xgboost与gbdt区别
1.基分类器的选择:传统GBDT以CART作为基分类器,XGBoost还支持线性分类器,这个时候XGBoost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
2.二阶泰勒展开:传统GBDT在优化时只用到一阶导数信息;XGBoost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶损失函数的导数。顺便提一下,XGBoost工具支持自定义损失函数,只要函数可一阶和二阶求导。GBDT和GBDT拟合的是都是残差。
a.二阶泰勒展开:
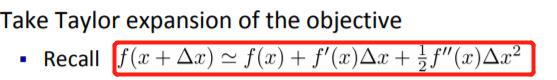
b.xgboost训练:




c.最后等式被优化成这个样子,包含gi和hi两个变量,因为ft(xi)是当前树的预测值,已知,而gi和hi是从损失函数来的,所以自定义的损失函数只要满足一阶和二阶可导就行,因为带入到整体的式子中要满足泰勒二阶展开。
3.方差-方差权衡:XGBoost在目标函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出分数的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是XGBoost优于传统GBDT的一个特性。
4.Shrinkage(缩减):相当于学习速率(xgboost中的)。XGBoost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
5.列抽样(column subsampling):XGBoost借鉴了随机森林的做法,支持列抽样,我们会在同一层的结点分割前先随机选一部分特征,遍历的时候只用遍历这部分特征就行了,不需要便利全部特征,不仅能降低过拟合,还能减少计算,这也是XGBoost异于传统GBDT的一个特性。
6.缺失值处理:XGBoost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率,论文中“枚举”指的不是枚举每个缺失样本在左边还是在右边,而是枚举缺失样本整体在左边,还是在右边两种情况。分裂点还是只评估特征不缺失的样本,paper提到50倍。即对于特征的值有缺失的样本,XGBoost可以自动学习出它的分裂方向。
7.XGBoost工具支持并行:
8.线程缓冲区存储:按照特征列方式存储能优化寻找最佳的分割点,但是当以行计算梯度数据时会导致内存的不连续访问,严重时会导致cache miss,降低算法效率。paper中提到,可先将数据收集到线程内部的buffer(缓冲区),主要是结合多线程、数据压缩、分片的方法,然后再计算,提高算法的效率。
9.可并行的近似直方图算法:树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
xgboost与gbdt区别的更多相关文章
- xgboost和gbdt区别
1. xgboost在目标函数中加入了正则化项,当正则化项为0时与传统的GDBT的目标函数相同2. xgboost在迭代优化的时候使用了目标函数的泰勒展开的二阶近似,paper中说能加快优化的过程!! ...
- 随机森林RF、XGBoost、GBDT和LightGBM的原理和区别
目录 1.基本知识点介绍 2.各个算法原理 2.1 随机森林 -- RandomForest 2.2 XGBoost算法 2.3 GBDT算法(Gradient Boosting Decision T ...
- Adaboost和GBDT的区别以及xgboost和GBDT的区别
Adaboost和GBDT的区别以及xgboost和GBDT的区别 以下内容转自 https://blog.csdn.net/chengfulukou/article/details/76906710 ...
- rf, xgboost和GBDT对比;xgboost和lightGbm
1. RF 随机森林基于Bagging的策略是Bagging的扩展变体,概括RF包括四个部分:1.随机选择样本(放回抽样):2.随机选择特征(相比普通通bagging多了特征采样):3.构建决策树:4 ...
- xgboost 和GBDT的区别
作者:wepon链接:https://www.zhihu.com/question/41354392/answer/98658997来源:知乎 传统GBDT以CART作为基分类器,xgboost还支持 ...
- 前向分步算法 && AdaBoost算法 && 提升树(GBDT)算法 && XGBoost算法
1. 提升方法 提升(boosting)方法是一种常用的统计学方法,在分类问题中,它通过逐轮不断改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能 0x1: 提升方法的基本 ...
- 机器学习算法总结(四)——GBDT与XGBOOST
Boosting方法实际上是采用加法模型与前向分布算法.在上一篇提到的Adaboost算法也可以用加法模型和前向分布算法来表示.以决策树为基学习器的提升方法称为提升树(Boosting Tree).对 ...
- Boosting学习笔记(Adboost、GBDT、Xgboost)
转载请注明出处:http://www.cnblogs.com/willnote/p/6801496.html 前言 本文为学习boosting时整理的笔记,全文主要包括以下几个部分: 对集成学习进行了 ...
- 机器学习(八)—GBDT 与 XGBOOST
RF.GBDT和XGBoost都属于集成学习(Ensemble Learning),集成学习的目的是通过结合多个基学习器的预测结果来改善单个学习器的泛化能力和鲁棒性. 根据个体学习器的生成方式,目前 ...
随机推荐
- Java 容器 LinkedHashMap源码分析1
同 HashMap 一样,LinkedHashMap 也是对 Map 接口的一种基于链表和哈希表的实现.实际上, LinkedHashMap 是 HashMap 的子类,其扩展了 HashMap 增加 ...
- ASP.NET 中 <%= %> 与 <%: %> 的区别
做个备忘 <%= %> 内容原封不动输出 <%: %> 对内容进行编码后输出 即:<%: str %> 等价于 <%= Html.Encode(str) %& ...
- Debezium for PostgreSQL to Kafka
In this article, we discuss the necessity of segregate data model for read and write and use event s ...
- 创建TFS备份计划失败,错误提示:TF400997
问题描述 在一个TFS 2018 + SQL Server 2017的环境中,从TFS控制台中配置备份计划时,系统提示错误TF400997,需要授予数据库服务账户sqlservice@domain.c ...
- MSMQ理论+实践(上)
关于MSMQ使用的文章,网上一搜一大把,为什么还要写呢?因为别人的终究是别人的,看一遍,只是过眼云烟罢了,还是要自己动手实践一下,才能把别人的变成自己的.再者就是网上大都是在一台电脑上写的demo,我 ...
- Ruby on Rails 生成指定版本的 Rails 项目
ruby-on-rails ruby 本地 Rails 默认5.1.6 版本 $ gem list --local rails (5.1.6, 5.1.5, 5.1.4) 使用 version 生成指 ...
- IdentityServer4中文文档
欢迎IdentityServer4 IdentityServer4是ASP.NET Core 2的OpenID Connect和OAuth 2.0框架. 它在您的应用程序中启用以下功能: 认证即服务 ...
- 在Asp.net Core中使用中间件来管理websocket
介绍 ASP.NET Core SignalR是一个有用的库,可以简化Web应用程序中实时通信的管理.但是,我宁愿使用WebSockets,因为我想要更灵活,并且与任何WebSocket客户端兼容. ...
- jsp的九大内置对象(查询资料,搬砖所得)
此笔记大部分摘自大神https://www.cnblogs.com/SimonHu1993/,部分通过网上搜寻补充. 1.Request内置对象(类型:HttpServletRequest 表示 ...
- 雨天的尾巴(bzoj3307)(线段树合并+树上差分)
\(N\)个点,形成一个树状结构.有\(M\)次发放,每次选择两个点\(x,y\) 对于\(x\)到\(y\)的路径上(含\(x,y\))每个点发一袋\(Z\)类型的物品.完成 所有发放后,每个点存放 ...