稀疏表示(Sparse Representations)
1.什么是稀疏表示:
用较少的基本信号的线性组合来表达大部分或者全部的原始信号。
其中,这些基本信号被称作原子,是从过完备字典中选出来的;而过完备字典则是由个数超过信号维数的原子聚集而来的。可见,任一信号在不同的原子组下有不同的稀疏表示。
假设我们用一个M*N的矩阵表示数据集X,每一行代表一个样本,每一列代表样本的一个属性,一般而言,该矩阵是稠密的,即大多数元素不为0。 稀疏表示的含义是,寻找一个系数矩阵A(K*N)以及一个字典矩阵B(M*K),使得B*A尽可能的还原X,且A尽可能的稀疏。A便是X的稀疏表示。
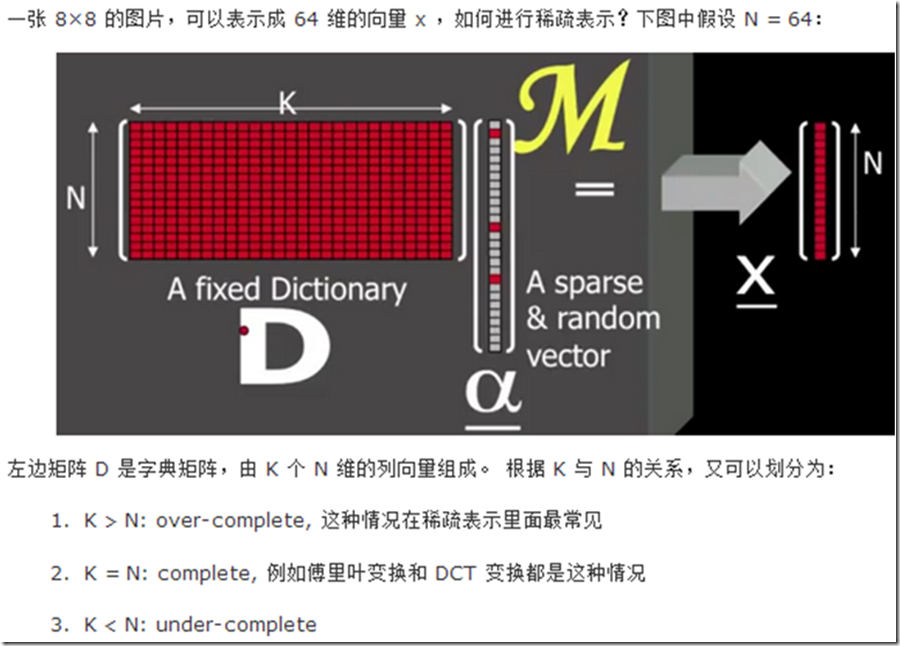
南大周志华老师写的《机器学习》这本书上原文:“为普通稠密表达的样本找到合适的字典,将样本转化为合适的稀疏表达形式,从而使学习任务得以简化,模型复杂度得以降低,通常称为‘字典学习’(dictionary learning),亦称‘稀疏编码’(sparse coding)”块内容。
表达为优化问题的话,字典学习的最简单形式为:
其中xi为第i个样本,B为字典矩阵,αi为xi的稀疏表示,λ为大于0参数。

•寻找少量重要的系数来表示原始信号的技术被称作Sparse Coding(稀疏编码或稀疏分解);
•从任意一个字典中为原始信号寻找最稀疏的表示常用的方法分类两类:
①贪婪算法,比如匹配追踪(MP)、正交匹配追踪(OMP)、弱匹配追踪(WMP)、阈值方法等;
②松弛算法,比如迭代加权最小二乘(Iterative-Reweighed-Least-Squares,IRLS)、基追踪(BP)等。
其中,贪婪算法的特点是速度快,精度相对较低;松弛算法是精度高,但速度慢。
•穷举法——NP难:
假设 的非零项数目为L(sparse level),先令L=1,字典里的每一个原子(列向量)尝试一遍,看是否满足终止条件,共有K种组合。如果没有满足,再令L=2,再次尝试,共有K(K-1)/2种组合。还没有满足条件的,则令L=3……组合的数目呈指数增长,于是遇到了NP难问题。
•贪婪算法——Matching Pursuit
第一步,找到最接近X的原子,等效于 向量上仅取一个非零项,求出最接近的原子,保留下来;
第二步,计算误差是否满足要求,如果满足,算法停止,否则,计算出残差信号,和第一步类似,找到最接近残差向量的原子,保留下来;
第三步,调整已选向量的系数,使得 最接近X,重复第二步。
•松弛算法——Basis Pursuit,将L0问题转化为L1问题,解决的方法有很多,比如内点法、迭代收缩法等。事实上,它可以化成一个线性规划的问题,用MATLAB很容易解。
上式中第一个累加项说明了字典学习的第一个目标是字典矩阵与稀疏表示的线性组合尽可能的还原样本;第二个累加项说明了αi应该尽可能的稀疏。之所以用L1范式是因为L1范式正则化更容易获得稀疏解。具体原因参看该书11.4章或移步机器学习中的范数规则化之(一)L0、L1与L2范数。字典学习便是学习出满足上述最优化问题的字典B以及样本的稀疏表示A(A{α1,α2,…,αi})。L1正则化常用于稀疏,可以获得稀疏解。如下图表示,L1正则化交点在轴上,所得的解一般只是在某个轴上有实数,另外的轴为0,从而最终得到稀疏解。

2.字典学习:
寻找字典的过程称为字典学习。字典学习的一个假设是字典对于指定信号具有稀疏表示。因此,选择字典的原则就是能够稀疏地表达信号。
两种方法来设计字典:
•从已知的变换基中选取,比如 DCT 、小波基等,这种方法很通用,但是不能自适应于信号。
学习字典,即通过训练和学习大量的与目标数据相似的数据来获得。这里,我们介绍一种叫K-SVD的方法
字典学习算法理论包含两个阶段:字典构建阶段(Dictionary Generate)和利用字典(稀疏的)表示样本阶段(Sparse coding with a precomputed dictionary)。这两个阶段(如下图)的每个阶段都有许多不同算法可供选择,每种算法的诞生时间都不一样,以至于稀疏字典学习的理论提出者已变得不可考。笔者尝试找了Wikipedia和Google Scolar都无法找到这一系列理论的最早发起人。
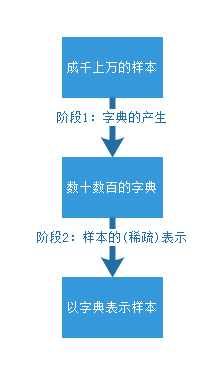
出处:http://www.mamicode.com/info-detail-1568956.html
字典学习的第一个好处——它实质上是对于庞大数据集的一种降维表示。第二,正如同字是句子最质朴的特征一样,字典学习总是尝试学习蕴藏在样本背后最质朴的特征(假如样本最质朴的特征就是样本最好的特征).稀疏表示的本质:用尽可能少的资源表示尽可能多的知识,这种表示还能带来一个附加的好处,即计算速度快。我们希望字典里的字可以尽能的少,但是却可以尽可能的表示最多的句子。这样的字典最容易满足稀疏条件。也就是说,这个“字典”是这个“稀疏”私人订制的。
稀疏表达有两点好处:
1) 省空间;
2) 奥卡姆剃刀说:如果两个模型的解释力相同,选择较简洁的那个。稀疏表达就符合这一点。
How to find the dictionary D?——K-SVD
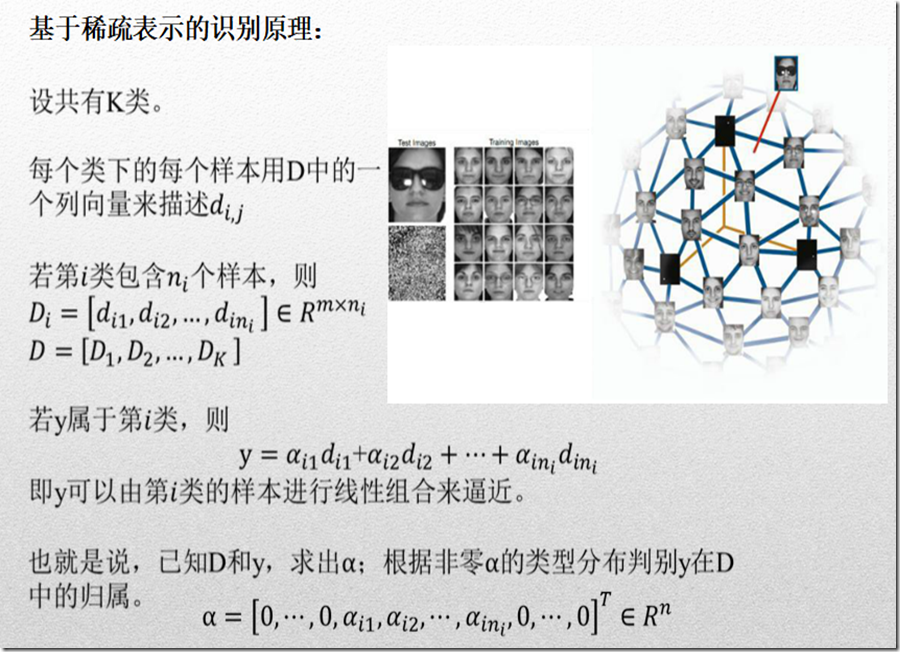
假设现在有原始信号矩阵 , 该矩阵的每一行表示一个信号或者一张图片, D 矩阵是字典矩阵,右下方是 稀疏解矩阵S,红色的点表示非零项。

Step 1: Initialize. 在 矩阵中随机挑选一些行向量(一些原图),填满矩阵 D,并归一化每一列。
Step 2: Sparse Coding. 用松弛或者贪婪法进行稀疏编码,使得

得到稀疏表示 构成稀疏矩阵S的第i行。
What are sparse representations/approximations good for?
•稀疏性是DFT、WT和SVD分解得以广泛利用的原因之一,这些变换的目的都是为了反映信号的确定性结构,并用紧凑的或稀疏的表示来表征这些结构;
•稀疏表示的思想为模式分类方法建立了基础,比如SVM和RVM,其中稀疏性直接与估计函数(estimator)的学习能力有关。
•稀疏表示解决的问题主要集中在:
•图像去噪(Denoise),代表性paper:ImageDenoiseVia Sparse and Redundant Representations Over Learned Dictionaries(Elad M. and Aharon M. IEEE Trans. on Image Processing,Dec,2006);Image SequenceDenoisingVia Sparse and Redundant Representations(Protter M. and Elad M.IEEE Trans. on Image Processing,Jan,2009);
•超分辨率重建(Super-Resolution OR Scale-Up),代表性paper:Image Super-Resolution via Sparse Representation(Jianchao Yang, John Wright, Thomas Huang, and Yi Ma,IEEE Transactions on Image Processing, Nov,2010),A Shrinkage Learning Approach for Single Image Super-Resolution withOvercompleteRepresentations( A. Adler, Y. Hel-Or, and M. Elad,ECCV,Sep,2010);
另外还有inpaintting,deblurring,compression等等..更多应用参考Elad M的书。

稀疏表示(Sparse Representations)的更多相关文章
- 第17章 内存映射文件(3)_稀疏文件(Sparse File)
17.8 稀疏调拨的内存映射文件 17.8.1 稀疏文件简介 (1)稀疏文件(Sparse File):指的是文件中出现大量的0数据,这些数据对我们用处不大,但是却一样的占用空间.NTFS文件系统对此 ...
- 稀疏表示 Sparse Representation
稀疏表示_百度百科 https://baike.baidu.com/item/%E7%A8%80%E7%96%8F%E8%A1%A8%E7%A4%BA/16530498 信号稀疏表示是过去近20年来信 ...
- javascript中的稀疏数组(sparse array)和密集数组
学习underscore.js数组相关API的时候.遇到了sparse array这个东西,曾经没有接触过. 这里学习下什么是稀疏数组和密集数组. 什么是密集数组呢?在java和C语言中,数组是一片连 ...
- 稀疏编码(Sparse Coding)的前世今生(一) 转自http://blog.csdn.net/marvin521/article/details/8980853
稀疏编码来源于神经科学,计算机科学和机器学习领域一般一开始就从稀疏编码算法讲起,上来就是找基向量(超完备基),但是我觉得其源头也比较有意思,知道根基的情况下,拓展其应用也比较有底气.哲学.神经科学.计 ...
- dense向量和稀疏向量sparse
import org.apache.spark.mllib.linalg.Vectors object Test { def main(args: Array[String]) { val vd = ...
- 用windows自带的fsutil来创建1G稀疏文件(sparse file)
fsutils file createnew a.dat 1073741824 fsutil sparse setflag a.dat fsutil sparse setrange a.dat 0 ...
- 稀疏编码(Sparse Coding)的前世今生(二)
为了更进一步的清晰理解大脑皮层对信号编码的工作机制(策略),须要把他们转成数学语言,由于数学语言作为一种严谨的语言,能够利用它推导出期望和要寻找的程式.本节就使用概率推理(bayes views)的方 ...
- [综] Sparse Representation 稀疏表示 压缩感知
稀疏表示 分为 2个过程:1. 获得字典(训练优化字典:直接给出字典),其中字典学习又分为2个步骤:Sparse Coding和Dictionary Update:2. 用得到超完备字典后,对测试数据 ...
- 特征选择与稀疏学习(Feature Selection and Sparse Learning)
本博客是针对周志华教授所著<机器学习>的"第11章 特征选择与稀疏学习"部分内容的学习笔记. 在实际使用机器学习算法的过程中,往往在特征选择这一块是一个比较让人模棱两可 ...
随机推荐
- 查看tensorflow版本和存储位置
>>>import tensorflow as tf >>>tf.__version__ __是两个下划线,中间有空格 >>>tf.__path_ ...
- Google I/O 2014 大会总结 Android开发新方向
昨天晚上,Google I/O 2014大会召开,会上主要展示了下面几个部分的创新内容: Android L 操作系统 首先是界面,谷歌又一次设计了一套 UI 规范.并称之为"Materia ...
- C++语言基础(19)-模板的显式具体化
应用背景: 例如有下面的函数模板,它用来获取两个变量中较大的一个: template<class T> const T& Max(const T& a, const T&a ...
- Tomcat控制台输出
在Tomcat中,默认将终端输出信息输出到: $CATALINA_HOME/logs/catalina.out 其中$CATALINA_HOME是tomcat的安装目录. tomcat启动后,该文件 ...
- c++ what happens when a constructor throws an exception and leaves the object in an inconsistent state?
为什么会想到这个问题?因为我总是不自觉地将c++和java进行对比.java对这种情况的处理方式是constructor返回一个null,然后已经构造的objects交给Garbage Collect ...
- IOS设计模式的六大设计原则之单一职责原则(SRP,Single Responsibility Principle)
定义 就一个类而言,应该仅有一个引起它变化的原因. 定义解读 这是六大原则中最简单的一种,通俗点说,就是不存在多个原因使得一个类发生变化,也就是一个类只负责一种职责的工作. 优点 类的复杂度降低,一个 ...
- Linux中解压缩命令gzip和unzip的一点说明
inux中解压缩命令gzip和unzip的一点说明 转载 2014年10月29日 20:37:35 20741 Linux 常用的压缩命令有 gzip 和 zip,两种压缩包的结尾不同:zip 压 ...
- npm安装vue-cil出现错误
这个错误有点尴尬..... 之前全局安装过cil,然后在全局安装出现了这个错误,各种手册看了半天也没有头绪,猛然想起来之前安装过,试下直接初始化项目试一下,果然成功了 然后在 npm install ...
- Easyui Form增加myLoad方法,使其支持二级数据对象
$.extend($.fn.form.methods, { myLoad : function (jq, param) { return jq.each(function () { load(this ...
- CentOS 6.5 Ruby源码安装
清除旧版Ruby,若存在 yum remove ruby 若为源码,使用如下命令 cd <your-ruby-source-path> make uninstall 下面开始安装Ruby ...