Elasticsearch基础分布式架构
写在前面的话:读书破万卷,编码如有神
--------------------------------------------------------------------
参考内容:
《Elasticsearch顶尖高手系列-快速入门篇》,中华石杉
--------------------------------------------------------------------
主要内容包括:
- Elasticsearch对复杂分布式机制的透明隐藏特性
- Elasticsearch的垂直扩容与水平扩容
- 增加或减少节点时的数据rebalance
- master节点
- 节点平等的分布式架构
- primary shard和replica shard机制再次梳理
- 单node环境下创建index是什么样子的
- 2个node环境下replica shard是如何分配的
--------------------------------------------------------------------
1、Elasticsearch对复杂分布式机制的透明隐藏特性
Elasticsearch是一套分布式系统,分布式是为了应对大数据量。
Elasticsearch隐藏了复杂的分布式机制:
- 分片:我们之前随随便便就将一些document插入到es集群中去了,我们没有关心过数据是如何进行分配的、数据到哪个shard中去了。
- 集群发现机制(cluster discovery):如果启动一个新的es进程,那么这个es进程会作为一个node并且发现es集群,然后自动加入进去。
- shard负载均衡:举例,假设现在有3个节点,总共有25个shard要分配到3个节点上去,es会自动进行均分分配,以保证每个节点的均衡的读写负载请求
- shard副本
- 请求路由
- 集群扩容
- shard重分配
--------------------------------------------------------------------
2、Elasticsearch的垂直扩容与水平扩容
扩容方案:
6台服务器,每台容纳1T的数据,马上数据量要增长到8T,这个时候有两个方案。
(1)垂直扩容:重新购置两台服务器,每台服务器的容量就是2T,替换掉老的两台服务器,那么现在6台服务器的总容量就是 4 * 1T + 2 * 2T = 8T。
(2)水平扩容:新购置两台服务器,每台服务器的容量就是1T,直接加入到集群中去,那么现在服务器的总容量就是8 * 1T = 8T
垂直扩容:采购更强大的服务器 ,成本非常高昂,而且会有瓶颈,假设世界上最强大的服务器容量就是10T,但是当你的总数量达到5000T的时候,你要采购多少台最强大的服务器啊。
水平扩容:业界经常采用的方案,采购越来越多的普通服务器,性能比较一般,但是很多普通服务器组织在一起,就能构成强大的计算和存储能力。
--------------------------------------------------------------------
3、增加或减少节点时的数据rebalance
比如现在有4个node,其中3个node中有一个shard,1个node中有2个shard,但是这个时候如果有一个新的node加入进来,则es会自动把其中一个shard分配到刚加入的node上去。
--------------------------------------------------------------------
4、master节点
一个es集群中总会有一个node是master节点:
- 管理es集群的元数据:比如说索引的创建和删除、维护索引元数据;节点的增加和移除、维护集群的数据
- 默认情况下,会自动选择出一台节点作为master节点
- master节点不承载所有的请求,所以不会是单点瓶颈
--------------------------------------------------------------------
5、节点平等的分布式架构
(1)节点对等,每个节点都能接收所有的请求
(2)自动请求路由:任何一个节点接收到请求后,都可以把这个请求自动路由到相关节点上去处理该请求。
(3)响应收集:最原始节点会从其他节点接收响应数据,然后把这些数据返回给客户端。
--------------------------------------------------------------------
6、primary shard 和 replica shard机制再次梳理
(1)一个索引(index)包含多个shard
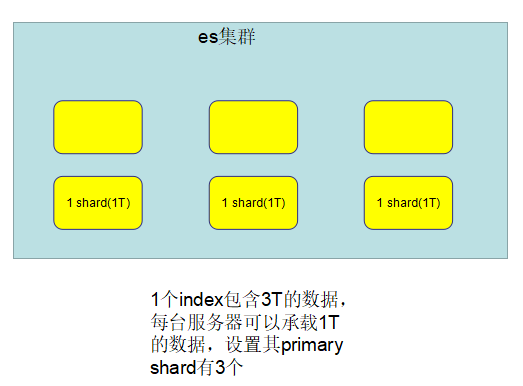
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力。

(3)增减节点时,shard会自动在nodes中负载均衡。

(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shrad中,不可能存在于多个primary shard。
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载。
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改。
(7)primary shard的默认数量是5,replica shrad默认数量是1。
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机时,primary shard和replica shard都丢失了,起不到容错的作用。),但是可以和其它primary shard的replica shard放在同一个节点上。
--------------------------------------------------------------------
7、单node环境下创建index是什么样子的
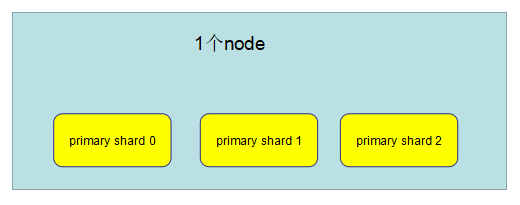
(1)单node环境下,创建一个index: 有3个primary shard、3个replica shard
(2)集群状态是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承担任何请求
------------------------------------------------------------------
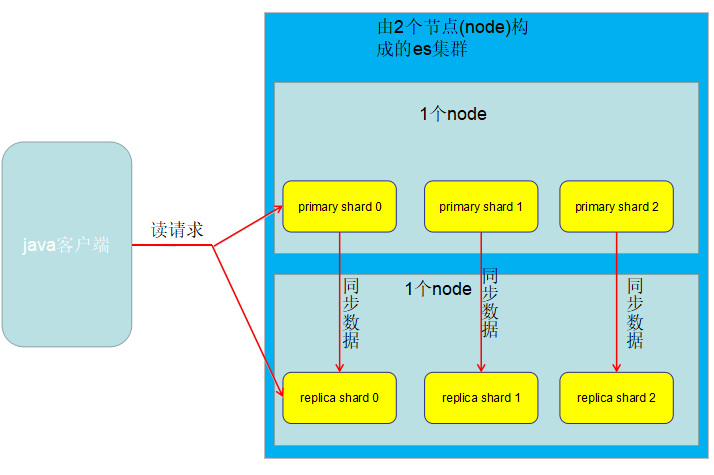
8、两个node环境下replica shard是如何分配的
此时的情况,1个node、3个primary shard、3个replica shard
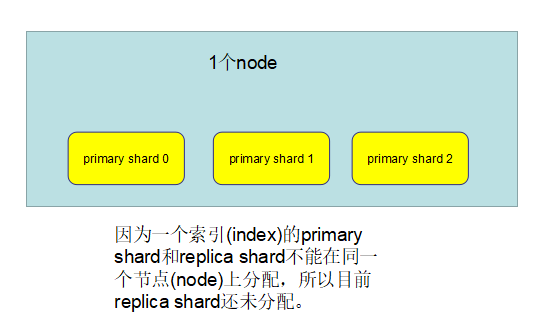
如果此时新增一个node进来,构成了一个由2个node组成的es集群,如下:
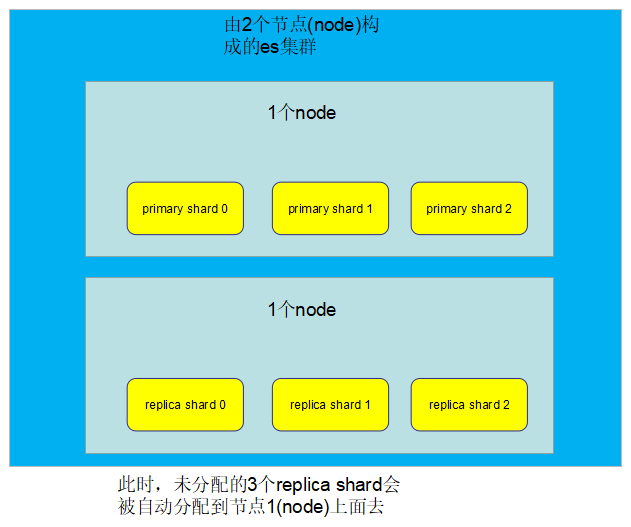
并且:
- primary shard会自动把数据同步到对应的replica shard上去
- 客户端的读请求可以发送到primary shard上去,也可以发送到replica shard上去
Elasticsearch基础分布式架构的更多相关文章
- Elasticsearch由浅入深(二)ES基础分布式架构、横向扩容、容错机制
Elasticsearch的基础分布式架构 Elasticsearch对复杂分布式机制的透明隐藏特性 Elasticsearch是一套分布式系统,分布式是为了应对大数据量. Elasticsearch ...
- Elasticsearch系列---分布式架构机制讲解
概要 本篇主要介绍Elasticsearch的数据索引时的分片机制,集群发现机制,primary shard与replica shard是如何分工合作的,如何对集群扩容,以及集群的容错机制. 分片机制 ...
- elasticsearch从入门到出门-06-剖析Elasticsearch的基础分布式架构
这个图来自中华石杉:
- elasticsearch 基础 —— 分布式文档存储原理
路由一个文档到一个分片中 当索引一个文档的时候,文档会被存储到一个主分片中. Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 ...
- elasticsearch的分布式基础概念(1)
Elasticsearch对复杂分布式机制的透明隐藏特性 Elasticsearch是一套分布式的系统,分布式是为了应对大数据量 隐藏了复杂的分布式机制 分片机制(随随便便就将一些document插入 ...
- .Net 大型分布式基础服务架构横向演变概述
一. 业务背景 构建具备高可用,高扩展性,高性能,能承载高并发,大流量的分布式电子商务平台,支持用户,订单,采购,物流,配送,财务等多个项目的协作,便于后续运营报表,分析,便于运维及监控. 二. 基础 ...
- 【分布式搜索引擎】Elasticsearch分布式架构原理
一.相关概念介绍 1)集群(cluster) 一个集群(cluster)由一个或多个节点组成. 这些节点具有相同的cluster.name,它们协同工作,分享数据和负载.当加入新的节点或者删除一个节点 ...
- .Net 大型分布式基础服务架构横向演变概述(转)
一. 业务背景 构建具备高可用,高扩展性,高性能,能承载高并发,大流量的分布式电子商务平台,支持用户,订单,采购,物流,配送,财务等多个项目的协作,便于后续运营报表,分析,便于运维及监控. 二. 基础 ...
- 【转载】.Net 大型分布式基础服务架构横向演变概述
原文:https://www.cnblogs.com/chejiangyi/p/5220217.html 一. 业务背景 构建具备高可用,高扩展性,高性能,能承载高并发,大流量的分布式电子商务平台,支 ...
随机推荐
- nginx配置浅析
一.nginx的介绍 nginx是由俄罗斯人开发的一款高性能的http和反向代理服务器,也可以用来作为邮件代理.相比较于其他的服务器,具有占用内存少,稳定性高等优势 二.nginx的配置 nginx的 ...
- imperva 默认策略添加例外
创建违规访问 检查违规的告警类型 假如客户的这个目录下真的有这个文件,而且客户非常明确这是一个正常且安全的东西怎么办?我该如何的将它添加到例外? 添加例外的步骤: 再次构造违规的请求: 默认策略添加例 ...
- eclipse安装阿里代码扫描插件
1.首先打开eclipse软件,点击工具栏上的Help,选择Install New Soft进行安装新的插件. 2.进入插件安装界面,点击Add,弹出插件地址填写界面,也可以直接在市场上搜索关键字al ...
- IntelliJ IDEA 修改IDE字体、代码字体。
IntelliJ IDEA 默认的 IDE 菜单字体太小,看着不舒服 ,我们调节下: ==============以上修改 仅仅针对的IDE字体,对代码的字体不生效. 所以如果代码 你觉得小 还得修改 ...
- 教您如何进行SQL跨表更新
SQL跨表更新数据是在使用SQL数据库中比较常用的,下面就将为您详细介绍SQL跨表更新数据的步骤,希望对您学习SQL跨表更新数据有所启迪. 原始数据如下,首先是表结构 A_dept的初始数据 A_em ...
- c 语言文本文件判断是否到达结尾的问题
在c语言中,判断文件结尾有两种方法,第一种是使用feof()函数,feof(fp)用于测试fp所指向的文件的当前状态是否为“文件结束”.如果是,函数则返回的是非0值(真),否则为0(假),要注意的是, ...
- 【笔记】Python简明教程
Python简明教程,此资源位于http://woodpecker.org.cn/abyteofpython_cn/chinese/ s=u'中文字符' #u表示unicode,使用u之后能正常显示中 ...
- CCF CSP 201604-4 游戏
CCF计算机职业资格认证考试题解系列文章为meelo原创,请务必以链接形式注明本文地址 CCF CSP 201604-4 游戏 问题描述 小明在玩一个电脑游戏,游戏在一个n×m的方格图上进行,小明控制 ...
- 初识angularJS的基本概念
今天在这里分享分享我个人学习angular的知识点总结.在还没有接触到angular的时候,还真的不知道它到底有什么作用,直到我开始学习它,并且运用到它的时候,才知道angular这么强大.作为一个前 ...
- USACO 6.5 Checker Challenge
Checker Challenge Examine the 6x6 checkerboard below and note that the six checkers are arranged on ...