开源TSDB简介--Druid
开源TSDB简介--Druid
Druid是一个以Java编写的开源分布式列式数据存储。 Druid的目标是快速提取大量事件数据,并提供低延迟的查询。
德鲁伊的名字来源于许多角色扮演游戏中的变形德鲁伊角色,以表示其系统结构可以为解决不同类型数据问题而灵活改变。 Druid通常用于OLAP(Online analytical processing)应用程序来分析大量的实时和历史数据。
Architecture
为了方便使用以及cloud-friendly,Druid拥有一个多进程、分布式架构。 Druid按功能分为多种node,每个类型node都可以独立配置和扩展,为Druid群集提供最大的灵活性。 该设计还提供增强的容错能力:一个组件的中断不会立即影响其他组件。
Druid的node类型包括:
- Historical - 处理存储和查询历史数据的进程,其从deep storage中下载segments并响应有关这些数据的查询,Historical不接受数据写入操作。
- MiddleManager - 处理新的数据写入的进程,其负责从外部数据源获取数据生成Druid segments并写入集群。
- Broker - 代理查询请求的进程,其从客户端接受查询请求,并转发给Historicals和MiddleManagers,并在收到查询结果后进行合并后返回给客户端。
- Coordinator - 观察和协调Historical集群的进程,其负责分配segments到指定的servers,并保证segments在Historicals上的数据均衡。
- Overlord - 观察和协调MiddleManager集群的进程,其负责分配数据写入任务给MiddleManagers并协调segments的发布。
- Router - 可选进程,用于在Brokers、Overlords和Coordinators之前提供一个统一的API网关。如果没有部署Router,则直接和Brokers、Overlords和Coordinators进行通讯。
如下图所示为Druid的架构图:
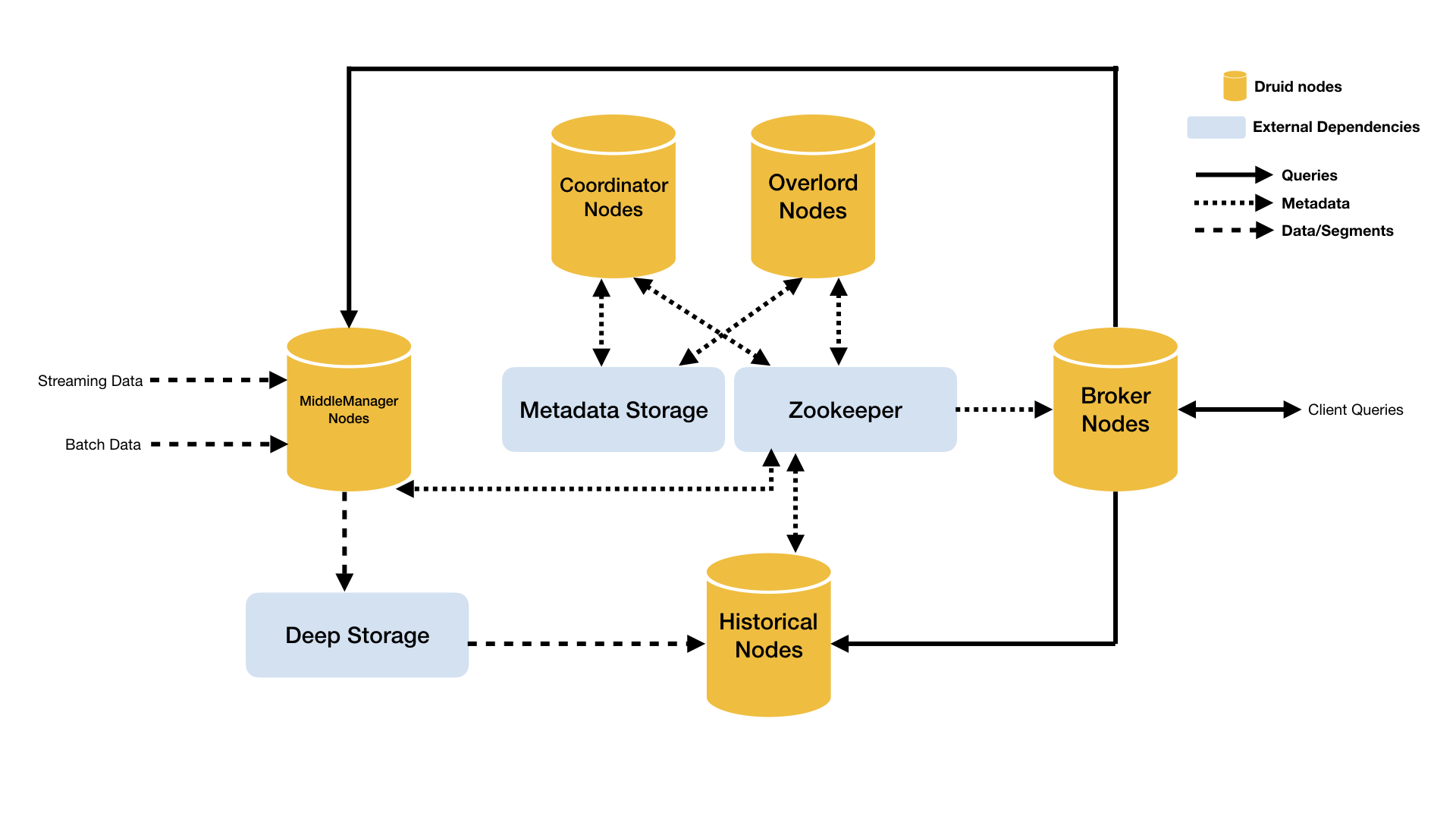
Druid的架构将服务划分的比较细,有利于动态扩展和在云上部署。但个人觉得略显复杂的架构,并不是很方便部署和运维,尤其是其依赖了过多的外部组件。
Deployment
Druid各个node进程可以单独部署或者合设到同一台机器上,一个常用的部署方式:
- "Data" servers - Historical + MiddleManager
- "Query" servers - Broker + (optionally) Router
- "Master" servers - Coordinator + Overlord + ZooKeeper
此外,Druid还依赖3个外部组件:
- Deep storage - 在不同的Druid server共享数据文件的存储,通常使用分布式存储如S3或者HDFS。Druid使用Deep storage来存储所有写入的数据。
- Metadata store - 在不同的Druid server共享metadata的存储,通常使用传统的RDBMS,如PostgreSQL或者MySQL。
- ZooKeeper - 用于服务发现、协调和leader选举。
Datasources and Segments
Druid将数据存储在"datasources"里,相当于传统RDBMS的表格。每个datasource用时间进行分区(可选其他属性进行进一步分区)。每个时间范围(如按天分区,则时间范围为一天)称为一个"chunk" 。在一个chunk里,数据进一步分区为一个或多个"segments"。每个segment是一个单独文件,存储大约几百万行数据。
一个datasource可能包含从几个segments到几百万几个segments。每个segment由MiddleManager创建,然后经过如下步骤的处理以生成紧凑的文件并支持快速查询:
- 转换成columnar列式格式
- 使用位图索引进行索引查询
- 使用各种算法进行压缩
- 进行字符串编码,使用UID代替string字符串进行存储,节约存储空间
- 将位图索引进行压缩
- 所有列进行类型感知的压缩
Segments周期性的提交和发布,此时他们写入Deep storage,并不允许再修改,并从MiddleManager转移到Historical。该Segment对应的一条记录写入到metadata store。该记录用一些bits来描述segment的属性,如segment的schema、大小以及其所在deep storage位置。这些信息都是Coordinator需要用到的。
Query
收到查询请求后,Broker根据请求先定位到哪些segments可能包含查询需要的数据,然后根据segments定位并发送请求到对应的Historicals和MiddleManagers。然后Historical/MiddleManager进程查询获取具体的数据并返回结果。Broker最后将查询结果汇聚后返回给调用者。
Broker pruning(裁剪)是Druid限制每个查询请求需要扫描的数据量的重要方式,但它不是唯一方法。过滤器提供了更细粒度的裁剪方法,每个Segment内的索引结构可以帮助Druid过滤出需要查询的行。这样Druid可以只读取匹配了查询过滤器的行,从而跳过不需要读取的行。
所以Druid通过如下3个方法提供查询的性能:
- 裁剪定位查询需要扫描的segments
- 在segment内,通过索引定位需要查询的行
- 在segment内,只读取查询相关的行和列
参考
开源TSDB简介--Druid的更多相关文章
- 其他主流开源硬件简介BeagleBone Black快速入门
其他主流开源硬件简介BeagleBone Black快速入门 1.3 其他主流开源硬件简介 开源硬件种类繁多,但主要有两款开源硬件常与BeagleBone比较.它们就是Arduino和Raspberr ...
- 开源GIS简介
原文 开源GIS C++开源GIS中间件类库: GDAL(栅格)/OGR(矢量)提供了类型丰富的读写支持 GEOS(Geometry Engine Open Source)是基于C++的空间拓扑分析实 ...
- MIUI6&7桌面角标开源代码简介
MIUI6&7桌面角标开源代码简介 MIUI6&7上重新设计了桌面app图标的角标显示,基本规则如下: 一.基本介绍 1.默认的情况 当app 向通知栏发送了一条通知 (通知不带进度条 ...
- apache基金会开源项目简介
apache基金会开源项目简介 项目名称 描述 HTTP Server 互联网上首屈一指的HTTP服务器 Abdera Apache Abdera项目的目标是建立一个功能完备,高效能的IETF ...
- GitHub 上排名前 100 的 IOS 开源库简介
主要对当前 GitHub 排名前 100 的项目做一个简单的简介, 方便初学者快速了解到当前 Objective-C 在 GitHub 的情况. 项目名称 项目信息 1. AFNetworking 作 ...
- [转]六款值得推荐的android(安卓)开源框架简介
本文转自:http://www.jb51.net/article/51052.htm .volley 项目地址 https://github.com/smanikandan14/Volley-demo ...
- 6个值得推荐的Android开源框架简介(转)
虽然我们在做app的时候并不一定用到框架,但是一些好框架的思想是非常有学习价值的 1.volley 项目地址 https://github.com/smanikandan14/Volley-demo ...
- 六款值得推荐的android(安卓)开源框架简介(转)
1.volley 项目地址 https://github.com/smanikandan14/Volley-demo (1) JSON,图像等的异步下载: (2) 网络请求的排序(scheduli ...
- 几款值得推荐的android(安卓)开源框架简介
技术不再多,知道一些常用的.不错的就够了. 该文章自有需要的时候,mark一下. 顺序不代表排名,根据自己需求进行选择即可. 1.volley 项目地址 https://github.com/sman ...
随机推荐
- angular 子路由
const routes: Routes = [ { path: '', redirectTo: '/home', pathMatch: 'full' }, { path: 'home', compo ...
- [转]解读Unity中的CG编写Shader系列二
上一篇文章的例子中我们可以看到顶点着色器的输出参数可以说是直接作为了片段着色器的形参传递过来,那么不由得一个问题浮现出来,顶点着色器的形参是从何处传递过来的? 顶点着色器的形参是gameObject ...
- 洛谷P2566 [SCOI2009]围豆豆(状压dp+计算几何)
题面 传送门 题解 首先要解决一个问题,就是怎么判断一个点是否在多边形内部 从这个点向某一个方向做一条射线,如果这条射线和多边形的交点为奇数说明在多边形内,否则在多边形外 然而有一些特殊情况,比方说一 ...
- 使用 Flask 实现 RESTful API
原文出处: Luis Rei 译文出处:nummy 简介 首先,安装Flask 1 pip install flask 假设那你已经了解RESTful API的相关概念,如果不清楚,可以阅 ...
- Qt 学习之路 2(71):线程简介
Qt 学习之路 2(71):线程简介 豆子 2013年11月18日 Qt 学习之路 2 30条评论 前面我们讨论了有关进程以及进程间通讯的相关问题,现在我们开始讨论线程.事实上,现代的程序中,使用线程 ...
- selenium定位不到元素
selenium定位不到元素时,网上大部分查到都是iFrame的切换问题,然后是多窗口.句柄的处理问题, 在初学是遇到定位不到元素,一直在找上面的问题,发现都不是上面的问题, 后来才发现是页面刷新的问 ...
- SQL 随手记
SQL 学习片段: 建立一个简单的联系数据表, mobile_number char(11).mobile_province nvarchar(50).mobile_area nvarchar(200 ...
- 文本编辑器 未完成 Treap
#include<bits/stdc++.h> using namespace std; const int maxn = 2e6+1e5; unsigned int SEED = 17; ...
- Mock单元测试
/// <summary> /// 普通插入 /// </summary> [Fact] public void InsertOrder_Tests() { _sqlMappe ...
- SSH 项目建立过程
1. 加入 Spring 1). 加入 jar 包 2). 配置 web.xml 文件 <context-param> <param-name>contextConfigLoc ...