logz.io一个企业级的ELK日志分析器 内部集成了机器学习识别威胁——核心:利用用户对于特定日志事件的反馈处理动作来学习判断日志威胁 + 类似语音识别的专家系统从各方收集日志威胁信息
转自: 可看到它使用机器学习算法来识别DNS安全问题 http://logz.io/blog/machine-learning-log-analytics/
A Machine Learning Approach to Log Analytics
Opening a Kibana dashboard at any given time reveals a simple and probably overstated truth — there are simply too many logs for a human to process. Sure, you can do it the hard way, debugging issues in production by querying and searching among the millions of log messages in your system.
But this is far from being a methodological and productive method.
Kibana searches, visualizations, and dashboards are very effective ways to analyze a system, but a serious limitation of any log analytics platform, including the ELK Stack, is the fact that the people running them only know what they know. A Kibana search, for example, is limited to the knowledge of the operator who formulated it.
“Alexa/Cortana/Siri, What’s Wrong With My Production Environment?”
Asking a virtual personal assistant for help in debugging a production system may seem like a far fetched idea, but the notion of using a machine learning approach is actually very feasible and practical.
Machine learning algorithms have proven very useful in recent years at solving complex problems in many fields. From computer vision to autonomous cars to spam filters to medical diagnosis, machine learning algorithms are providing solutions to problems and solving issues where once expert humans were required.
Supervised Machine Learning
Among the various approaches to machine learning, supervised machine learning stands out as one of the most powerful tools in the data scientist’s toolbox.
Supervised machine learning is based on the idea of learning by example. The algorithm is fed with data that relates to the problem domain and meta data that attributes a label to the data. For example, the domain-specific data may be an image, essentially a set of pixels, and a label. This label may indicate that the set of pixels forms a car, a pedestrian, or an important traffic landmark. The process of assigning labels to data is referred to as “labeling,” and it plays a crucial part of obtaining good results from supervised machine learning.
Formulating the problem in this fashion enables machine learning algorithms to sift through huge amounts of data, making the necessary correlations and deducing the interdependencies between the data points.
Dealing with terabytes of log data, we at Logz.io pose this classification question: “Is this log interesting?”
An Ill-Posed Question
The question of log relevancy is not a trivial one. A log entry may prove very useful to one user and completely irrelevant to another. Moreover, in the process of data labeling, interesting logs may not get labeled correctly or at all because they were lost in the clutter.
To tackle the problem of data labeling, we at Logz.io are using the below methodologies:
Use implicit and explicit user behavior. We pay attention to the ways that our clients interact with our tools. Creating an alert, viewing a log, creating dashboards and other actions are all actions during which our users indicate what is important to them.
Inter-user similarities. All of our clients are unique, and we cherish every one of them. Our moms’ reassurances notwithstanding, we are also all very similar and use the same components and, therefore, share similar log entries. Consequently, similar users may draw benefits from common labeling.
Harvest public resources such as CQA (community questions and answers) sites and others. Sites such as Stack Overflow, GitHub, and even Wikipedia contain wealths of information and host a vast pools of knowledge that can be used to evaluate the importance of logs and even propose solutions to the root problems that are indicated by these logs.
Combining data from these resources enables us at Logz.io to create a very rich dataset of labeled logs, together with meta data on the log relevance, frequency and, in some cases, information that shows how to solve the underlying issue.
Training Your Classifier
Once the necessary data — log entries and corresponding labels — has been accumulated, it is possible to construct a log classifier.
Classification can be performed in many ways, and one such method is Linear Support Vector Machines (SVM). This type of classifier offers simple training and is easy to interpret by domain experts.
More information on SVM and its application to text classification can be found here:
- http://www.cs.cornell.edu/people/tj/publications/joachims_98a.pdf
- http://nlp.stanford.edu/IR-book/html/htmledition/support-vector-machines-and-machine-learning-on-documents-1.html
For this example, a feature vector needs to be constructed. Using short n-grams usually yields a feature space of a dimension of about 1M dimensions, which is feasible and rich enough to give good results.
Examples of such n-grams and corresponding weight coefficients are presented below. As can be seen, it is very easy to interpret the results and verify them for sanity. Positive values indicate some sort of system failure, whereas negative values indicate a log entry that does not contain an actionable, relevant, state.
unable: 0.671539714688
topic: 0.678756599452
error: 0.788508324168
connected: -0.157199772246
to provider: -0.15319903564
connected successfully: -0.15319903564
Another possibility for training a classifier is to use Random Forests, which are very useful in cases where the features are categorical (non-numerical) and do not fit linear models very well. More information about using Random Forests for classification can be found here:
While seemingly trivial, this process is very powerful. It may not take a rocket scientist to tell you that “error” is a phrase that may indicate a production issue, but it is virtually impossible for even the best DevOps group in existence to find the correlations and relations between a million phrases that occur in log data. The process of feeding these vast amounts of data to supervised ML algorithms enables the machine to learn from the accumulated knowledge of hundreds of DevOps teams and hundreds of thousands of contributors to knowledge sites.
At Logz.io, we use a set of machine learning algorithms that are able to collect bits and pieces of data — mostly on what users care about in their log data — and fuse all of them together into a supervised process that trains our machine learning code. One of the most powerful parts of the Logz.io learning system is that it learns from the way in which users react to these highlighted events, enabling ongoing supervision and continuous learning.
Integration
Once the classifier was trained, it was integrated into the Logz.io pipeline. We used tools including Spark and Hadoop to run the classifier and machine learning at the scale that was required. The logs that pass the entire classification stage are labeled as “Cognitive Insights” and additional information that has been gathered in the labeling stage is attached to them. This enables Logz.io not only to highlight relevant logs to our customers but also to enrich the logs with additional information.
A Classification Example
Obviously, the Logz.io learning technology is much more complicated and includes a multi-vector analysis, but we thought to share a simplified example. The following log was analyzed in our system (note that specific values have been obfuscated):
|
1
|
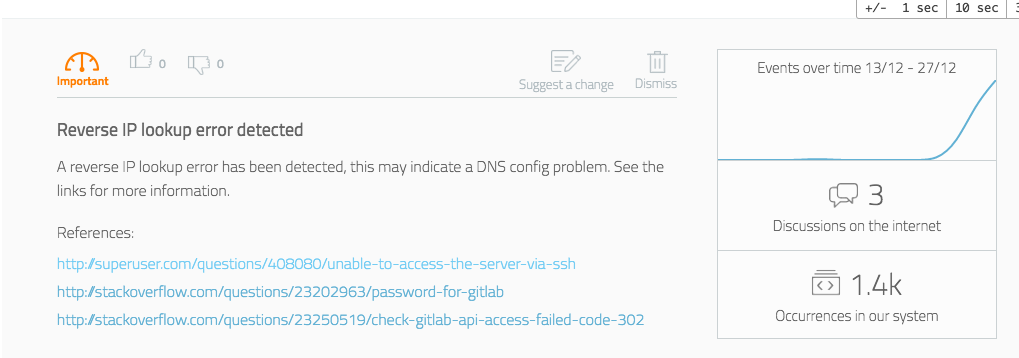
“Address <strong>IP_OCTET</strong> maps to <strong>URL</strong>, but this does not map back to the address - POSSIBLE BREAK-IN ATTEMPT!”
|
The log level for this log was not high, it did not contain any of the usual, trivial, error phrases (“error”, ”fatal”, “exception”, etc’), but it was classified as interesting.
The log was then passed through the augmentation module, and several relevant threads on knowledge sites were found:
- http://superuser.com/questions/408080/unable-to-access-the-server-via-ssh
- http://stackoverflow.com/questions/23202963/password-for-gitlab
- http://stackoverflow.com/questions/23250519/check-gitlab-api-access-failed-code-302
These online resources indicate that contrary to the log text, it is more likely to be a DNS issue than an actual security threat.
The system then displays the log and the data to the user in an informative way:
Summary
Utilizing a machine learning approach to log analytics is a very promising way to make life easier for DevOps engineers. Classifying relevant and important logs using supervised machine learning is just the first step to harnessing the power of the crowd and Big Data in log analytics. Adaptive log clustering, log recommendation, and some other cool features are coming soon, so stay tuned!
Logz.io is an AI-powered log analysis platform that offers the open source ELK Stack as a cloud service with machine learning technology. Learn more about ourCognitive Insights technology or create a free demo account to test drive the entire platform for yourself.
logz.io一个企业级的ELK日志分析器 内部集成了机器学习识别威胁——核心:利用用户对于特定日志事件的反馈处理动作来学习判断日志威胁 + 类似语音识别的专家系统从各方收集日志威胁信息的更多相关文章
- 配置好Nginx后,通过flume收集日志到hdfs(记得生成本地log时,不要生成一个文件,)
生成本地log最好生成多个文件放在一个文件夹里,特别多的时候一个小时一个文件 配置好Nginx后,通过flume收集日志到hdfs 可参考flume的文件 用flume的案例二 执行的注意点 avro ...
- ELK之使用kafka作为消息队列收集日志
参考:https://www.cnblogs.com/fengjian2016/p/5841556.html https://www.cnblogs.com/hei12138/p/7805475 ...
- 使用开源软件sentry来收集日志
原文地址:http://luxuryzh.iteye.com/blog/1980364 对于一个已经上线的系统,存在未知的bug或者运行时发生异常是很常见的事情,随之而来的几点需求产生了: 1.系统发 ...
- 通过 Systemd Journal 收集日志
随着 systemd 成了主流的 init 系统,systemd 的功能也在不断的增加,比如对系统日志的管理.Systemd 设计的日志系统好处多多,这里笔者就不再赘述了,本文笔者主要介绍 syste ...
- rancher使用fluentd-pilot收集日志分享
fluentd-pilot简介 fluentd-pilot是阿里开源的docker日志收集工具,Github项目地址:https://github.com/AliyunContainerService ...
- ELKStack入门篇(二)之Nginx、Tomcat、Java日志收集以及TCP收集日志使用
1.收集Nginx的json格式日志 1.1.Nginx安装 [root@linux-node1 ~]# yum install nginx -y [root@linux-node1 ~]# vim ...
- ELK之收集Java日志、通过TCP收集日志
1.Java日志收集 使用codec的multiline插件实现多行匹配,这是一个可以将多行进行合并的插件,而且可以使用what指定将匹配到的行与前面的行合并还是和后面的行合并. 语法示例: inpu ...
- ELK快速入门(二)通过logstash收集日志
ELK快速入门二-通过logstash收集日志 说明 这里的环境接着上面的ELK快速入门-基本部署文章继续下面的操作. 收集多个日志文件 1)logstash配置文件编写 [root@linux-el ...
- filebeat收集日志到elsticsearch中并使用ingest node的pipeline处理
filebeat收集日志到elsticsearch中 一.需求 二.实现 1.filebeat.yml 配置文件的编写 2.创建自定义的索引模板 3.加密连接到es用户的密码 1.创建keystore ...
随机推荐
- python并发编程&多进程(一)
本篇理论居多,实际操作见: python并发编程&多进程(二) 一 什么是进程 进程:正在进行的一个过程或者说一个任务.而负责执行任务则是cpu. 举例(单核+多道,实现多个进程的并发执行) ...
- Andrew Ng机器学习编程作业: Linear Regression
编程作业有两个文件 1.machine-learning-live-scripts(此为脚本文件方便作业) 2.machine-learning-ex1(此为作业文件) 将这两个文件解压拖入matla ...
- 剑指offer 面试63题
面试63题 题目:股票的最大利润 题:假设把某股票的价格按照时间先后顺序存储在数组中,请问买卖该股票一次可获得的最大利润是多少?例如,一只股票在某些时间节点的价格为{9,11,8,5,7,12,16, ...
- (from) Javascript 生成指定范围数值随机数
from:http://blog.csdn.net/ilibaba/article/details/3741786 查手册后才知道, 介绍的信息少得可怜呐, 没有介绍生成 m-n 范围的随机数..., ...
- mysql 批量更新多条记录(且不同值)的实现方法
mysql更新语句很简单,更新多条数据的某个字段为相同值,一般这样写: UPDATE table_name SET field = 'value' WHERE condition; 更新多条数据为不同 ...
- Linux Shell基础 单引号、双引号、反引号、小括号和大括号
单引号和双引号 单引号和双引号用于变量值出现空格时将字符用引号括起来. 二者的主要区别在于, 被单引号括起来的字符都是普通字符,就算特殊字符也不再有特殊含义: 被双引号括起来的字符中,"$& ...
- gstreamer-tips-picture-in-picture-compositing
http://www.oz9aec.net/index.php/gstreamer/347-more-gstreamer-tips-picture-in-picture-compositing htt ...
- 如何理解Java程序使用Unicode字符集编写
Java采用UTF-16编码作为内码,也就是说在JVM内部,文本是用16位码元序列表示的,常用的文本就是字符(char)和字符串(String)字面常量的内容.注:UTF-16是Unicode字符集的 ...
- Django-虚拟环境设置
Django 虚拟环境virtualenv virtualenv是用来处理多个用python语言进行开发的项目,在同一台机器上部署,不同项目依赖不同第三方库版本所造成的问题. 打个比方,现在你机器上要 ...
- 快乐学习 Ionic Framework+PhoneGap 手册1-5 {IO开关}
当然,即使努力了也没做成,至少你也有收获,因为你知道自己以后可以避开这个坑. 这是一个"IO"开关,请看效果图和代码,下一节,说明,数据交换 Index HTML Code < ...