hadoop本地运行与集群运行
开发环境:
windows10+伪分布式(虚拟机组成的集群)+IDEA(不需要装插件)
介绍:
本地开发,本地debug,不需要启动集群,不需要在集群启动hdfs yarn
需要准备什么:
1/配置win10的环境,path设置为hadoop/bin目录
2/将hadoop在win10系统下编译,替换hadoop/bin,hadoop/lib目录为对应的win10编译版本
本地运行详细步骤:
1/在run configurations里设置program arguments,即设置main方法的默认参数
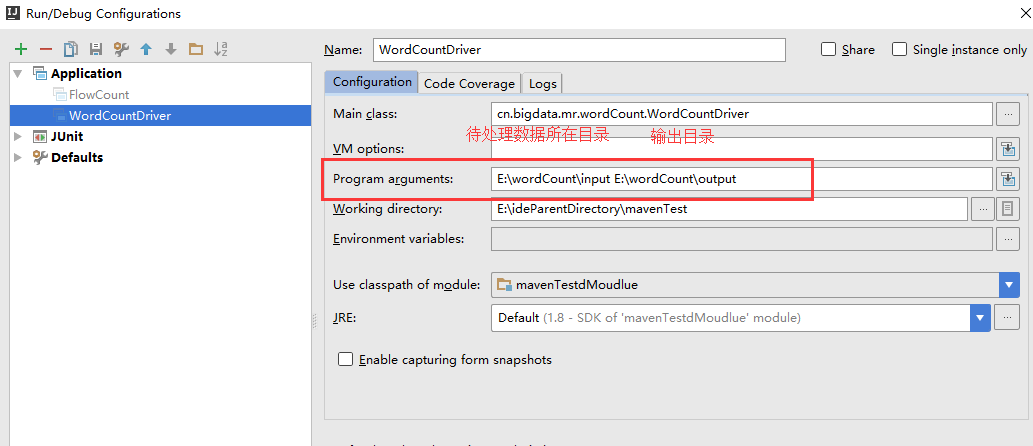
2/直接运行main方法
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//是否运行为本地模式,就是看这个参数值是否为local,默认就是local
/*conf.set("mapreduce.framework.name", "local");*/
//本地模式运行mr程序时,输入输出的数据可以在本地,也可以在hdfs上
//到底在哪里,就看以下两行配置你用哪行,默认就是file:///
/*conf.set("fs.defaultFS", "hdfs://mini1:9000/");*/
/*conf.set("fs.defaultFS", "file:///");*/
//运行集群模式,就是把程序提交到yarn中去运行
//要想运行为集群模式,以下3个参数要指定为集群上的值
//如果是把程序打包成jar,hadoop jar运行,不需要写下面,因为hadoop jar脚本自动把集群中配置好的配置文件加载给该程序
/*conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "mini1");
conf.set("fs.defaultFS", "hdfs://mini1:9000/");*/
Job job = Job.getInstance(conf);
//告诉yarn本程序的jar包在哪里
/*job.setJar("/home/hadoop/wordcount.jar");*/
//指定本程序的jar包所在的本地路径(获得类运行的目录)
job.setJarByClass(WordCountDriver.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/*job.submit();*/
//true把反馈信息打印出来
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
报错1:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/util/StopWatch
解决1:
1/把hadoop-client /hadoop-common从2.6.0改为2.7.0
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.0</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.0</version>
</dependency>
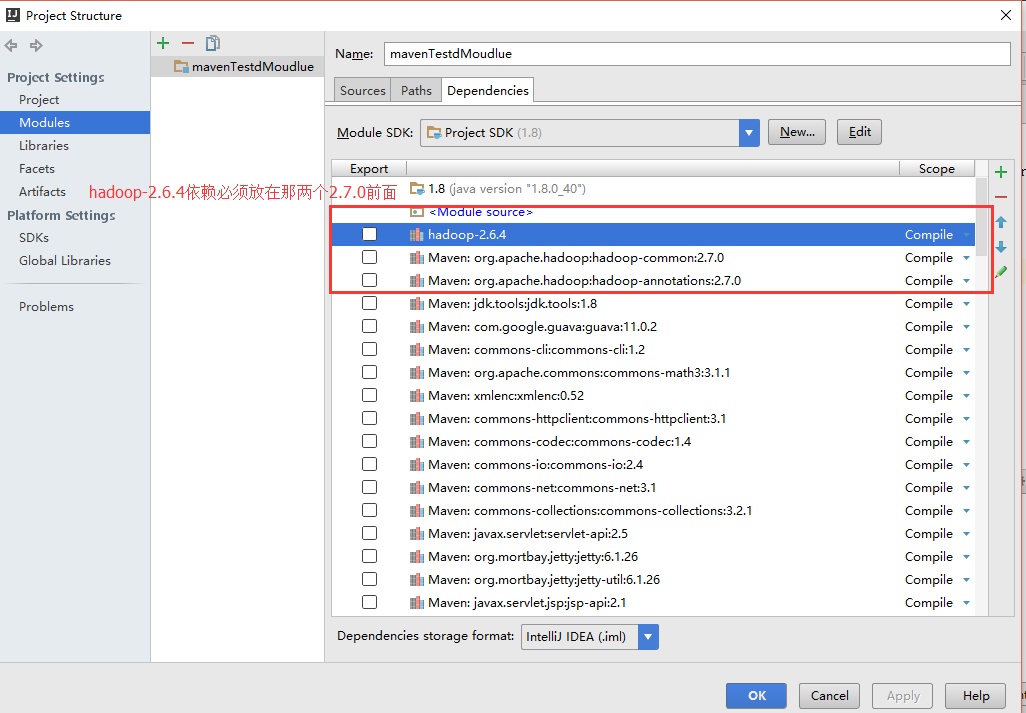
2/可能是因为我本地的hadoop是windows下编译的2.6.4版本,把该版本的所有jar包放在一个lib里,并且放在最上面 否则会报错Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V
本地运行模式
(1)mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行
(2)而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上
(3)怎样实现本地运行?写一个程序,不要带集群的配置文件(本质是你的mr程序的conf中是否有mapreduce.framework.name=local以及yarn.resourcemanager.hostname参数)
(4)本地模式非常便于进行业务逻辑的debug,只要在eclipse中打断点即可
如果在windows下想运行本地模式来测试程序逻辑,需要在windows中配置环境变量:
%HADOOP_HOME% = d:/hadoop-2.6.1
%PATH% = %HADOOP_HOME%\bin
并且要将d:/hadoop-2.6.1的lib和bin目录替换成windows平台编译的版本
================mac版本========================
idea+maven环境编写wordcount程序(运行在本地,没有用到hadoop集群,适合做调试)https://www.cnblogs.com/davidgu/p/6140927.html
1、看他的main方法怎么配置的
2、看他的运行参数怎么配置的
集群运行模式
(1)将mapreduce程序提交给yarn集群resourcemanager,分发到很多的节点上并发执行
(2)处理的数据和输出结果应该位于hdfs文件系统
(3)提交集群的三种方法:
A、将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
$ hadoop jar wordcount.jar cn.itcast.bigdata.mrsimple.WordCountDriver inputpath outputpath
idea的hadooop的wordcount打成jar包放到linux执行步骤: https://blog.csdn.net/Andeve/article/details/78606461
main方法里不需要写mapreduce.frameword.name=yarn以及yarn的两个基本配置
整体思路参考 https://songlee24.github.io/2015/07/29/mapreduce-word-count/
B、直接在linux的eclipse中运行main方法,跑在本机的hadoop上/远程hadoop集群上
(项目中要带参数:mapreduce.framework.name=yarn以及yarn的两个基本配置)
参考 : idea向hadoop集群提交mapreduce作业 https://blog.csdn.net/shirukai/article/details/81021872
的第六步导出jar,第七步连接配置

C、如果要在windows的eclipse中提交job给集群,则要修改YarnRunner类
MAVEN的pom.xml,hadoop版本是<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.sumeng</groupId>
<artifactId>cloudHadoop</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.</version>
</dependency>
</dependencies>
</project>
hadoop本地运行与集群运行的更多相关文章
- storm单机运行与集群运行问题
使用trident接口时,storm读取kafka数据会将kafka消费记录保存起来,将消费记录的位置保存在tridentTopology.newStream()的第一个参数里, 如果设置成从头开始消 ...
- 简单说明hadoop集群运行三种模式和配置文件
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下: 1.独立模式即本地运行模式(standalone或local mode)无需运行任何守护进程(daemon) ...
- Hadoop集群运行JNI程序
要在Hadoop集群运行上运行JNI程序,首先要在单机上调试程序直到可以正确运行JNI程序,之后移植到Hadoop集群就是水到渠成的事情. Hadoop运行程序的方式是通过jar包,所以我们需要将所有 ...
- hadoop一代集群运行代码案例
hadoop一代集群运行代码案例 集群 一个 master,两个slave,IP分别是192.168.1.2.192.168.1.3.192.168.1.4 hadoop版 ...
- Spark本地运行成功,集群运行空指针异。
一个很久之前写的Spark作业,当时运行在local模式下.最近又开始处理这方面数据了,就打包提交集群,结果频频空指针.最开始以为是程序中有null调用了,经过排除发现是继承App导致集群运行时候无法 ...
- spark之scala程序开发(集群运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 新闻实时分析系统 Spark2.X集群运行模式
1.几种运行模式介绍 Spark几种运行模式: 1)Local 2)Standalone 3)Yarn 4)Mesos 下载IDEA并安装,可以百度一下免费文档. 2.spark Standalone ...
- 新闻网大数据实时分析可视化系统项目——16、Spark2.X集群运行模式
1.几种运行模式介绍 Spark几种运行模式: 1)Local 2)Standalone 3)Yarn 4)Mesos 下载IDEA并安装,可以百度一下免费文档. 2.spark Standalone ...
随机推荐
- c++ 如何使用第三方的library
感谢以下参考资料: 关于如何使用第三方的库: http://stackoverflow.com/questions/21942545/how-to-install-third-party-librar ...
- iOS一些基础面试题
Part One 别人问你你都感觉这尼玛说啥的基础面试题 1.UIWindow和UIView和 CALayer 的联系和区别? 答:UIView是视图的基类,UIViewController是视图控制 ...
- PHP安装加载yaf扩展
Yaf,全称 Yet Another Framework,是一个C语言编写的PHP框架,是一个用PHP扩展形式提供的PHP开发框架, 相比于一般的PHP框架, 它更快. 它提供了Bootstrap, ...
- with root cause 解决办法
现象:1.工程在启动的时候无异常,当页面加载到包含spring:message标签的页面时,在后台报空指针异常,同时控制 台会显示with root cause提示: 2. ...
- 【问题】CentOS6.5系统"libc.so.6: version 'GLIBC_2.15' not found"解决方法
出现"libc.so.6: version 'GLIBC_2.15' not found"问题,是由于glibc版本过低,升级glibc即可. 由于CentOS系统RPM源目前gl ...
- myeclipse中文编码错误,没有GBK选项
默认编码是UTF-8,但是导入GBK工程后,直接改为ISO-8859-1,但是还是编码错误. 用网上的: 全局编码设置:编码设置的方法:ToolBar-->Window-->Prefere ...
- 对asp.net缓存 的深入了解
一.缓存概念,缓存的好处.类型.-------------------------------------------------------------------------------- ...
- 安装使用yarn,使用国内镜像加速npm和yarn
安装yarn https://yarnpkg.com/lang/zh-hans/docs/install/ 使用国内镜像加速npm和yarn 1. npm config set registry=ht ...
- Andriod - 创建自定义控件
控件和布局的继承结构: 可以看到,我们所用的所有控件都是直接或间接继承自 View的,所用的所有布局都是直接或间接继承自 ViewGroup 的.View 是 Android 中一种最基本的 UI 组 ...
- CodeIgniter框架——源码分析之CodeIgniter.php
CodeIgniter.php可以说是CI的核心,大部分MVC的流程都是在这个文件夹中处理的,其中加载了很多外部文件,完成CI的一次完整流程. 首先是定义了CI的版本(此处为CI 2.2.0),接下来 ...