分析阐明理念? 上一节讲了R语言作图,本节来讲讲当你拿到一个数据集的时候如何下手分析,数据分析的第一步,探索性数据分析. 统计量,即统计学里面关注的数据集的几个指标 ...
- R语言重要数据集分析研究——R语言数据集的字段含义
R语言数据集的字段含义 作者:马文敏 选择一种数据结构来储存数据 将数据输入或导入到这个数据结构中 数据集的概念 数据集通常是有数据结构的一个矩形数组,行表示规则,列表示变量. 不同的行业对数据集的行 ...
- R语言重要数据集分析研究—— 数据集本身的分析技巧
数据集本身的分析技巧 作者:王立敏 文章来源:网络 1.数据集 数据集,又称为资料集.数据集合或资料集合,是一种由数据所组成的集合. Data set(或dat ...
- R语言重要数据集分析研究——搞清数据的由来
搞清数据的由来 作者:李雪丽 资料来源:百度百科
- [转]最好用的 AI 开源数据集 Top 39:NLP、语音等 6 大类
原文链接 本文修正部分错误. 以下是精心收集的一些非常好的开放数据集,也是做 AI 研究不容错过的数据集. 标签解释 [经典]这些是在 AI 领域中非常著名.众所周知的数据集.很少有研究者或工程师没有 ...
随机推荐
- CTR点击率校准
1. 概述 广告CTR预估过程中,正负样本比例差距较大,需要采样,但是采用后模型训练的结果是有偏的. 2. 校准方式 用逻辑回归作为激活函数
- mysql——插入、更新、删除数据(示例)
插入数据 一.前提,新建表: ), sname ), sage ), ssex ) ); select * from student; 二.多种方式插入数据: ','zhaolei','1990-01 ...
- Laravel 查询&数据库&模型
1.with()与load区别: 都称为 延迟预加载,不同点在于 load()是在已经查询出来的模型上调用,而 with() 则是在 ORM 查询构造器上调用. Order::query()-> ...
- POP与OOP编程模式对比
面向过程:(procedure oriented programming 即:POP) 代表:C/C++ 向过程程序设计,它是以功能为中心来进行思考和组织的一种编程方式,强调的是系统的数据被加工和处理 ...
- Java小知识-----Map 按Key排序和按Value排序
Map排序的方式有很多种,这里记录下自己总结的两种比较常用的方式:按键排序(sort by key), 按值排序(sort by value). 1.按键排序 jdk内置的java.util包下的Tr ...
- GS7 安装使用Oracle19c 客户端的说明
1. 最近Oracle放出了 windows版本的oracle19c的安装文件(具体时间不详, 自己知道的时候比较晚了) 2. 发现文件其实比较多如图示: 3. 经过自己测试实现发现 不能使用 如下 ...
- springboot整合springdatajpa时jar冲突
1.springboot整合springdatajpa测试时报No bean named 'entityManagerFactory' available错误 2.运行springboot主程序时报以 ...
- 【计算机网络】-介质访问子层-(信道划分介质访问控制&随机访问介质访问控制)
[计算机网络]-介质访问子层-概述 介质访问控制子层功能 解决信道争用的协议,即用于多路访问信道上确定下一个使用者的协议 是数据链路层协议的一部分 介质访问控制子层位置 位于数据链路层的底部! 信道分 ...
- linux 三剑客之awk总结
AWK 1.begin end使用 cat /tmp/passwd |awk -F ':' 'BEGIN {print "hello"} {print $1"\t&quo ...
- 程序员必备的网站之Tutorialspoint
程序员必备的网站之Tutorialspoint 给大家介绍一个非常好的网站Tutorialspointhttp://www.tutorialspoint.com/index.htm,也许好多人都已经用 ...