hive学习2(Navicat连接hive)
Navicat连接hive
第一步:win下安装好mysql
第二步:win下安装Navicat
第三步:启动hadoop集群,启动hive
第四步:Navicat连接hive
在第四步中需先配置ssh,然后配置常规属性,最后点连接
配置ssh连接spark1节点
配置常规属性连接hive
注意:在常规属性中的用户名和密码是hive安装目录中配置文件hive-site.xml中设置的user和password。我的配置都是hive
hive-site.xml配置文件中部分内容
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
第四步属性配置详细如下图:

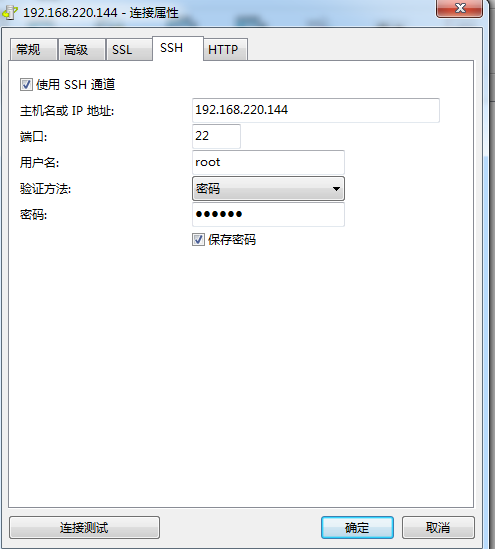

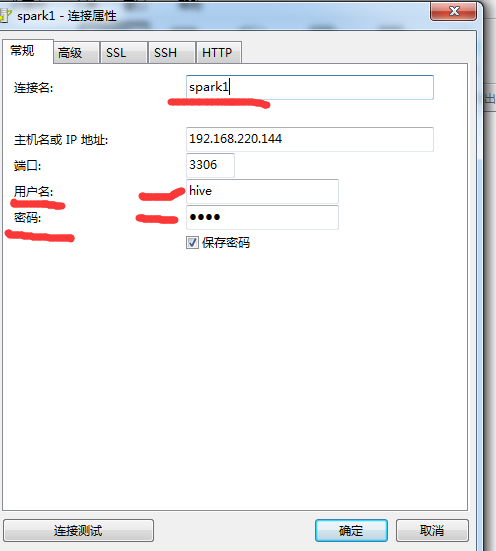
图中的spark1是我的主机名,也可以直接改成192.168.220.144这个ip地址
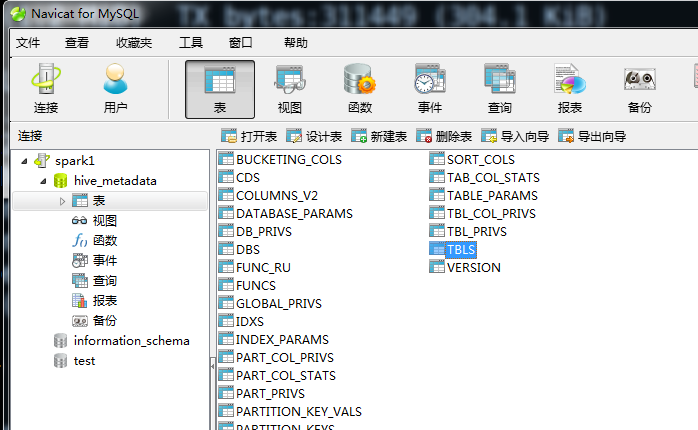
连接成功后如下图

hive学习2(Navicat连接hive)的更多相关文章
- 【Hive学习之二】Hive SQL
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 apache-hive-3.1.1 ...
- hive学习(一)hive架构及hive3.1.1三种方式部署安装
1.hive简介 logo 是一个身体像蜜蜂,头是大象的家伙,相当可爱. Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据.它架构在Hadoop之上,总归为大数据,并使得查询和分析方便 ...
- hive学习(八)hive优化
Hive 优化 1.核心思想: 把Hive SQL 当做Mapreduce程序去优化 以下SQL不会转为Mapreduce来执行 select仅查询本表字段 where仅对本表字段做条件过滤 Ex ...
- spark SQL学习(spark连接hive)
spark 读取hive中的数据 scala> import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql. ...
- Hive记录-Impala jdbc连接hive和kudu参考
1.配置环境Eclipse和JDK 2.加载hive jar包或者impala jar包 备注:从CDH集群里面拷贝出来 下载地址:https://www.cloudera.com/downloads ...
- Hive学习(三)Hive的Java客户端操作
Hive的Java客户端操作分为JDBC和Thrifit Client,首先启动Hive远程服务: hive --service hiveserver 一.JDBC 在MyEclipse中首先创建连接 ...
- Hive学习之二 《Hive的安装之自定义mysql数据库》
由于MySQL便于管理,在学习过程中,我选择MySQL. 一,配置元数据库. 1.安装MySQL,采用yum方式. ①yum install mysql-server,安装mysql服务端,安装服 ...
- hive 学习系列五(hive 和elasticsearch 的交互,很详细哦,我又来吹liubi了)
hive 操作elasticsearch 一,从hive 表格向elasticsearch 导入数据 1,首先,创建elasticsearch 索引,索引如下 curl -XPUT '10.81.17 ...
- java使用JDBC连接hive(使用beeline与hiveserver2)
首先虚拟机上已经安装好hive. 下面是连接hive需要的操作. 一.配置. 1.查找虚拟机的ip 输入 ifconfig 2.配置文件 (1)配置hadoop目录下的core-site.xml和hd ...
随机推荐
- sql server 2008获取表的字段注释
SELECT 表名 then d.name else '' end, 表说明 then isnull(f.value,'') else '' end, 字段序号=a.colorder, 字段名=a.n ...
- hbase运行时ERROR:org.apache.hadoop.hbase.PleaseHoldException:Master is initializing的解决方法
最终解决了,其实我心中有一句MMP. 版本: hadoop 2.6.4 + hbase0.98 第一个问题,端口问题8020 hadoop默认的namenode 资源子接口是8020 端口,然后我这接 ...
- TFS二次开发-基线文件管理器(5)-源码文件的读取
在上一节中,我们在保存标签之前,已经将勾选的文件路径保存到了Listbox中,这里只需要将保存的数据输出去为txt文档就可以做版本控制了. 版本文件比较复杂的是如何读取,也就是如何通过文件路径 ...
- PHP heredoc 用法2
参考网上的一个heredoc php模板实现的简单代码:index.php文件: <?php function template($template,$EXT ='htm') { $path = ...
- git的安装-环境变量配置
windows安装git和环境变量配置 2015.10.12 评论(0) 10,729 点此嗨一下 Git是一款免费.开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目. Git是一个开源 ...
- Nuxt使用scss
Nuxt中使用scss也很简单,分简单的几步就OK 一.安装scss依赖 用IDE打开项目,在Terminal里通过 npm i node-sass sass-loader scss-loader - ...
- MySQL中InnoDB脏页刷新机制Checkpoint
我们知道InnoDB采用Write Ahead Log策略来防止宕机数据丢失,即事务提交时,先写重做日志,再修改内存数据页,这样就产生了脏页.既然有重做日志保证数据持久性,查询时也可以直接从缓冲池页中 ...
- MySQL中Cardinality值的介绍
1) 什么是Cardinality 不是所有的查询条件出现的列都需要添加索引.对于什么时候添加B+树索引.一般的经验是,在访问表中很少一部分时使用B+树索引才有意义.对于性别字段.地区 ...
- RemoveDuplicatesfromSortedArray
Given a sorted array, remove the duplicates in place such that each element appear only once and ret ...
- boost之时间timer
C++一直缺乏对时间和日期的处理能力,一般借助于C的struct tm和time():timer包含三个类其中timer,progress_timer是计时器类,进度指示类是progress_disp ...