阅读AuTO利用深度强化学习自动优化数据中心流量工程(一)
Sigcomm'18
AuTO: Scaling Deep Reinforcement Learning for Datacenter-Scale Automatic Traffic Optimization
问题
主要问题:流量算法的配置周期长,人工配置难且繁复。人工配置的时间成本大,人为错误导致的性能降低。
要计算MLFQ的阈值参数是很麻烦的事情,先前有人构建了一个数学模型来优化这个阈值,在几个星期或者几个月更新一次阈值,更新周期过长。
可以使用DRL(Deep Reinforcement Learning)的方法根据环境自动配置(决策)算法参数,减少人工配置的时间成本,减少人为错误导致的性能降低。
基于主流框架TensorFlow或是pytorch等框架的的DRL难以掌控TO(traffic optimization)的小流(速度过快)
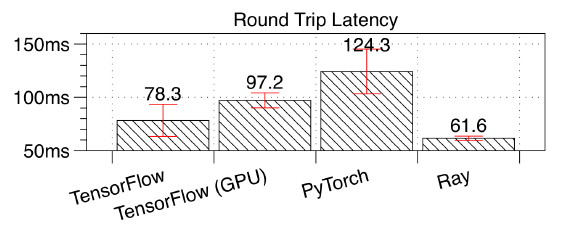
使用DRL优化时遇见的问题:DRL配置TO时,由于小流通过速度大于配置下发的速度,所以来不及下发配置。
解决方法
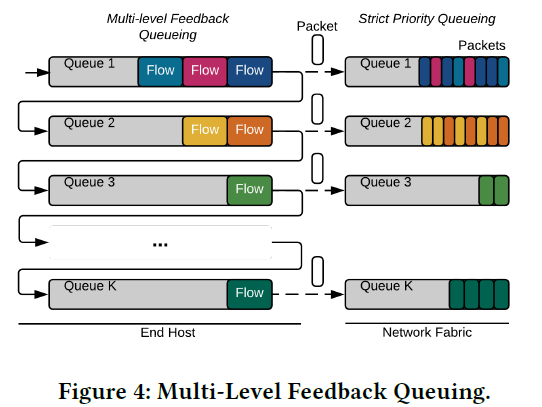
优化的算法:采用 Multi-Level Feedback Queueing(MLFQ)来管理流。第一级别的队列为小流,所有流初始化为小流。当流的大小超过阈值时,判定为大流,在队列中被降级到第二队列。可以有k个队列,按照流的不同级别分在不同的队列当中。
决策参数:基于比特数和阈值来对每个流做出决策,判定流属于第几级别的队列。
评价参数:当一次流处理完成时,计算一个比率,比率为本次的吞吐量与前一次的吞吐量之比。 吞吐量Sizef(流长)与FCT(Flow completion time)之比。
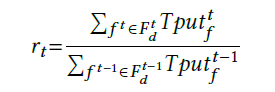
使用DRL优化:使用强化学习优化阈值。根据结果反馈调整阈值的设定。
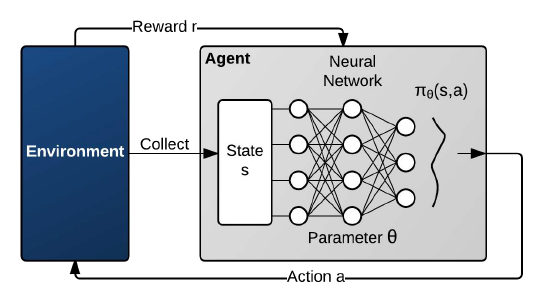
状态和奖励返回是随机的马尔科夫过程
模型选择
公式一

公式一的改进:公式二
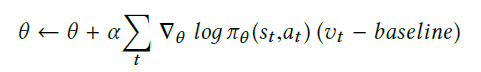
算法主要使用公式二
算法

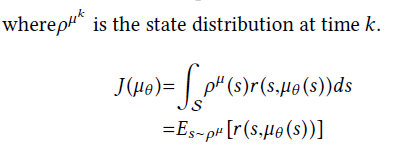
论文从强化学习的算法PG讲到DPG再讲到DDPG,最后使用了DDPG。
经过查询资料,DDPG使用了深度神经网络,并且针对的是决策值为连续的情况,而参数值的变化又是连续的,所以使用DDPG较为合适且有效。
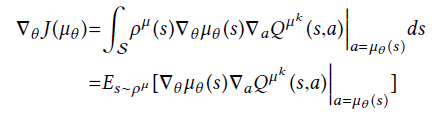
当一次流处理完成时,计算一个比率,比率为本次的吞吐量与前一次的吞吐量之比。 吞吐量Sizef(流长)与FCT(Flow completion time)之比。
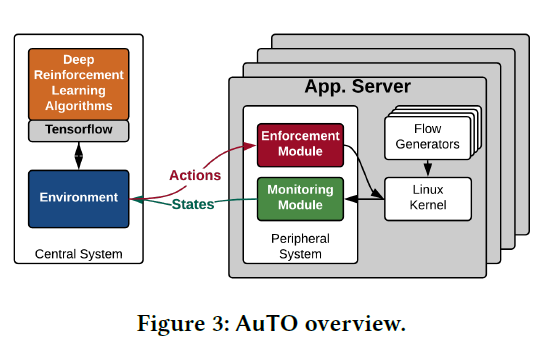
框架构建
模型组成:
- 边缘系统
- 中心系统
边缘系统
有一个MLFQ,首级队列为小流,当流超过阈值,判定为大流,在队列中被降级。
边缘系统分为增强模块和探测模块。
- 探测模块:获取流的状态信息(包括所有流的大小和处理完成的时间)
- 增强模块:获取中心系统的action,执行操作。
中心系统
其中的DRL有两个agent:
- sRLA(short Reinforcement Learning Agent): 优化小流阈值
- lRLA(long Reinforcement Learning Agent):优化大流,速率、路由、优先级
阅读AuTO利用深度强化学习自动优化数据中心流量工程(一)的更多相关文章
- 论文:利用深度强化学习模型定位新物体(VISUAL SEMANTIC NAVIGATION USING SCENE PRIORS)
这是一篇被ICLR 2019 接收的论文.论文讨论了如何利用场景先验知识 (scene priors)来定位一个新场景(novel scene)中未曾见过的物体(unseen objects).举例来 ...
- 基于TORCS和Torch7实现端到端连续动作自动驾驶深度强化学习模型(A3C)的训练
基于TORCS(C++)和Torch7(lua)实现自动驾驶端到端深度强化学习模型(A3C-连续动作)的训练 先占坑,后续内容有空慢慢往里填 训练系统框架 先占坑,后续内容有空慢慢往里填 训练系统核心 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 用深度强化学习玩FlappyBird
摘要:学习玩游戏一直是当今AI研究的热门话题之一.使用博弈论/搜索算法来解决这些问题需要特别地进行周密的特性定义,使得其扩展性不强.使用深度学习算法训练的卷积神经网络模型(CNN)自提出以来在图像处理 ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 深度强化学习——连续动作控制DDPG、NAF
一.存在的问题 DQN是一个面向离散控制的算法,即输出的动作是离散的.对应到Atari 游戏中,只需要几个离散的键盘或手柄按键进行控制. 然而在实际中,控制问题则是连续的,高维的,比如一个具有6个关节 ...
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
随机推荐
- vue的简单测试
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- bzoj3697_FJ2014集训_采药人的路径_solution
小道士的矫情之路: 点分治, 对于每个子树,处理其内经过根(重心)的路径,然后递归下一层子树: 如何处理经过根的合法路径 合法有两个要求: 把输入的0改成-1后 1.len=0; 2.存在一个点i使被 ...
- JavaWeb学习总结(四):Servlet开发(二)
一.ServletConfig讲解 1.1.配置Servlet初始化参数 在Servlet的配置文件web.xml中,可以使用一个或多个<init-param>标签为servlet配置一些 ...
- parseInt()详解
主要解释下面的计算方法: parseInt("10"); //返回 10 parseInt("19",10); //返回 19 (10+9) parseInt( ...
- EntityFramework(1)
EntityFramework核心是EDM实体数据模型,该模型由三部分组成. (1) 概念模型,由概念架构定义语言文件(.csdl)来定义. (2) 映射,由映射规范语言文件(.msl)定义. (3) ...
- Linux 安装命令
- 微服务架构之spring cloud 介绍
在当前的软件开发行业中,尤其是互联网,微服务是非常炽热的一个词语,市面上已经有一些成型的微服务框架来帮助开发者简化开发工作量,但spring cloud 绝对占有一席之地,不管你是否为java开发,大 ...
- Java基础之PDF文件的合并
1.首先下载一个jar包:pdfbox-app-1.7.1.jar 2.代码如下: package com; import java.io.File; import java.io.IOExcepti ...
- js:自动亮起100盏灯
1) 使用js在页面上显示100盏灯,并标记从1到100的编号2) 页面加载后3秒,从编号是1的灯依次自动亮起.3) 每过0.5秒亮下一盏灯(10分)4) 所有灯亮起后,弹出确 ...
- XSS防范之Encode(转)
防范XSS有三道防火墙:数据的输入校验,数据输出Encode,浏览器安全(主要就是CSP),这里主要介绍Encode. #用于XSS防范的Encode 用户防范XSS的Encode主要有三种:Html ...