WebMagic 抓取图片并保存至本地
1.近期接触到java 爬虫,开源的爬虫框架有很多,其中WebMagic 是国产的,文档也是中文的,网上资料很多,便于学习,功能强大,可以在很短时间内实现一个简单的网络爬虫。具体可参考官网 http://webmagic.io/docs/zh/。今天参考官网和网上资料实现了抓取网页图片,并保存在本地简单入门实例,日后再做进一步深入探讨。在实现过程中参考了一些网上资料,主要是理解原理和工作方式。
2.分析网页结构。我们抓的是http://www.win4000.com/ 这个网站的图片,我们进到高清壁纸图库
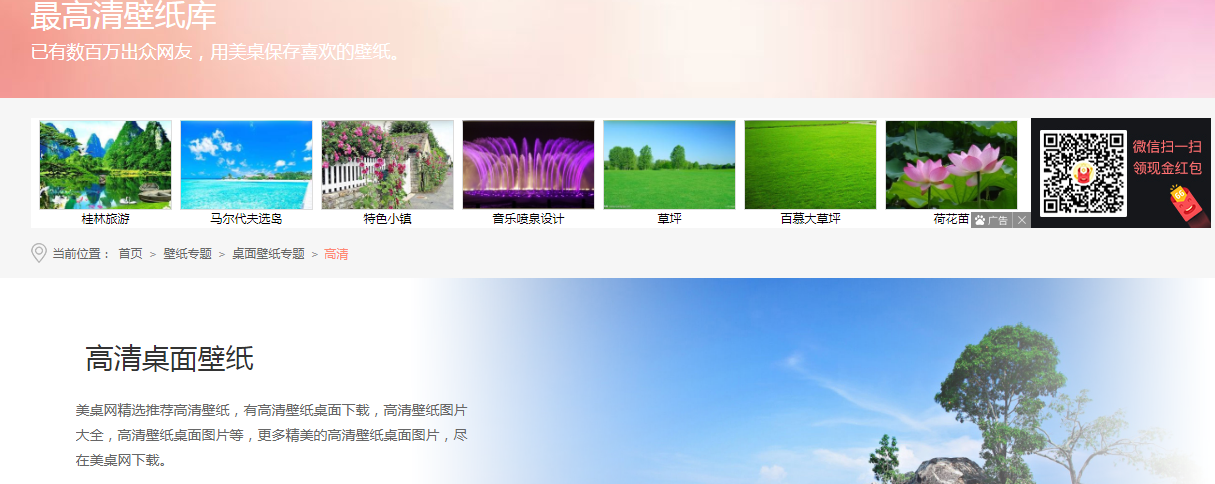
找到要抓的图片,按F12进入调试模式
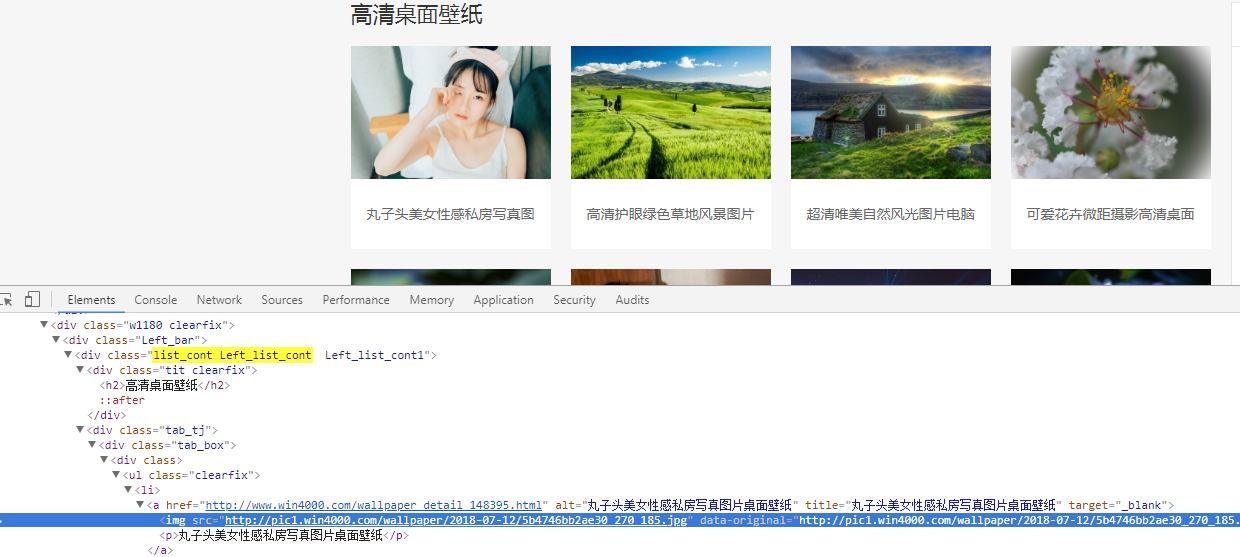
我们要抓的图片都在 class 为clearfix 的ui标签下的li标签内的a标签内,a标签的连接地址为图片的详情,计入详情页找到图片的具体地址和标题的地址
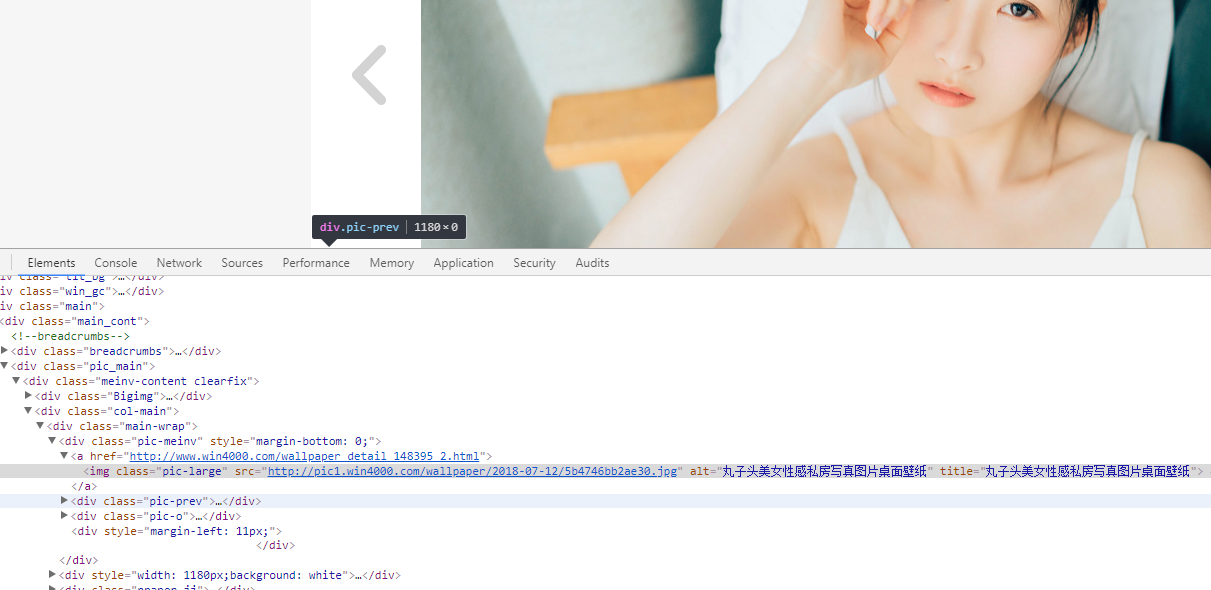

本次只是了解基本实现方式。具体筛选图片链接和标题请查看代码。可参考官网selecttable 和Jsoup章节。下面开始写代码实现。对于有翻页的情况,在第一页的时候获取最大页码,将所有的请求添加至请求队列,并重命名图片名称。下面的截图是原来的实现的时候放的,图片就不换了,效果是一样的,代码已经替换。
3.利用webMagic构建一个简单的网络爬虫很简单,首先添加webMagic依赖,主要是两个核心jar包
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
其中webmagic核心部分,只包含爬虫基本模块和基本抽取器。webmagic的扩展模块,提供一些更方便的编写爬虫的工具。另外还有其他扩展模块,具体请查看百度百科介绍https://baike.baidu.com/item/WebMagic/22066484
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
如果没有使用Maven,自行下载Jar包后添加至lib即可。
具体实现如下,实现PageProcessor即可。
public class myImageProcess implements PageProcessor{
//页面URL的正则表达式
//.是匹配所有的字符,//.表示只匹配一个,//.?同理
private static String REGEX_PAGE_URL = "http://www\\.win4000\\.com/zt/gaoqing_\\w+.html";
//爬取的页数
public static int PAGE_SIZE = 6;
//下载张数
public static int INDEX_PHOTO =1;
public void process(Page page) {
List<String> SpidertURL = new ArrayList<String>();
for (int i = 2; i < PAGE_SIZE; i++){//添加到目标url中
SpidertURL.add("http://www.win4000.com/zt/gaoqing_" + i + ".html");
}
//添加url到请求中
page.addTargetRequests(SpidertURL);
//是图片列表页面
System.out.println(page.getUrl());
if (page.getUrl().regex(REGEX_PAGE_URL).match()) {
//获得所有详情页的连接
//page.getHtml().xpath("//a[@class=\"title\"]").links().all();
List<String> detailURL = page.getHtml().xpath("//ul[@class='clearfix']/li/a").links().all();
int x = 1;
for (String str:detailURL){//输出所有连接
System.out.println(x+"----"+str);
x++;
}
page.addTargetRequests(detailURL);
} else {//详情页
String detailUrl = page.getUrl().toString();
System.out.println(detailUrl);
String picURL = page.getHtml().xpath("//div[@class='pic-meinv']/a").css("img", "src").toString();
System.out.println(picURL);
String currentIndex = page.getHtml().xpath("//div[@class='ptitle']/span/text()").toString();
String picname = page.getHtml().xpath("//div[@class='ptitle']/h1/text()").toString();
if(!"1".equals(currentIndex)){//如果不是第一页,则图片名称加上页码顺序
picname = picname+"_"+StringUtil.getURLIndex(detailUrl);
}
String allPic = page.getHtml().xpath("//div[@class='ptitle']/em/text()").toString();
if(allPic!= null && picURL != null && "1".equals(currentIndex)){
Integer pageindex = Integer.parseInt(allPic);
List<String>otherPic = new ArrayList<String>();
for(int i=2;i<=pageindex;i++){
otherPic.add(detailUrl.replaceAll(".html", "_"+i+".html"));
}
page.addTargetRequests(otherPic);
}
System.out.println(picname);
try {
/**
* String 图片地址
* String 图片名称
* String 保存路径
*/
if(picURL !=null){
DownloadUtil.download( picURL, picname + ".jpg", "E:\\image3\\");
System.out.println("第"+(INDEX_PHOTO++)+"张");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
public Site getSite() {
return Site.me();
}
public static void main(String [] args) throws JMException{
Date stdate = new Date();
System.out.println("开始时间:"+new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(stdate));
Spider picSpider = Spider.create(new myImageProcess()).addUrl("http://www.win4000.com/zt/gaoqing_1.html")
.thread(5);
SpiderMonitor.instance().register(picSpider);
picSpider.start();
Date edDate = new Date();
System.out.println("结束时间:"+new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(edDate));
System.out.println("共耗时"+(edDate.getTime()-stdate.getTime())/1000/60+"分钟");
}
}
直接运行即可执行上面的main方法。至于还能用来抓什么,可自行体会。
5.抓取结果。

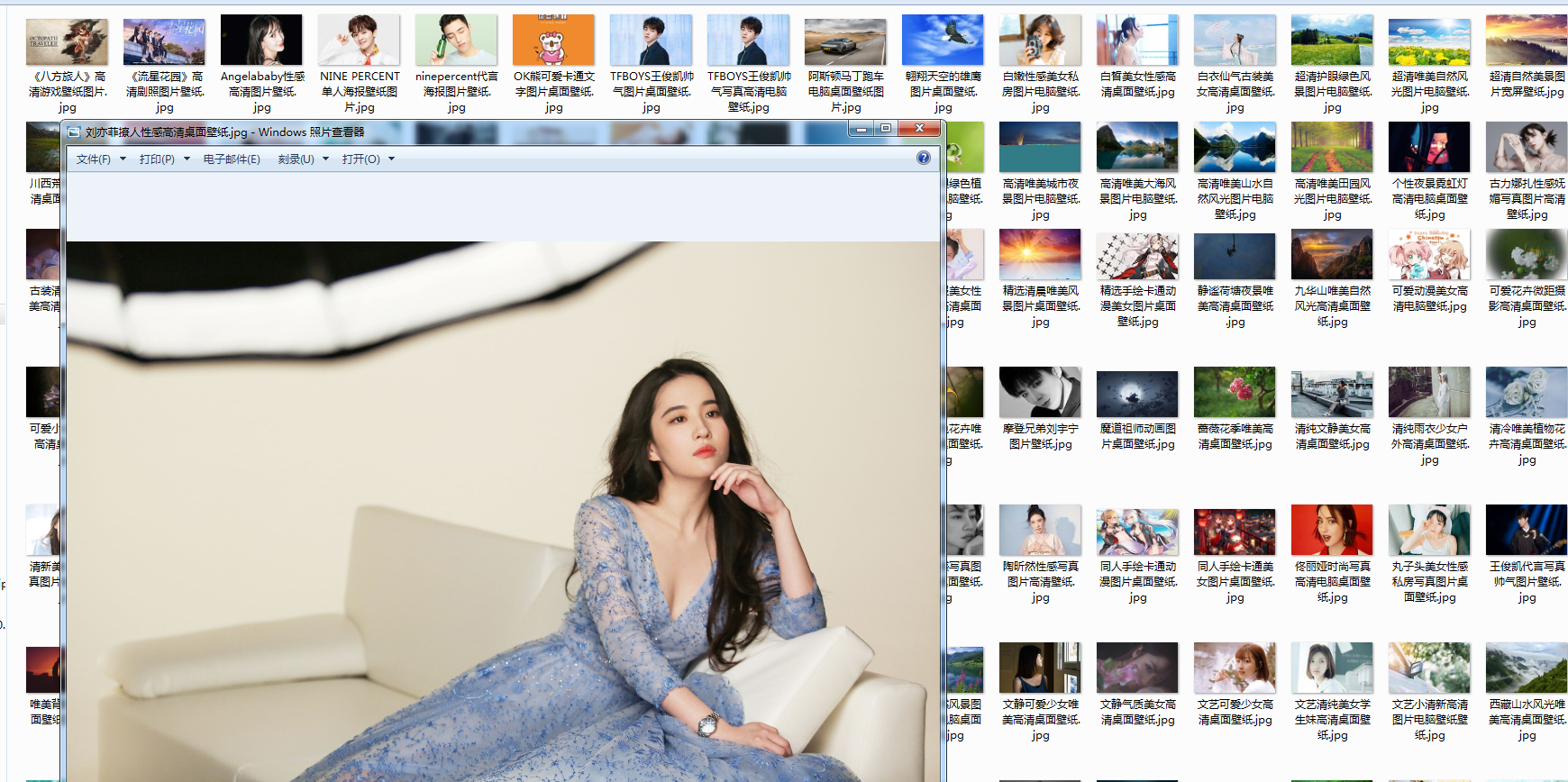
继续学习,以后可以用来抓点好东西!!!!
暂时写到这里,后面继续完善。
WebMagic 抓取图片并保存至本地的更多相关文章
- C#抓取网络图片保存到本地
C#抓取网络图片保存到本地 System.Net.WebClient myWebClient = new System.Net.WebClient(); //将头像保存到服务器 string virP ...
- 使用原生php爬取图片并保存到本地
通过一个简单的例子复习一下几个php函数的用法 用到的函数或知识点 curl 发送网络请求 preg_match 正则匹配 代码 $url = 'http://desk.zol.com.cn/bizh ...
- node.js抓取网上图片保存到本地
用到两个模块,http和fs var http = require("http");var fs = require("fs"); var server = h ...
- [分享黑科技]纯js突破localstorage存储上线,远程抓取图片,并转码base64保存本地,最终实现整个网站所有静态资源离线到用户手机效果却不依赖浏览器的缓存机制,单页应用最新黑科技
好久没有写博客了,想到2年前答应要放出源代码的也没放出来,最近终于有空先把纯js实现无限空间大小的本地存储的功能开源了,项目地址https://github.com/xueduany/localsto ...
- 下载远程(第三方服务器)文件、图片,保存到本地(服务器)的方法、保存抓取远程文件、图片 将图片的二进制字节字符串在HTML页面以图片形式输出 asp.net 文件 操作方法
下载远程(第三方服务器)文件.图片,保存到本地(服务器)的方法.保存抓取远程文件.图片 将一台服务器的文件.图片,保存(下载)到另外一台服务器进行保存的方法: 1 #region 图片下载 2 3 ...
- scrapy爬虫系列之三--爬取图片保存到本地
功能点:如何爬取图片,并保存到本地 爬取网站:斗鱼主播 完整代码:https://files.cnblogs.com/files/bookwed/Douyu.zip 主要代码: douyu.py im ...
- 使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地 上 篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy 目标: 爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地 好了不多说,让我们实 ...
- 一文搞定scrapy爬取众多知名技术博客文章保存到本地数据库,包含:cnblog、csdn、51cto、itpub、jobbole、oschina等
本文旨在通过爬取一系列博客网站技术文章的实践,介绍一下scrapy这个python语言中强大的整站爬虫框架的使用.各位童鞋可不要用来干坏事哦,这些技术博客平台也是为了让我们大家更方便的交流.学习.提高 ...
- pymysql 使用twisted异步插入数据库:基于crawlspider爬取内容保存到本地mysql数据库
本文的前提是实现了整站内容的抓取,然后把抓取的内容保存到数据库. 可以参考另一篇已经实现整站抓取的文章:Scrapy 使用CrawlSpider整站抓取文章内容实现 本文也是基于这篇文章代码基础上实现 ...
随机推荐
- SessionState的几种设置
SessionState: web Form 网页是基于HTTP的,它们没有状态, 这意味着它们不知道所有的请求是否来自同一台客户端计算机,网页是受到了破坏,以及是否得到了刷新,这样就可能造成信息 ...
- Springboot 解决跨域请求
Cors处理 跨域请求 细粒度 直接在controller层上 添加@CrossOrigin注解 @PostMapping("/") @CrossOrigin(value = &q ...
- nopCommerce4.10学习笔记——入门
1.下载 千万不要去GitHub上下载,千万不要去GitHub上下载,千万不要去GitHub上下载!!!,重要的事情说3遍,说多了都是泪,你懂的 下载网址:https://www.nopcommerc ...
- nginx 与location语法详解
Location语法优先级排列 匹配符 匹配规则 优先级 = 精确匹配 1 ^~ 以某个字符串开头 2 ~ 区分大小写的正则匹配 3 ~* 不区分大小写的正则匹配 4 !~ 区分大小写不匹配的正则 ...
- MariaDB 默认是禁止远程访问的 我们改掉它
查询用户账号信息: select User, host from mysql.user; 现在只显示 root账户中的host项是localhost表示该账号只能进行本地登录,我们需要修改权限,输入 ...
- 选题 Scrum立会报告+燃尽图 05
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2019fall/homework/8749 一.小组情况组长:贺敬文组员:彭思雨 王志文 位军营 杨萍队名:胜 ...
- python第一个程序:计算体脂率
主要是为了提醒自己要——保重 height = input('请输入身高(m):') weight = input('请输入体重(KG):') age = input('请输入年龄:') sex = ...
- 一、基础篇--1.1Java基础-hashCode和equals方法的区别和联系
hashCode和equals方法的区别和联系 两个方法的定义 equals(Object obj)方法用来判断两个对象是否"相同",如果"相同"则返回tr ...
- 远程连接mysql要点 虚拟主机定义与分类
远程连接mysql:通过主机地址与端口号连接 1. 主机地址:找到主机电脑 2. 端口号:找到对应mysql软件 mysql客户端访问服务端需要进行寻找匹配:连接认证-h 主机地址 例如 -hloca ...
- web开发(七) JSTL标签库
在网上看见一篇不错的文章,写的详细. 以下内容引用那篇博文.转载于<http://www.cnblogs.com/whgk/p/6432786.html>,在此仅供学习参考之用. 一.为什 ...