xgboost与gbdt区别
1.基分类器的选择:传统GBDT以CART作为基分类器,XGBoost还支持线性分类器,这个时候XGBoost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
2.二阶泰勒展开:传统GBDT在优化时只用到一阶导数信息;XGBoost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶损失函数的导数。顺便提一下,XGBoost工具支持自定义损失函数,只要函数可一阶和二阶求导。GBDT和GBDT拟合的是都是残差。
a.二阶泰勒展开:
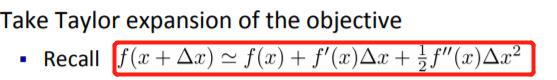
b.xgboost训练:




c.最后等式被优化成这个样子,包含gi和hi两个变量,因为ft(xi)是当前树的预测值,已知,而gi和hi是从损失函数来的,所以自定义的损失函数只要满足一阶和二阶可导就行,因为带入到整体的式子中要满足泰勒二阶展开。
3.方差-方差权衡:XGBoost在目标函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出分数的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是XGBoost优于传统GBDT的一个特性。
4.Shrinkage(缩减):相当于学习速率(xgboost中的)。XGBoost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
5.列抽样(column subsampling):XGBoost借鉴了随机森林的做法,支持列抽样,我们会在同一层的结点分割前先随机选一部分特征,遍历的时候只用遍历这部分特征就行了,不需要便利全部特征,不仅能降低过拟合,还能减少计算,这也是XGBoost异于传统GBDT的一个特性。
6.缺失值处理:XGBoost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率,论文中“枚举”指的不是枚举每个缺失样本在左边还是在右边,而是枚举缺失样本整体在左边,还是在右边两种情况。分裂点还是只评估特征不缺失的样本,paper提到50倍。即对于特征的值有缺失的样本,XGBoost可以自动学习出它的分裂方向。
7.XGBoost工具支持并行:
8.线程缓冲区存储:按照特征列方式存储能优化寻找最佳的分割点,但是当以行计算梯度数据时会导致内存的不连续访问,严重时会导致cache miss,降低算法效率。paper中提到,可先将数据收集到线程内部的buffer(缓冲区),主要是结合多线程、数据压缩、分片的方法,然后再计算,提高算法的效率。
9.可并行的近似直方图算法:树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
xgboost与gbdt区别的更多相关文章
- xgboost和gbdt区别
1. xgboost在目标函数中加入了正则化项,当正则化项为0时与传统的GDBT的目标函数相同2. xgboost在迭代优化的时候使用了目标函数的泰勒展开的二阶近似,paper中说能加快优化的过程!! ...
- 随机森林RF、XGBoost、GBDT和LightGBM的原理和区别
目录 1.基本知识点介绍 2.各个算法原理 2.1 随机森林 -- RandomForest 2.2 XGBoost算法 2.3 GBDT算法(Gradient Boosting Decision T ...
- Adaboost和GBDT的区别以及xgboost和GBDT的区别
Adaboost和GBDT的区别以及xgboost和GBDT的区别 以下内容转自 https://blog.csdn.net/chengfulukou/article/details/76906710 ...
- rf, xgboost和GBDT对比;xgboost和lightGbm
1. RF 随机森林基于Bagging的策略是Bagging的扩展变体,概括RF包括四个部分:1.随机选择样本(放回抽样):2.随机选择特征(相比普通通bagging多了特征采样):3.构建决策树:4 ...
- xgboost 和GBDT的区别
作者:wepon链接:https://www.zhihu.com/question/41354392/answer/98658997来源:知乎 传统GBDT以CART作为基分类器,xgboost还支持 ...
- 前向分步算法 && AdaBoost算法 && 提升树(GBDT)算法 && XGBoost算法
1. 提升方法 提升(boosting)方法是一种常用的统计学方法,在分类问题中,它通过逐轮不断改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能 0x1: 提升方法的基本 ...
- 机器学习算法总结(四)——GBDT与XGBOOST
Boosting方法实际上是采用加法模型与前向分布算法.在上一篇提到的Adaboost算法也可以用加法模型和前向分布算法来表示.以决策树为基学习器的提升方法称为提升树(Boosting Tree).对 ...
- Boosting学习笔记(Adboost、GBDT、Xgboost)
转载请注明出处:http://www.cnblogs.com/willnote/p/6801496.html 前言 本文为学习boosting时整理的笔记,全文主要包括以下几个部分: 对集成学习进行了 ...
- 机器学习(八)—GBDT 与 XGBOOST
RF.GBDT和XGBoost都属于集成学习(Ensemble Learning),集成学习的目的是通过结合多个基学习器的预测结果来改善单个学习器的泛化能力和鲁棒性. 根据个体学习器的生成方式,目前 ...
随机推荐
- (小数化分数)小数化分数2 -- HDU --1717
链接: http://acm.hdu.edu.cn/showproblem.php?pid=1717 举例: 0.24333333…………=(243-24)/900=73/3000.9545454…… ...
- Codeforces 632D Longest Subsequence 2016-09-28 21:29 37人阅读 评论(0) 收藏
D. Longest Subsequence time limit per test 2 seconds memory limit per test 256 megabytes input stand ...
- Mongodb 存储日志信息
线上运行的服务会产生大量的运行及访问日志,日志里会包含一些错误.警告.及用户行为等信息,通常服务会以文本的形式记录日志信息,这样可读性强,方便于日常定位问题,但当产生大量的日志之后,要想从大量日志里挖 ...
- hdu 1116 欧拉回路+并查集
http://acm.hdu.edu.cn/showproblem.php?pid=1116 给你一些英文单词,判断所有单词能不能连成一串,类似成语接龙的意思.但是如果有多个重复的单词时,也必须满足这 ...
- Spine输出资源一键入Unity3D工具代码
之前预研过2D骨骼动画编辑工具SPINE,感觉其比cocosStudio及Unity3D自带的骨骼动画编辑器(原生Sprite Tree或Uni2D)要更适合有3DSMax习惯的美术,即Spine更容 ...
- WPF核心对象模型-类图和解析
DispatcherObject是根基类,通过继承该类,可以得到访问创建该对象的UI线程的Dispatcher对象的能力.通过Dispatcher对象,可以将代码段合并入该UI线程执行. Depend ...
- WPF 最简单的TextBox水印
最简单的TextBox加水印的方法,但是不具有很强的通用性. 如果你只是使用一次,或者用的不多,偷偷懒可以使用. 因为此方法只需要修改TextBox的Template,而不用重写何任代码. 注意: 1 ...
- C#存储过程调用的三个方法
//带参数的SQL语句 private void sql_param() { SqlConnection conn = new SqlConnection("server=WIN-OUD59 ...
- 转(C# 实现生产者消费者队列)
class Program { // 任务队列 static Queue<string> _tasks = new Queue<string>(); // 为保证线程安全,使用 ...
- matlab学习笔记---(1)
Matlab学习笔记 一. Desktop Basics (Matlab 基础知识) 当你打开Matlab的时候,matlab按照以下默认的方式展示出来. 该桌面主要包括以下几部分内容: 当前文件夹: ...