Hadoop2.6.0伪分布式搭建
环境:
1、Ubuntu14.04
首先要在linux系统上新建一个账户,比如就叫做hadoop,用于专门运行hadoop。
2、配置jdk
我是使用的版本是jdk1.8。
解压:创建/usr/java目录,把下载好了的linux版本的jdk解压到次目录下。
环境变量配置:
命令sudo vim /etc/profile
在文件末端添加如下内容
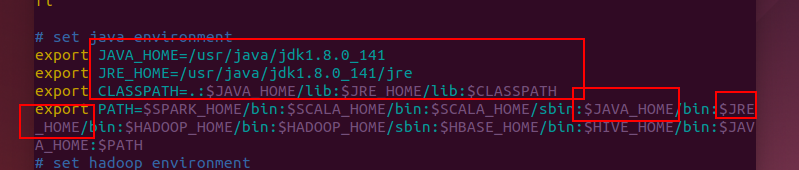
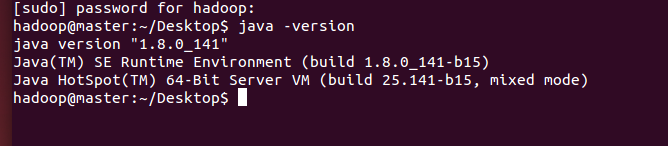
保存退出后执行 source /etc/profile更新配置。然后执行java -version如果有如下信息就表示jdk配置成功。
3 配置ssh免密码登录:
首先是下载安装openssh-server服务,执行如下命令:
sudo apt-get install openssh-server
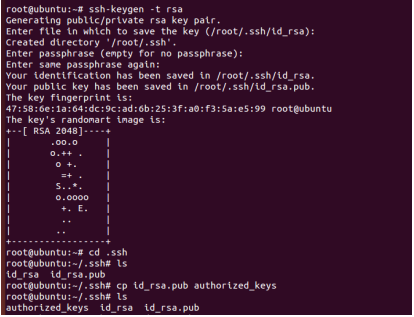
输入如下图命令,就可以配置好ssh免密码登陆了,不过注意一点是第一行命令改成:
ssh-keygen -t rsa
一路回车就行了
这样会在/home/当前用户(比如我的是/home/hadoop)目录产生一个新的目录叫 .ssh,进入发现多了两个文件分别是id_rsa和id_rsa.pub,分别是RSA的私钥和公钥,然后执行如下命令:
cat id_rsa.pub>>authorized_keys
把公钥内容复制并且添加进authorized_keys文件(设置本机ssh免密码登录)
4、hadoop配置
将下载的hadoop2.6.0安装包解压到/usr/local目录下,并且重命名为hadoop。
修改hadoop目录的权限
sudo chown -R hadoop ./hadoop
进入hadoop/etc/hadoop目录,ls一下能看到如下这些配置文件:
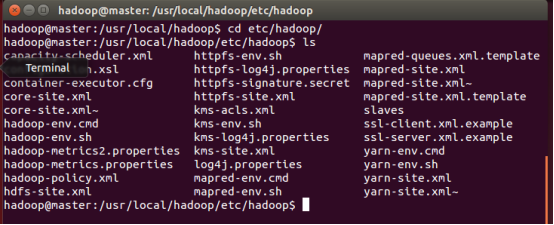
下面挨个配置:
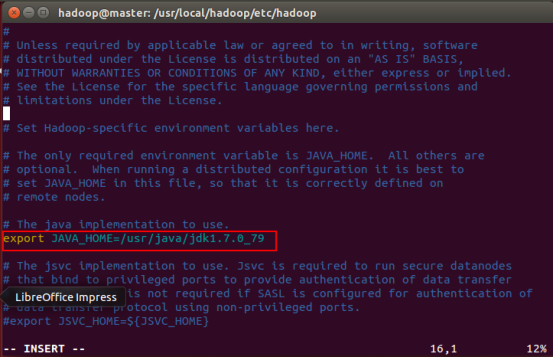
hadoop-env.sh配置
下图用红框框住的一行,“=”之后是你的jdk的绝对路径(我后来把jdk改成1.8了,这个版本仅供参考,大家按照自己系统的具体情况写就好了)。
hdfs-site.xml配置
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/usr/local/hadoop/mapred/local</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/tmp/hadoop/mapred/system</value>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
这就大功告成了。
Hadoop2.6.0伪分布式搭建的更多相关文章
- hadoop2.4.0伪分布式搭建以及分布式关机重启后datanode没起来的解决办法
1.准备Linux环境 1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip ...
- hadoop2.2.0伪分布式搭建3--安装Hadoop
3.1上传hadoop安装包 3.2解压hadoop安装包 mkdir /cloud #解压到/cloud/目录下 tar -zxvf hadoop-2.2.0.tar.gz -C /cloud/ 3 ...
- hadoop2.2.0伪分布式搭建
1.准备Linux环境 1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ...
- hadoop2.2.0伪分布式搭建1--准备Linux环境
1.0修改网关 点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip 设置网段:19 ...
- hadoop2.2.0伪分布式搭建2--安装JDK
2.1上传FileZilla 上传 https://filezilla-project.org/ 2.2解压jdk #创建文件夹 mkdir /usr/java #解压 tar -zxvf jdk-7 ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- 在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境
近几年大数据越来越火热.由于工作需要以及个人兴趣,最近开始学习大数据相关技术.学习过程中的一些经验教训希望能通过博文沉淀下来,与网友分享讨论,作为个人备忘. 第一篇,在win7虚拟机下搭建hadoop ...
- bayaim_hadoop1_2.2.0伪分布式搭建
------------------bayaim_hadoop1_2.2.0伪分布式搭建_2018年11月06日09:21:46--------------------------------- 1. ...
- 琐碎-hadoop2.2.0伪分布式和完全分布式安装(centos6.4)
环境是centos6.4-32,hadoop2.2.0 伪分布式文档:http://pan.baidu.com/s/1kTrAcWB 完全分布式文档:http://pan.baidu.com/s/1s ...
随机推荐
- 利用pt-query-digest分析MySQL慢查询
1.用法与参数说明 pt-query-digest [OPTIONS] [FILES] [DSN] --create-review-table ##当使用--review参数把分析结果输出到表中时,如 ...
- swift计算label动态宽度和高度
swift计算label动态宽度和高度 func getLabHeigh(labelStr:String,font:UIFont,width:CGFloat) -> CGFloat { let ...
- Java研究
Strap 箱线图 峰度 随机过程 马尔科夫 超几何分布 贝叶斯公式 随机变量 德摩根 功率谱 残差 吸收壁 平稳随机 chorst 深入JVM OSGI ...
- c# 获取网络流量
public class ip_helper{enum Constants {MAX_INTERFACE_NAME_LEN=256, MAXLEN_PHYSADDR=8,MAXLEN_IFDESCR= ...
- A+B Problem(高精)
题目背景 无 题目描述 高精度加法,x相当于a+b problem,[b][color=red]不用考虑负数[/color][/b] 输入输出格式 输入格式: 分两行输入a,b<=10^500 ...
- 用HANA STADIO 开发ABAP程序
Help-->Install New Software-->ADD NAME: hana_on_mars Location: https://tools.hana.ondemand.com ...
- struts2的token interceptor
关于struts2的token拦截器的说明 原理:struts2的token interceptor是关于重复提交的拦截器,其实现是:在form表单中加入token标签,如下: <form ac ...
- MySql外键建立在哪里(更新)
一对一的时候:分为主表和附表 外键建立在附件上 附表的外键关联到主表的主键上,Example:学生表和学生信息表,在学生信息表上建立外键 一对多的时候:分为一和多 外键建立在多上 Exampl ...
- 数据解压及if else的应用
def sum(items): head, *tails = items return head + sum(tails) if tails else head # 最后一句有点像三目运算符,如果ta ...
- git push之后回滚(撤销)代码
问题描述:首先,先说明一下,为什么会引发这次的话题,是这样的,我做完功能Agit push之后,2个月后需求部门要求不要功能A了,然后需要在没有功能A的基础上开发,怎么办?赶紧回滚代码呀. 然后我用g ...