[原创] Trie树 php 实现敏感词过滤
背景
项目中需要过滤用户发送的聊天文本, 由于敏感词有将近2W条, 如果用 str_replace 来处理会炸掉的.
网上了解了一下, 在性能要求不高的情况下, 可以自行构造 Trie树(字典树), 这就是本文的由来.
简介
Trie树是一种搜索树, 也叫字典树、单词查找树.
DFA可以理解为DFA(Deterministic Finite Automaton), 即
这里借用一张图来解释Trie树的结构:
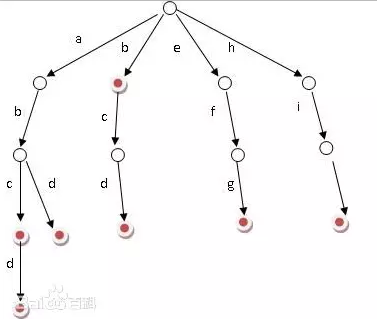
Trie可以理解为确定有限状态自动机,即DFA。在Trie树中,每个节点表示一个状态,每条边表示一个字符,从根节点到叶子节点经过的边即表示一个词条。查找一个词条最多耗费的时间只受词条长度影响,因此Trie的查找性能是很高的,跟哈希算法的性能相当。
上面实际保存了
abcd
abd
b
bcd
efg
hij
特点:
- 所有词条的公共前缀只存储一份
- 只需遍历一次待检测文本
- 查找消耗时间只跟待检测文本长度有关, 跟字典大小无关
存储结构
PHP
在PHP中, 可以很方便地使用数组来存储树形结构, 以以下敏感词字典为例:
大傻子
大傻
傻子
↑ 内容纯粹是为了举例...游戏聊天日常屏蔽内容
则存储结构为
{
"大": {
"傻": {
"end": true
"子": {
"end": true
}
}
},
"傻": {
"子": {
"end": true
},
}
}
其他语言
简单点的可以考虑使用 HashMap 之类的来实现
或者参考 这篇文章 , 使用 Four-Array Trie,Triple-Array Trie和Double-Array Trie 结构来设计(名称与内部使用的数组个数有关)
字符串分割
无论是在构造字典树或过滤敏感文本时, 都需要将其分割, 需要考虑到unicode字符
有一个简单的方法:
$str = "a笨蛋123"; // 待分割的文本
$arr = preg_split("//u", $str, -1, PREG_SPLIT_NO_EMPTY); // 分割后的文本
// 输出
array(6) {
[0]=>
string(1) "a"
[1]=>
string(3) "笨"
[2]=>
string(3) "蛋"
[3]=>
string(1) "1"
[4]=>
string(1) "2"
[5]=>
string(1) "3"
}
匹配规则需加
u修饰符,/u表示按unicode(utf-8)匹配(主要针对多字节比如汉字), 否则会无法正常工作, 如下示例 ↓$str = "a笨蛋123"; // 待分割的文本
$arr = preg_split("//", $str, -1, PREG_SPLIT_NO_EMPTY); // 分割后的文本
// array(10) {
[0]=>
string(1) "a"
[1]=>
string(1) "�"
[2]=>
string(1) "�"
[3]=>
string(1) "�"
[4]=>
string(1) "�"
[5]=>
string(1) "�"
[6]=>
string(1) "�"
[7]=>
string(1) "1"
[8]=>
string(1) "2"
[9]=>
string(1) "3"
}
示例代码 php
构建:
1. 分割敏感词
2. 逐个将分割后的次添加到树中
使用:
- 分割待处理词句
- 从Trie树根节点开始逐个匹配
class SensitiveWordFilter
{
protected $dict;
protected $dictFile;
/**
* @param string $dictFile 字典文件路径, 每行一句
*/
public function __construct($dictFile)
{
$this->dictFile = $dictFile;
$this->dict = [];
}
public function loadData($cache = true)
{
$memcache = new Memcache();
$memcache->pconnect("127.0.0.1", 11212);
$cacheKey = __CLASS__ . "_" . md5($this->dictFile);
if ($cache && false !== ($this->dict = $memcache->get($cacheKey))) {
return;
}
$this->loadDataFromFile();
if ($cache) {
$memcache->set($cacheKey, $this->dict, null, 3600);
}
}
/**
* 从文件加载字典数据, 并构建 trie 树
*/
public function loadDataFromFile()
{
$file = $this->dictFile;
if (!file_exists($file)) {
throw new InvalidArgumentException("字典文件不存在");
}
$handle = @fopen($file, "r");
if (!is_resource($handle)) {
throw new RuntimeException("字典文件无法打开");
}
while (!feof($handle)) {
$line = fgets($handle);
if (empty($line)) {
continue;
}
$this->addWords(trim($line));
}
fclose($handle);
}
/**
* 分割文本(注意ascii占1个字节, unicode...)
*
* @param string $str
*
* @return string[]
*/
protected function splitStr($str)
{
return preg_split("//u", $str, -1, PREG_SPLIT_NO_EMPTY);
}
/**
* 往dict树中添加语句
*
* @param $wordArr
*/
protected function addWords($words)
{
$wordArr = $this->splitStr($words);
$curNode = &$this->dict;
foreach ($wordArr as $char) {
if (!isset($curNode)) {
$curNode[$char] = [];
}
$curNode = &$curNode[$char];
}
// 标记到达当前节点完整路径为"敏感词"
$curNode['end']++;
}
/**
* 过滤文本
*
* @param string $str 原始文本
* @param string $replace 敏感字替换字符
* @param int $skipDistance 严格程度: 检测时允许跳过的间隔
*
* @return string 返回过滤后的文本
*/
public function filter($str, $replace = '*', $skipDistance = 0)
{
$maxDistance = max($skipDistance, 0) + 1;
$strArr = $this->splitStr($str);
$length = count($strArr);
for ($i = 0; $i < $length; $i++) {
$char = $strArr[$i];
if (!isset($this->dict[$char])) {
continue;
}
$curNode = &$this->dict[$char];
$dist = 0;
$matchIndex = [$i];
for ($j = $i + 1; $j < $length && $dist < $maxDistance; $j++) {
if (!isset($curNode[$strArr[$j]])) {
$dist ++;
continue;
}
$matchIndex[] = $j;
$curNode = &$curNode[$strArr[$j]];
}
// 匹配
if (isset($curNode['end'])) {
// Log::Write("match ");
foreach ($matchIndex as $index) {
$strArr[$index] = $replace;
}
$i = max($matchIndex);
}
}
return implode('', $strArr);
}
/**
* 确认所给语句是否为敏感词
*
* @param $strArr
*
* @return bool|mixed
*/
public function isMatch($strArr)
{
$strArr = is_array($strArr) ? $strArr : $this->splitStr($strArr);
$curNode = &$this->dict;
foreach ($strArr as $char) {
if (!isset($curNode[$char])) {
return false;
}
}
// return $curNode['end'] ?? false; // php 7
return isset($curNode['end']) ? $curNode['end'] : false;
}
}
字典文件示例:
敏感词1
敏感词2
敏感词3
...
使用示例:
$filter = new SensitiveWordFilter(PATH_APP . '/config/dirty_words.txt');
$filter->loadData()
$filter->filter("测试123文本",'*', 2)
优化
缓存字典树
原始敏感词文件大小: 194KB(约20647行)
生成字典树后占用内存(约): 7MB
构建字典树消耗时间: 140ms+ !!!
php 的内存占用这点...先放着
构建字典树消耗时间这点是可以优化的: 缓存!
由于php脚本不是常驻内存类型, 每次新的请求到来时都需要构建字典树.
我们通过将生成好的字典树数组缓存(memcached 或 redis), 在后续请求中每次都从缓存中读取, 可以大大提高性能.
经过测试, 构建字典树的时间从 140ms+ 降低到 6ms 不到,
注意:
- memcached 默认会自动序列化缓存的数组(serialize), 取出时自动反序列化(unserialize)
- 若是redis, 则需要手动, 可选择 json 存取
序列化上述生成的Trie数组后的字符长度:
- serialize: 426KB
- json: 241KB
提示: 因此若整个字典过大, 导致存入memcached时超出单个value大小限制时(默认是1M), 可以考虑手动 json 序列化数组再保存.
↑ ...刚发现memcache存入value时提供压缩功能, 可以考虑使用
常驻服务
若是将过滤敏感字功能独立为一个常驻内存的服务, 则构建字典树这个过程只需要1次, 后续值需要处理过滤文本的请求即可.
如果是PHP, 可以考虑使用 Swoole
由于项目当前敏感词词库仅2W条左右, 而且访问瓶颈并不在此, 因此暂时使用上述方案.
ab测试时单个
若是词库达上百万条, 那估计得考虑一下弄成常驻内存的服务了
这里有一篇 文章 测试了使用 Swoole(
swoole_http_server) + trie-filter 扩展, 词库量级200W
参考文章
关键词过滤扩展,用于检查一段文本中是否出现敏感词,基于Double-Array Trie 树实现
↑ 现成的php扩展, 同时支持 php5、php7
-
↑ 深入浅出讲解
trie_filter扩展 + swoole 实现敏感词过滤
↑ 简单的php高性能实现方式
[原创] Trie树 php 实现敏感词过滤的更多相关文章
- Trie性能分析之敏感词过滤golang
package util import ( "strings" ) type Node struct { //rune表示一个utf8字符 char rune Data inter ...
- 字典树Trie--实现敏感词过滤
序言 Trie树 资料 https://blog.csdn.net/m0_37907797/article/details/103272967?utm_source=apphttps://blog.c ...
- 转,敏感词过滤,PHP实现的Trie树
原文地址:http://blog.11034.org/2012-07/trie_in_php.html 项目需求,要做敏感词过滤,对于敏感词本身就是一个CRUD的模块很简单,比较麻烦的就是对各种输入的 ...
- [转载]敏感词过滤,PHP实现的Trie树
原文地址:http://blog.11034.org/2012-07/trie_in_php.html 项目需求,要做敏感词过滤,对于敏感词本身就是一个CRUD的模块很简单,比较麻烦的就是对各种输入的 ...
- DFA和trie特里实现敏感词过滤(python和c语言)
今天的项目是与完成python开展,需要使用做关键词检查,筛选分类,使用前c语言做这种事情.有了线索,非常高效,内存小了,检查快. 到达python在,第一个想法是pip基于外观的c语言python特 ...
- 用php实现一个敏感词过滤功能
周末空余时间撸了一个敏感词过滤功能,下边记录下实现过程. 敏感词,一方面是你懂的,另一方面是我们自己可能也要过滤一些人身攻击或者广告信息等,具体词库可以google下,有很多. 过滤敏感词,使用简单的 ...
- 浅析敏感词过滤算法(C++)
为了提高查找效率,这里将敏感词用树形结构存储,每个节点有一个map成员,其映射关系为一个string对应一个TreeNode. STL::map是按照operator<比较判断元素是否相同,以及 ...
- 转:鏖战双十一-阿里直播平台面临的技术挑战(webSocket, 敏感词过滤等很不错)
转自:http://www.infoq.com/cn/articles/alibaba-broadcast-platform-technology-challenges 鏖战双十一-阿里直播平台面临的 ...
- Jsp敏感词过滤
Jsp敏感词过滤 大部分论坛.网站等,为了方便管理,都进行了关于敏感词的设定. 在多数网站,敏感词一般是指带有敏感政治倾向(或反执政党倾向).暴力倾向.不健康色彩的词或不文明语,也有一些网站根据自身实 ...
随机推荐
- mybatis与hibernate不同(重要)
Mybatis和hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句,不过mybatis可以通过XML或注解方式灵活配置要运行的sql语句,并将java对象 ...
- [Selenium]Click element under a hidden element
Description: Find out the DDL in Treegrid, but cannot click on it.Because the element is under a hid ...
- windows 如何创建.gitignore 文件 / .ssh 文件夹?解决windows必须键入文件名提示
windows不允许.gitignore之类的文件,也不允许.ssh命名的文件夹名.会提示必须输入文件名. 要解决这个问题我以前一直是通过bash使用linux命令创建的.最近发现了一个更简便的方法与 ...
- 视觉SLAM的数学基础 第一篇 3D空间的位置表示
视觉SLAM中的数学基础 第一篇 3D空间的位置表示 前言 转眼间一个学期又将过去,距离我上次写<一起做RGBD SLAM>已经半年之久.<一起做>系列反响很不错,主要由于它为 ...
- Ural 1519 Formula 1 (DP)
题意:给定一个 n * m 的矩阵,问你能花出多少条回路. #pragma comment(linker, "/STACK:1024000000,1024000000") #inc ...
- .bat文件打开指定网页,并运行jar包
@echo off Start "" "C:\Users\Lenovo\AppData\Local\Google\Chrome\Application\chrome.ex ...
- 23 DesignPatterns学习笔记:C++语言实现 --- 1.2 AbstractFactory
23 DesignPatterns学习笔记:C++语言实现 --- 1.2 AbstractFactory 2016-07-21 (www.cnblogs.com/icmzn) 模式理解
- Linux命令行下的vim文本编辑器
Linux命令行下的vim文本编辑器 下面这个网站的地址讲解的非成分清楚!!!! http://blog.csdn.net/niushuai666/article/details/7275406 学习 ...
- 洛谷P4556 [Vani有约会]雨天的尾巴(线段树合并)
题目背景 深绘里一直很讨厌雨天. 灼热的天气穿透了前半个夏天,后来一场大雨和随之而来的洪水,浇灭了一切. 虽然深绘里家乡的小村落对洪水有着顽固的抵抗力,但也倒了几座老房子,几棵老树被连根拔起,以及田地 ...
- 在定制工作项时,把“团队项目”作为变量获取生成版本信息
有用户最近提出这个需求: 通过工作项定制,新增一个字段用以保存项目Bug的"影响版本"信息,但是需要从当前团队项目的服务器生成纪录中获取版本的选项,类似默认模板中的"发现 ...