19-[模块]-json/pickle、shelve
1.序列化?
序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes
(1)把字典保存到文件
data = {
'roles': [
{'role': 'monster', 'type': 'pig', 'life': 50},
{'role': 'hero', 'type': 'dog', 'life': 80},
]
}
f = open('game_status', 'w')
f.write(str(data))
(2)把字典从文件中读出来
f = open('game_status', 'r')
data = f.read()
dic = eval(data)
print(dic)

2.json
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
Dumps 只是变成str
Dump 还可以存入文件
import json
data = {
'roles': [
{'role': 'monster', 'type': 'pig', 'life': 50},
{'role': 'hero', 'type': 'dog', 'life': 80},
]
}
d = json.dumps(data) #仅转换为字符串
print(d, type(d))
d2 = json.loads(d) # 将数据从字符串转化为原来的格式
print(d2['roles'])
# 运行结果
{"roles": [{"role": "monster", "type": "pig", "life": 50}, {"role": "hero", "type": "dog", "life": 80}]} <class 'str'>
[{'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': 'dog', 'life': 80}]
import json
data = {
'roles': [
{'role': 'monster', 'type': 'pig', 'life': 50},
{'role': 'hero', 'type': 'dog', 'life': 80},
]
}
f = open('json_1', 'w')
json.dump(data, f) # 把dict数据写入文件
f.close()
f = open('json_1', 'r')
data = json.load(f) # 把数据从文件读出,并且转换为原来的格式
print(data['roles'])
# 运行结果
[{'life': 50, 'role': 'monster', 'type': 'pig'}, {'life': 80, 'role': 'hero', 'type': 'dog'}]

3.pickle
(1)json对不同数据类型操作
# 写入文件
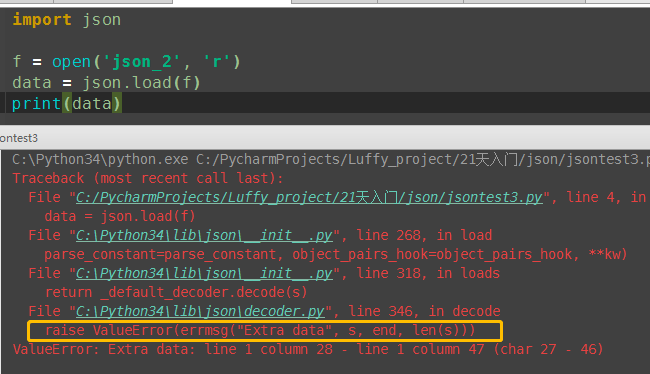
import json
f = open('json_2', 'w')
d1 = {'name': 'alex', 'age': 22}
l1 = [1, 2, 3, 4, 'dfa']
json.dump(d1, f)
json.dump(l1, f) #文件内容
{"name": "alex", "age": 22}[1, 2, 3, 4, "dfa"]
(2)pickle
import pickle
d1 = {'name': 'alex', 'age': 22}
d = pickle.dumps(d1) # 转换为bytes
print(d) # 运行结果
b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00alexq\x02X\x03\x00\x00\x00ageq\x03K\x16u.'
import pickle
d1 = {'name': 'alex', 'age': 22}
l1 = [1, 2, 3, 4, 'dfa'] f = open('pick_1', 'wb')
pickle.dump(d1,f) #dump写入文件
pickle.dump(l1,f)

import pickle
f = open('pick_1', 'rb')
data = pickle.load(f)
print(data)
#运行结果
{'name': 'alex', 'age': 22}
- 不能dump load 多次
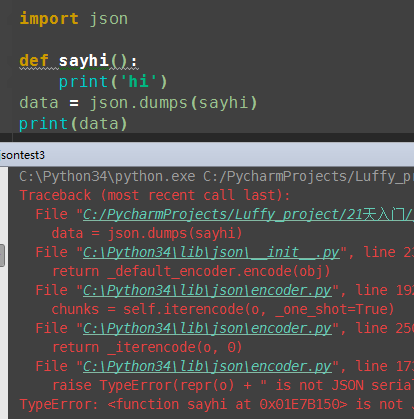
(3)函数也可以pickle 序列化
import pickle def sayhi():
print('hi') data = pickle.dumps(sayhi)
print(data) #结果
b'\x80\x03c__main__\nsayhi\nq\x00.'
4.JSON VS Pickle

JSON:
优点:跨语言、体积小
缺点:只能支持int\str\list\tuple\dict
Pickle:
优点:专为python设计,支持python所有的数据类型
缺点:只能在python中使用,存储数据占空间大
5.shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
(1)序列化
import shelve
f = shelve.open('shelve_test') # 打开一个文件
names = ["alex", "rain", "test"]
info = {'name': 'alex', 'age': 22}
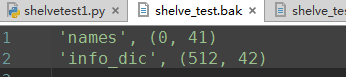
f["names"] = names # 持久化列表
f['info_dic'] = info
f.close()


(2)反序列化
import shelve
d = shelve.open('shelve_test') # 打开一个文件
print(d['names'])
print(d['info_dic'])
#del d['test'] #还可以删除
In [1]: import shelve
In [2]: f = shelve.open('shelve_test')
In [3]: f
Out[3]: <shelve.DbfilenameShelf at 0x36f5190>
In [4]: f.
f.cache f.dict f.keyencoding f.popitem f.update
f.clear f.get f.keys f.setdefault f.values
f.close f.items f.pop f.sync f.writeback
In [4]: f.keys()
Out[4]: KeysView(<shelve.DbfilenameShelf object at 0x036F5190>)
In [5]: list(f.keys())
Out[5]: ['names', 'info_dic']
In [7]: list(f.items())
Out[7]:
[('names', ['alex', 'rain', 'test']),
('info_dic', {'age': 22, 'name': 'alex'})]
In [8]: f.get('names')
Out[8]: ['alex', 'rain', 'test']
In [9]: f.get('info_dic')
Out[9]: {'age': 22, 'name': 'alex'}
In [10]: f['names'][1]
Out[10]: 'rain'
In [12]: f.close()
In [9]: f['names']
Out[9]: ['alex', 'rain', 'test'] In [11]: f['names'][1]
Out[11]: 'rain' In [12]: f['names'][1] = 'RAIN' # 修改不成功 In [13]: f['names']
Out[13]: ['alex', 'rain', 'test'] In [14]: f['names']=[1,2,3] #这样修改 In [15]: f['names']
Out[15]: [1, 2, 3] In [16]: del f['names'] 删除 In [17]: f.get('names')
4
5
19-[模块]-json/pickle、shelve的更多相关文章
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- python 全栈开发,Day25(复习,序列化模块json,pickle,shelve,hashlib模块)
一.复习 反射 必须会 必须能看懂 必须知道在哪儿用 hasattr getattr setattr delattr内置方法 必须能看懂 能用尽量用__len__ len(obj)的结果依赖于obj. ...
- python模块--json \ pickle \ shelve \ XML模块
一.json模块 之前学习过的eval内置方法可以将一个字符串转成一个python对象,不过eval方法时有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,e ...
- 模块 - json/pickle/shelve/xml/configparser
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化: 有种办法可以直接把内存数据(eg:10个列表,3 ...
- python开发模块基础:序列化模块json,pickle,shelve
一,为什么要序列化 # 将原本的字典.列表等内容转换成一个字符串的过程就叫做序列化'''比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给?现在我们能想到的方法就是存在文 ...
- python序列化模块 json&&pickle&&shelve
#序列化模块 #what #什么叫序列化--将原本的字典.列表等内容转换成一个字符串的过程叫做序列化. #why #序列化的目的 ##1.以某种存储形式使自定义对象持久化 ##2.将对象从一个地方传递 ...
- python_ 模块 json pickle shelve
一,什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的代码( ...
- 常用模块(json/pickle/shelve/XML)
一.json模块(重点) 一种跨平台的数据格式 也属于序列化的一种方式 介绍模块之前,三个问题: 序列化是什么? 我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化. 反序列化又是什么? 将 ...
- 保存数据到文件的模块(json,pickle,shelve,configparser,xml)_python
一.各模块的主要功能区别 json模块:将数据对象从内存中完成序列化存储,但是不能对函数和类进行序列化,写入的格式是明文. (与其他大多语言交互的类型) pickle模块:将数据对象从内存中完成序列 ...
- python序列化: json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
随机推荐
- ARDUINO 积木式编辑器整理
原文地址:https://blog.everlearn.tw/arduino/arduino-%E7%A9%8D%E6%9C%A8%E5%BC%8F%E7%B7%A8%E8%BC%AF%E5%99%A ...
- Hadoop HBase概念学习系列之RowKey设计(二十九)
HBase里的RowKey设计,分为随机查询的RowKey设计和连续查询的RowKey设计.
- elif 相当于else&if
if 条件: 语句块 elif 条件: 语句块 ... else #elif好像要有一个else作为结尾
- CSS3动画理解与应用
CSS3动画理解与应用 Transform:对元素进行变形:Transition:对元素某个属性或多个属性的变化,进行控制(时间等),类似flash的补间动画.但只有两个关键贞.开始,结束.Anima ...
- BZOJ 2763 飞行路线 BFS分层
题目链接: https://www.lydsy.com/JudgeOnline/problem.php?id=2763 题目大意: Alice和Bob现在要乘飞机旅行,他们选择了一家相对便宜的航空公司 ...
- cocos2d-x(十一)Lua开发飞机大战-6-加入子弹
接下来我们为飞机加入子弹,首先创建一个BulletLayer: module("BulletLayer",package.seeall) local bulletBatchNode ...
- linux centos 7.5下 源码编译安装 lua环境
lua 5.3.5 下载安装时发现缺少库 readline 需要添加依赖 yum search readline 看有哪些包 安装带有 devel 字样的 安装无 devel 的非开发包,通常不会自动 ...
- HBase学习之路 (十一)HBase的协过滤器
协处理器—Coprocessor 1. 起源 Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执 行求和.计数.排序等操作.比如,在旧版本的(<0.92)Hba ...
- verilog实现毫秒计时器
verilog实现毫秒计时器 整体电路图 实验状态图 Stop代表没有计时,Start代表开始计时,Inc代表计时器加1,Trap代表inc按钮按下去时候的消抖状态. 状态编码表 实验设计思路 时钟分 ...
- Metapackage包
Metapackage(功能包集)是把一些相近的功能模块. 软件包放到一起. ROS里常见的Metapacakge有: 2.Metapackage写法 CMakeLists.txt 写法如下: cma ...