TensorFlow分布式部署【多机多卡】
让TensorFlow们飞一会儿
前一篇文章说过了TensorFlow单机多卡情况下的分布式部署,毕竟,一台机器势单力薄,想叫兄弟们一起来算神经网络怎么办?我们这次来介绍一下多机多卡的分布式部署。
其实多机多卡分布式部署在我看来相较于单机多卡分布式更容易一些,因为一台机器下需要考虑我需要把给每个device分配哪些操作,这个过程很繁琐。多台机器虽然看起来更繁琐,然而我们可以把每一台机器看作是一个单卡的机器,并且谷歌爸爸已经把相对复杂的函数都给封装好了,我们直接拿来用就行。为什么这么说呢?我们首先介绍两个概念In-graph模式和Between-graph模式:
In-graph模式: 这个模式跟单机单卡是差不多的,我们需要把不同的节点分配给不同的设备,比如说我让某台机器的某个GPU做一部分卷积,另外某台机器的某个GPU做另外一部分卷积,这样大家都有活干。想象总是美好的,在实际情况中会出现什么问题呢?数据搬移量太大,会有相当一部分时间耗费再数据搬移之下,Tensor翻山越岭,穿过网线,来到一个设备中,凳子还没坐热,有出发去另外一个设备。在大量训练数据的情况下,这种方法往往是不可取的。
Between-graph模式: 这个模式下每一个设备都相当于独立的完成整个卷积神经网络的操作,只是在开始时从参数服务器中取到参数,然后结束的时候送回参数。所以除了chief节点以外,所有人都可以在训练过程中随时退出,随时加入,但是刚开始时,大家都要响应一下chief节点的号召。这样显然更合理一点,在大量数据的情况下我们会选用这个方法,下面的代码也会以Between-graph模式作为例子。
上文提到在Between-graph模式下我们需要在训练过程中从参数服务器中获取参数,那么问题来了,什么是参数服务器?接下来我们再引入两个概念(忍一下忍一下,很简单):
参数服务器:顾名思义,参数服务器嘛,保存参数用的服务器,简称ps(paramEter severs)。参数服务器可以不止一个,如果参数量过大的话,我们可以多叫几台计算机过来充当参数服务器,用来更新参数。
工作服务器: 顾名思义,工作服务器嘛,干活的,简称worker。一般为GPU们,能够进行快速并行计算的设备,它可以从参数服务器中把参数荡下来,然后计算出来以后在传上去。
基础的介绍完了,同样的每个工作模式下都会有参数同步更新和异步更新,下面放张就是那么个意思的图(现在没图都不好写博客了…)。
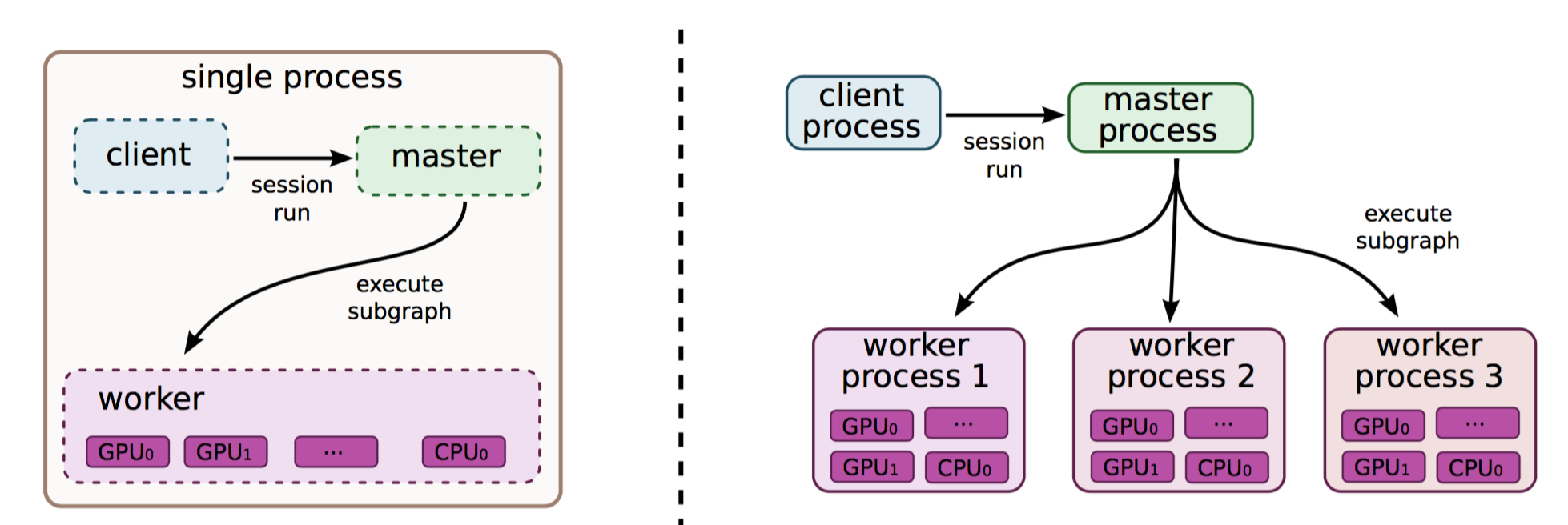
好,总结一下,我们可以设置多个参数服务器(ps)用来存储更新参数,同时我们也可以设置多个工作服务器(worker)用来进行计算。这样就组成了一个多机多卡分布式的Tensorflow开发环境。
TensorFlow分布式部署【多机多卡】的更多相关文章
- TensorFlow分布式部署【单机多卡】
让TensorFlow飞一会儿 面对大型的深度神经网络训练工程,训练的时间非常重要.训练的时间长短依赖于计算处理器也就是GPU,然而单个GPU的计算能力有限,利用多个GPU进行分布式部署,同时完成一个 ...
- Tensorflow分布式部署和开发
关于tensorflow的分布式训练和部署, 官方有个英文的文档介绍,但是写的比较简单, 给的例子也比较简单,刚接触分布式深度学习的可能不太容易理解.在网上看到一些资料,总感觉说的不够通俗易懂,不如自 ...
- [翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed ...
- Jmeter 压力测试笔记(4)--分布式部署
分布式部署:坑,大坑~ 超级坑~~~~ 在这里坑了2天,整整2天.其它略过不表下面只写经验: 在linux下,centos7系统 1主 14执行机. jmeter版本 5.2.1 所有机器在同一 ...
- [源码解析] TensorFlow 分布式 DistributedStrategy 之基础篇
[源码解析] TensorFlow 分布式 DistributedStrategy 之基础篇 目录 [源码解析] TensorFlow 分布式 DistributedStrategy 之基础篇 1. ...
- Zabbix监控和分布式部署实施方案
最近在研究Zabbix监控,由于机房分布在多个城市,因此采用zabbix proxy做为监控方案,在每 个节点部署zabbix proxy,由zabbix proxy收集agentd数据,然后将采集到 ...
- 深度学习多机多卡解决方案-purine
未经允许请不要转载,原作者:zhxfl,http://www.cnblogs.com/zhxfl/p/5287644.html 目录: 一.简介 二.环境配置 三.运行demo 四.硬件配置建议 五. ...
- Hadoop 2.6.0分布式部署參考手冊
Hadoop 2.6.0分布式部署參考手冊 关于本參考手冊的word文档.能够到例如以下地址下载:http://download.csdn.net/detail/u012875880/8291493 ...
- Apache/nginx转发设置-分布式部署
Apache转发设置1. Weblogic安装 Weblogic8和Weblogic10默认安装,选择完全安装即可,如果是Weblogic9则选择自定义安装,勾选WebService plugin 2 ...
随机推荐
- 【xsy1162】鬼计之夜 最短路+二进制拆分
套路题(然而我没看题解做不出来) 题目大意:给你一个$n$个点,$m$条有向边的图.图中有$k$个标记点,求距离最近的标记点间距离. 数据范围:$n,m,k≤10^5$. 设$p_i表$示第$i$个标 ...
- mysql互为主从实战设置详解及自动化备份(Centos7.2)
mysql互为主从实战设置详解(Centos7.2) 第一步:mysql配置 my.cnf配置 服务器1 (10.89.10.90) [mysqld] server-id=1 log-bin=/ ...
- (转)python字符串函数
原文:https://www.cnblogs.com/emanlee/p/3616755.html https://blog.csdn.net/luoyhang003/article/details/ ...
- (转)windows 2003 远程桌面关闭 运行程序退出解决
windows 2003 远程桌面关闭 运行程序退出解决 原文:http://2798996.blog.51cto.com/2788996/503365 情况:远程桌面到2003,运行一个程序,然后关 ...
- JVM调优一些相关内容
JVM调优工具 Jconsole,jProfile,VisualVM Jconsole : jdk自带,功能简单,但是可以在系统有一定负荷的情况下使用.对垃圾回收算法有很详细的跟踪.详细说明参考这里 ...
- ActiveMQ发布-订阅消息模式
一.订阅杂志我们很多人都订过杂志,其过程很简单.只要告诉邮局我们所要订的杂志名.投递的地址,付了钱就OK.出版社定期会将出版的杂志交给邮局,邮局会根据订阅的列表,将杂志送达消费者手中.这样我们就可以看 ...
- expect安装和使用
Expect是一个我们常在shell交互时常用到的工具,它主要由expect-send组成.Expect是等待输出内容中的特定字符.然后由send发送特定的相应.Expect的工作流程类似于:小明和小 ...
- centos7-windows10 双系统安装
win10默认, 然后压缩出来一个卷安装win7: http://www.techweb.com.cn/network/system/2016-12-21/2456741.shtml http://b ...
- springboot-10-前端页面整合, thymeleaf, freemarker, jsp 模板使用
springboot 中不建议使用jsp作为页面展示, 怎么使用可以看: http://412887952-qq-com.iteye.com/blog/2292471 关于什么是thymeleaf, ...
- echarts 雷达图的个性化设置
echarts 雷达图的个性化设置 function test() { let myChart = echarts.init(document.getElementById('levelImage') ...