大数据笔记(三)——Hadoop2.0的安装与配置
一.Hadoop安装部署的预备条件
准备:1、安装Linux和JDK。
安装JDK
解压:tar -zxvf jdk-8u144-linux-x64.tar.gz -C ~/training/
设置环境变量:vi ~/.bash_profile
JAVA_HOME=/root/training/jdk1.8.0_144
export JAVA_HOME PATH=$JAVA_HOME/bin:$PATH
export PATH 生效环境变量: source ~/.bash_profile
2、关闭防火墙
查看防火墙的状态:systemctl status firewalld.service
关闭防火墙: systemctl stop firewalld.service
禁用防火墙(永久)systemctl disable firewalld.service
3、配置主机名
输入:vi /etc/hosts,回车
192.168.153.11 bigdata11
解压hadoop:tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
设置环境变量:vi ~/.bash_profile
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
source ~/.bash_profile
二.Hadoop的目录结构
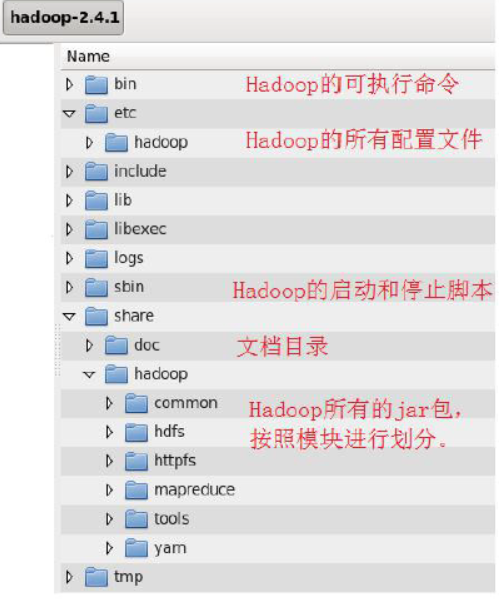
三.Hadoop安装部署的三种模式
1.本地模式
2.伪分布模式
3.全分布模式
| 本地模式的配置 | ||
| 参数文件 | 配置参数 | 参考值 |
| hadoop-env.sh | JAVA_HOME | /root/training/jdk1.8.0_144 |
本地模式 一台Linux
(*)特点:没有HDFS,只能测试MapReduce程序(本地数据:Linux的文件)
(*)配置:hadoop-env.sh
26行 export JAVA_HOME=/root/training/jdk1.8.0_144
(*)Demo:测试MapReduce程序
example: /root/training/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount ~/temp/data.txt ~/temp/mr/wc1
| 伪分布模式的配置 | ||
| 参数文件 | 配置参数 | 参考值 |
| hadoop-env.sh | JAVA_HOME | /root/training/jdk1.8.0_144 |
| hdfs-site.xml | dfs.replication | |
| dfs.permissions | false | |
| core-site.xml | fs.defaultFS | hdfs://<hostname>:9000 |
| hadoop.tmp.dir | /root/training/hadoop-2.7.3/tmp | |
| mapred-site.xml | mapreduce.framework.name | yarn |
| yarn-site.xml | yarn.resourcemanager.hostname | <hostname> |
| yarn.nodemanager.aux-services | mapreduce_shuffle | |
伪分布模式 一台Linux
(*)特点:在单机上,模拟一个分布式的环境,具备Hadoop的所有功能
(*)hdfs-site.xml <!--数据块的冗余度,默认是3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <!--是否开启HDFS的权限检查,默认:true-->
<!--
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
--> core-site.xml
<!--NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata11:9000</value>
</property> <!--HDFS数据保存的目录,默认是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property> mapred-site.xml
<!--MR程序运行的容器是Yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> yarn-site.xml
<!--ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata11</value>
</property> <!--NodeManager运行MR任务的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
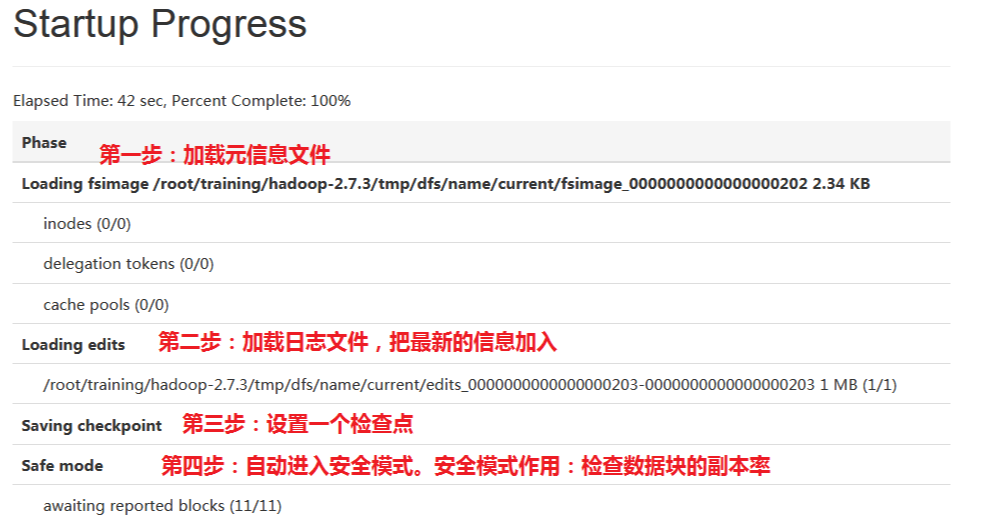
</property> 对NameNode进行格式化: hdfs namenode -format
日志:Storage directory /root/training/hadoop-2.7.3/tmp/dfs/name has been successfully formatted. 启动:start-all.sh = start-dfs.sh + start-yarn.sh
| 全分布模式的配置 | ||
| 参数文件 | 配置参数 | 参考值 |
| hadoop-env.sh | JAVA_HOME | /root/training/jdk1.8.0_144 |
| hdfs-site.xml | dfs.replication | |
| dfs.permissions | false | |
| core-site.xml | fs.defaultFS | hdfs://<hostname>:9000 |
| hadoop.tmp.dir | /root/training/hadoop-2.7.3/tmp | |
| mapred-site.xml | mapreduce.framework.name | yarn |
| yarn-site.xml | yarn.resourcemanager.hostname | <hostname> |
| yarn.nodemanager.aux-services | mapreduce_shuffle | |
| slaves | DataNode的地址 | 从节点1、从节点2 |
全分布模式安装详解
1、三台机器:bigdata12 bigdata13 bigdata14
2、每台机器准备工作:
a.安装JDK
b.关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
c.设置主机名: vi /etc/hosts
192.168.153.12 bigdata12
192.168.153.13 bigdata13
192.168.153.14 bigdata14
如果出现以下警告信息


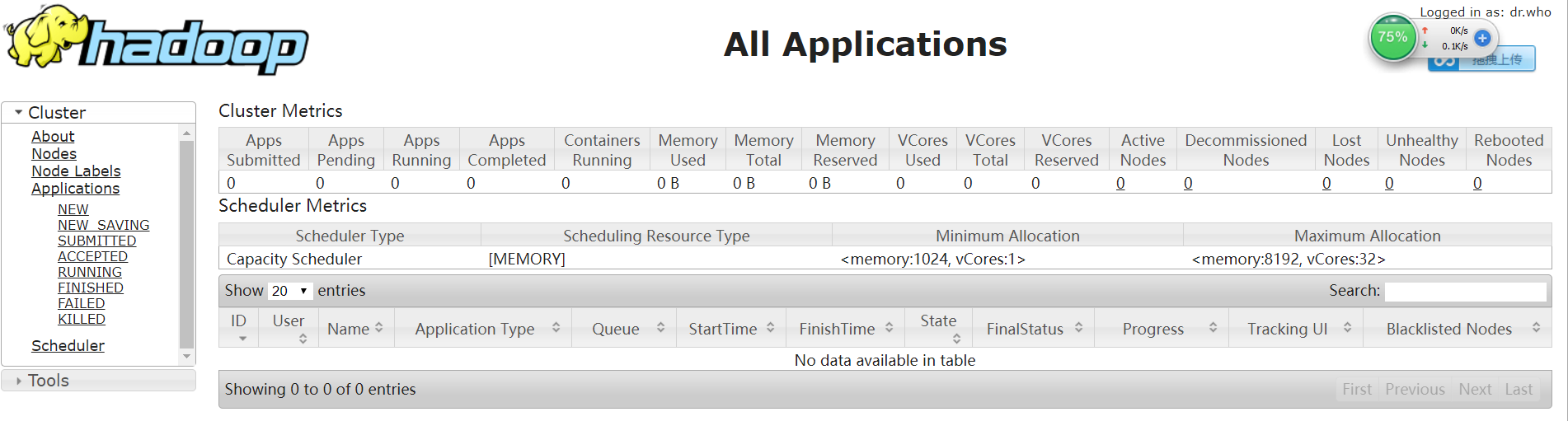
四.验证Hadoop环境
HDFS Console: http://192.168.153.11:50070
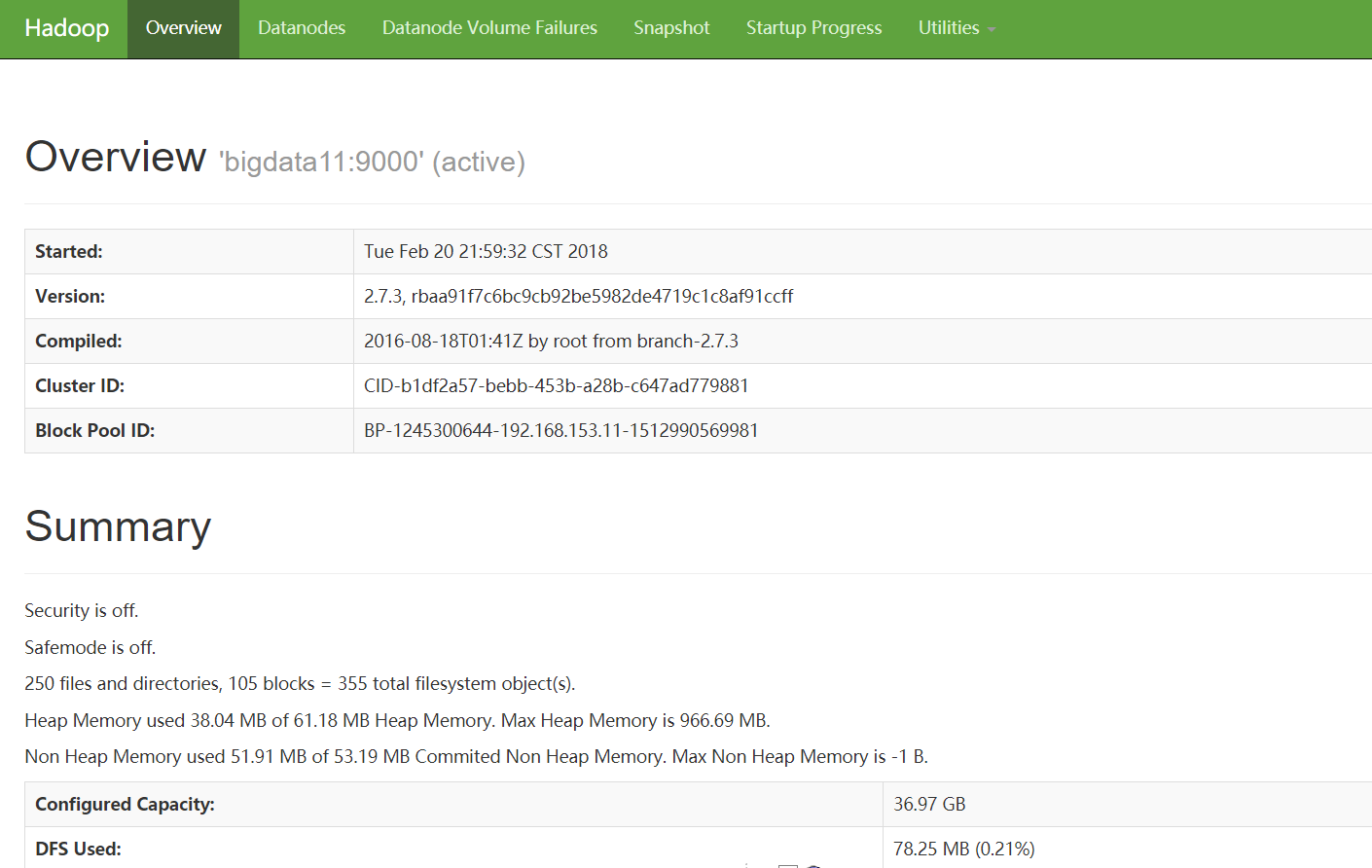
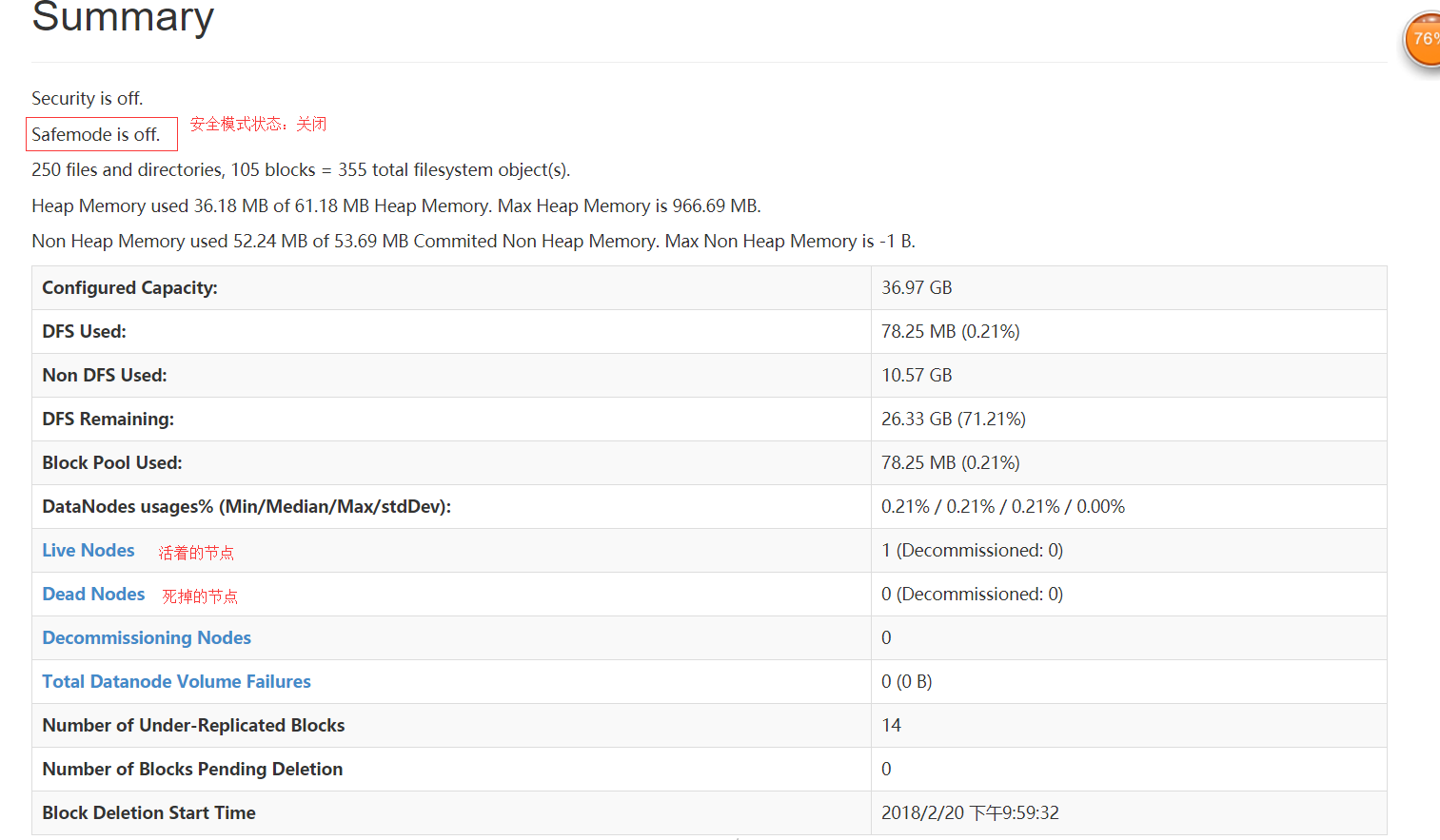
正常情况下,安全模式是关闭的。因为安全模式下,HDFS是只读
Yarn Console: http://192.168.153.11:8088
3.配置SSH免密码登录
(1)在每台机器上产生公钥和私钥
ssh-keygen -t rsa
(2)需要将每台机器的公钥复制给其他机器(下面的三句话,需要在每台机器上执行)
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata12
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata13
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata14
4、保证每台机器的时间同步的
5、安装Hadoop的全分布环境(在主节点bigdata12上安装)
(1)解压设置环境变量
(2)修改配置文件
hadoop-env.sh
26行 export JAVA_HOME=/root/training/jdk1.8.0_144
hdfs-site.xml
<!--数据块的冗余度,默认是3-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property> <!--是否开启HDFS的权限检查,默认:true-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
core-site.xml
<!--NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata12:9000</value>
</property> <!--HDFS数据保存的目录,默认是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
mapred-site.xml
<!--MR程序运行的容器是Yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<!--ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata12</value>
</property> <!--NodeManager运行MR任务的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
slaves: 配置的是所有的从节点
bigdata13
bigdata14
(3)格式化NameNode:
hdfs namenode -format
6、将配置好的目录复制到bigdata13和bigdata14上
scp -r hadoop-2.7.3/ root@bigdata13:/root/training
scp -r hadoop-2.7.3/ root@bigdata14:/root/training
7、启动Hadoop集群(在主节点上):
start-all.sh
关闭:stop-all.sh
8、验证
(*)命令行:hdfs dfsadmin -report
(*)网页:HDFS:http://192.168.153.12:50070/
Yarn:http://192.168.153.12:8088
大数据笔记(三)——Hadoop2.0的安装与配置的更多相关文章
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据之路day01_1--Java下载、安装等配置
从今天开始,我就正式的走上大数据的道路了,如果说我为啥要去学习大数据,可能我的初衷是以后可以接触到人工智能方面的技术,后来在自学的过程中发现,学习人工智能,需要扎实的算法,以及对大量数据的处理,再者, ...
- 【大数据系列】hadoop2.0中的jobtracker和tasktracker哪里去了
低版本的hadoop下MapReduce处理流程 1.首先用户程序(JobClient)提交了一个job,job的信息会发送到Job Tracker,Job Tracker是Map-reduce框架的 ...
- 大数据高可用集群环境安装与配置(08)——安装Ganglia监控集群
1. 安装依赖包和软件 在所有服务器上输入命令进行安装操作 yum install epel-release -y yum install ganglia-web ganglia-gmetad gan ...
- 大数据高可用集群环境安装与配置(07)——安装HBase高可用集群
1. 下载安装包 登录官网获取HBase安装包下载地址 https://hbase.apache.org/downloads.html 2. 执行命令下载并安装 cd /usr/local/src/ ...
- 大数据高可用集群环境安装与配置(06)——安装Hadoop高可用集群
下载Hadoop安装包 登录 https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ 镜像站,找到我们要安装的版本,点击进去复制下载链接 ...
- 大数据高可用集群环境安装与配置(09)——安装Spark高可用集群
1. 获取spark下载链接 登录官网:http://spark.apache.org/downloads.html 选择要下载的版本 2. 执行命令下载并安装 cd /usr/local/src/ ...
- 大数据高可用集群环境安装与配置(02)——配置ntp服务
NTP服务概述 NTP服务器[Network Time Protocol(NTP)]是用来使计算机时间同步化的一种协议,它可以使计算机对其服务器或时钟源(如石英钟,GPS等等)做同步化,它可以提供高精 ...
- 大数据高可用集群环境安装与配置(10)——安装Kafka高可用集群
1. 获取安装包下载链接 访问https://kafka.apache.org/downloads 找到kafka对应版本 需要与服务器安装的scala版本一致(运行spark-shell可以看到当前 ...
随机推荐
- windows下安装mysql8并修改密码
MySQL下载地址:http://dev.mysql.com/downloads/mysql/ Windows下安装MySQL 我下的是最新版的MySQL,解压后,目录如下: 1.进入dos的命令行, ...
- LINUX之启动流程
(上图片转自一位高手所做) 启动第一步--加载BIOS当你打开计算机电源,计算机会首先加载BIOS信息,BIOS信息是如此的重要,以至于计算机必须在最开始就找到它.这是因为BIOS中包含了CPU的相关 ...
- oracle 实现mysql find_set_in函数
create or replace FUNCTION F_FIND_IN_SET(piv_str1 varchar2, piv_str2 varchar2, p_sep varchar2 := ',' ...
- php读取excel文件并导入数据库(表头任意设定)
最近收到一个很奇葩的需求,要求上传excel员工工资表,表格表头不固定,导入后字段名为表头的拼音,每月导入一次,当月重复导入则覆盖现有的当月表头,并且可以按照在界面上按照月份筛选显示,我写的代码主要包 ...
- PHP排序函数sort、rsort、asort、arsort、ksort、krsort
1.sort函数用于对数组元素值从低到高排序,去除原始索引元素,重新生成0,1,2..的键2.rsort函数用于对数组元素值从高到低排序,去除原始索引元素,重新生成0,1,2..的键3.asort函数 ...
- Building and booting Nexus 5 kernel
1. Downloading toolchain and setup. git clone https://android.googlesource.com/platform/prebuilts/gc ...
- Vue双向绑定的实现原理及简单实现
vue数据双向绑定原理 vue数据双向绑定是通过(数据劫持)+(发布者-订阅者模式)的方式来实现的,而所谓的数据劫持就是通过Object.defineProperty() 来实现的,所谓的Obje ...
- Kibana 基本操作
es中的索引对应mysql的数据库.类型对应mysql的表.文档对应mysql的记录.映射对应mysql的索引索引:index类型:type映射:mappings 1.创建索引在kibana的Dev ...
- java 技术分享
http://www.ccblog.cn/99.htm http://www.ccblog.cn/100.htm http://www.ccblog.cn/101.htm http://www.ccb ...
- PAT Advanced 1036 Boys vs Girls (25 分)
This time you are asked to tell the difference between the lowest grade of all the male students and ...