高并发第八弹:J.U.C起航(java.util.concurrent)
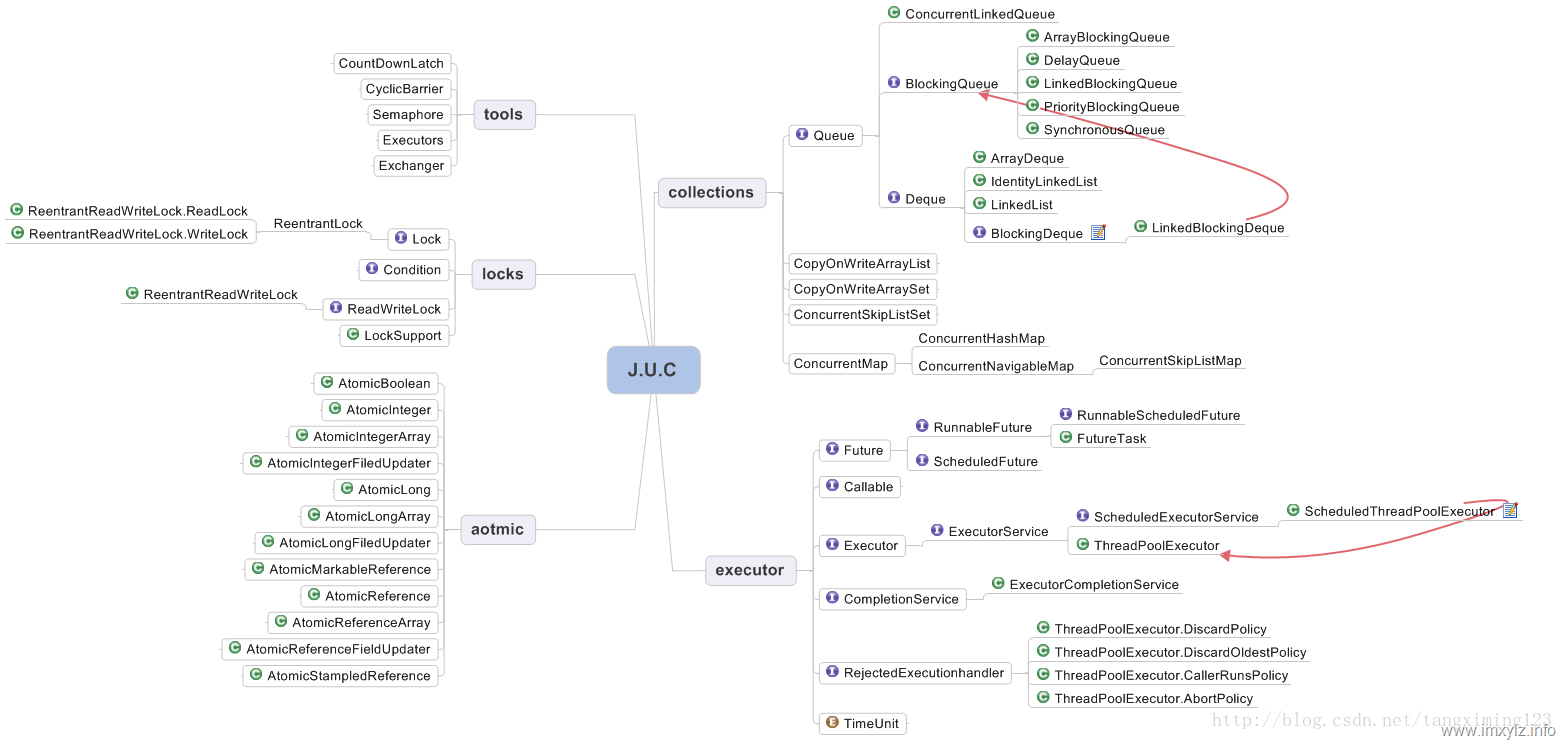
java.util.concurrent是JDK自带的一个并发的包主要分为以下5部分:
- 并发工具类(tools)
- 显示锁(locks)
- 原子变量类(aotmic)
- 并发集合(collections)
- Executor线程执行器
我们今天就说说 并发集合,除开 Queue,放在线程池的时候讲
先介绍以下 CopyOnWrite:
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到 .
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final long serialVersionUID = 8673264195747942595L; /** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock(); /** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array; ............................
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();//获取当前数组数据
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); //复制当前数组并且扩容+1
newElements[len] = e;
setArray(newElements);//将原来的数组指向新的数组
return true;
} finally {
lock.unlock();
}
}
下面这篇文章验证了CopyOnWriteArrayList和同步容器的性能:
http://blog.csdn.net/wind5shy/article/details/5396887
下面这篇文章简单描述了CopyOnWriteArrayList的使用:
http://blog.csdn.net/imzoer/article/details/9751591
因为 网友总结的优缺点是:
缺点:
1.写操作时复制消耗内存,如果元素比较多时候,容易导致young gc 和full gc。
2.不能用于实时读的场景.由于复制和add操作等需要时间,故读取时可能读到旧值。
能做到最终一致性,但无法满足实时性的要求,更适合读多写少的场景。
如果无法知道数组有多大,或者add,set操作有多少,慎用此类,在大量的复制副本的过程中很容易出错。设计思想:
1.读写分离
2.最终一致性
3.使用时另外开辟空间,防止并发冲突
这个还真是主要是针对 读多的条件.毕竟写一个就要开辟一个空间.太耗资源了.其实还是建议用手动的方式来控制集合的并发.
1. ArrayList –> CopyOnWriteArrayList
它相当于线程安全的ArrayList。和ArrayList一样,它是个可变数组;但是和ArrayList不同的时,它具有以下特性:
1. 它最适合于具有以下特征的应用程序:List 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等操作。
5. 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
2. HashSet –> CopyOnWriteArraySet
它是线程安全的无序的集合,可以将它理解成线程安全的HashSet。有意思的是,CopyOnWriteArraySet和HashSet虽然都继承于共同的父类AbstractSet;但是,HashSet是通过“散列表(HashMap)”实现的,而CopyOnWriteArraySet则是通过“动态数组(CopyOnWriteArrayList)”实现的,并不是散列表。
和CopyOnWriteArrayList类似,CopyOnWriteArraySet具有以下特性:
1. 它最适合于具有以下特征的应用程序:Set 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等 操作。
5. 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
SkipList 跳表:先介绍这个吧
介绍的很详细 https://blog.csdn.net/sunxianghuang/article/details/52221913
更优秀的 :https://www.cnblogs.com/skywang12345/p/3498556.html
总结起来就是:
传统意义的单链表是一个线性结构,向有序的链表中插入一个节点需要O(n)的时间,查找操作需要O(n)的时间
跳表查找的复杂度为O(n/2)。跳跃表其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
先以数据“7,14,21,32,37,71,85”序列为例,来对跳表进行简单说明。

跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在“需要找出值为32的节点”为例,来对比说明跳表和普遍的链表。
情况1:链表中查找“32”节点
路径如下图1-02所示:

需要4步(红色部分表示路径)。
情况2:跳表中查找“32”节点
路径如下图1-03所示:
忽略索引垂直线路上路径的情况下,只需要2步(红色部分表示路径)。
先以数据“7,14,21,32,37,71,85”序列为例,来对跳表进行简单说明。
跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在“需要找出值为32的节点”为例,来对比说明跳表和普遍的链表。
情况1:链表中查找“32”节点
路径如下图1-02所示:
需要4步(红色部分表示路径)。
情况2:跳表中查找“32”节点
路径如下图1-03所示:
忽略索引垂直线路上路径的情况下,只需要2步(红色部分表示路径)。
3. TreeMap –> ConcurrentSkipListMap
下面说说Java中ConcurrentSkipListMap的数据结构。
(01) ConcurrentSkipListMap继承于AbstractMap类,也就意味着它是一个哈希表。
(02) Index是ConcurrentSkipListMap的内部类,它与“跳表中的索引相对应”。HeadIndex继承于Index,ConcurrentSkipListMap中含有一个HeadIndex的对象head,head是“跳表的表头”。
(03) Index是跳表中的索引,它包含“右索引的指针(right)”,“下索引的指针(down)”和“哈希表节点node”。node是Node的对象,Node也是ConcurrentSkipListMap中的内部类。
/**
* Special value used to identify base-level header
*/
private static final Object BASE_HEADER = new Object(); /**
* 跳表的最顶层索引
*/
private transient volatile HeadIndex<K,V> head; /**
*
* 比较器用于维护此映射中的顺序,或者如果使用自然排序,则为空。(非私有的,以
* 简化嵌套类中的访问)。
*
*/
final Comparator<? super K> comparator; /** Lazily initialized key set */ //懒惰初始化密钥集
private transient KeySet<K> keySet;
/** Lazily initialized entry set */
private transient EntrySet<K,V> entrySet;
/** Lazily initialized values collection */
private transient Values<V> values;
/** Lazily initialized descending key set */
源码我也没精力去详勘了.就总结一下
4. TreeSet –> ConcurrentSkipListSet
(01) ConcurrentSkipListSet继承于AbstractSet。因此,它本质上是一个集合。
(02) ConcurrentSkipListSet实现了NavigableSet接口。因此,ConcurrentSkipListSet是一个有序的集合。
(03) ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的。它包含一个ConcurrentNavigableMap对象m,而m对象实际上是ConcurrentNavigableMap的实现类ConcurrentSkipListMap的实例。ConcurrentSkipListMap中的元素是key-value键值对;而ConcurrentSkipListSet是集合,它只用到了ConcurrentSkipListMap中的key!
(4)同其他set集合,是基于map集合的(基于ConcurrentSkipListMap),在多线程环境下,里面的contains、add、remove操作都是线程安全的。
(5)多个线程可以安全的并发的执行插入、移除、和访问操作。但是对于批量操作addAll、removeAll、retainAll和containsAll并不能保证以原子方式执行,原因是addAll、removeAll、retainAll底层调用的还是 contains、add、remove方法,只能保证每一次的执行是原子性的,代表在单一执行操纵时不会被打断,但是不能保证每一次批量操作都不会被打断。在使用批量操作时,还是需要手动加上同步操作的。
(6)不允许使用null元素的,它无法可靠的将参数及返回值与不存在的元素区分开来。
5. HashMap –> ConcurrentHashMap
- 不允许空值,在实际的应用中除了少数的插入操作和删除操作外,绝大多数我们使用map都是读取操作。而且读操作大多数都是成功的。基于这个前提,它针对读操作做了大量的优化。因此这个类在高并发环境下有特别好的表现。
- ConcurrentHashMap作为Concurrent一族,其有着高效地并发操作,相比Hashtable的笨重,ConcurrentHashMap则更胜一筹了。
- 在1.8版本以前,ConcurrentHashMap采用分段锁的概念,使锁更加细化,但是1.8已经改变了这种思路,而是利用CAS+Synchronized来保证并发更新的安全,当然底层采用数组+链表+红黑树的存储结构。
- 源码分析:推荐参考chenssy的博文:J.U.C之Java并发容器:ConcurrentHashMap
安全共享对象策略
- 线程限制:一个被线程限制的对象,由线程独占,并且只能被占有它的线程修改
- 共享只读:一个共享只读的U帝乡,在没有额外同步的情况下,可以被多个线程并发访问,但是任何线程都不能修改它
- 线程安全对象:一个线程安全的对象或者容器,在内部通过同步机制来保障线程安全,多以其他线程无需额外的同步就可以通过公共接口随意访问他
- 被守护对象:被守护对象只能通过获取特定的锁来访问。
不好意思 虎头蛇尾了.实在扛不住了
高并发第八弹:J.U.C起航(java.util.concurrent)的更多相关文章
- 高并发第十一弹:J.U.C -AQS(AbstractQueuedSynchronizer) 组件:Lock,ReentrantLock,ReentrantReadWriteLock,StampedLock
既然说到J.U.C 的AQS(AbstractQueuedSynchronizer) 不说 Lock 是不可能的.不过实话来说,一般 JKD8 以后我一般都不用Lock了.毕竟sychronize ...
- 【并发编程】【JDK源码】JDK的(J.U.C)java.util.concurrent包结构
本文从JDK源码包中截取出concurrent包的所有类,对该包整体结构进行一个概述. 在JDK1.5之前,Java中要进行并发编程时,通常需要由程序员独立完成代码实现.当然也有一些开源的框架提供了这 ...
- 高并发第十三弹:J.U.C 队列 SynchronousQueue.ArrayBlockingQueue.LinkedBlockingQueue.LinkedTransferQueue
因为下一节会说线程池,要用线程池 那么线程池有个很重要的参数 就是Queue的选择 常用的队列其实就两种: 先进先出(FIFO):先插入的队列的元素也最先出队列,类似于排队的功能.从某种程度上来说这种 ...
- java并发编程:线程安全管理类--原子包--java.util.concurrent.atomic
java.util.concurrent.atomic 的描述 AtomicBoolean 可以用原子方式更新的 boolean 值. AtomicInteger 可以用原子方式更新的 int 值. ...
- 高并发第十单:J.U.C AQS(AbstractQueuedSynchronizer) 组件:CountDownLatch. CyclicBarrier .Semaphore
这里有一篇介绍AQS的文章 非常好: Java并发之AQS详解 AQS全名:AbstractQueuedSynchronizer,是并发容器J.U.C(java.lang.concurrent)下lo ...
- 聊聊高并发(二十九)解析java.util.concurrent各个组件(十一) 再看看ReentrantReadWriteLock可重入读-写锁
上一篇聊聊高并发(二十八)解析java.util.concurrent各个组件(十) 理解ReentrantReadWriteLock可重入读-写锁 讲了可重入读写锁的基本情况和基本的方法,显示了怎样 ...
- 高并发编程基础(java.util.concurrent包常见类基础)
JDK5中添加了新的java.util.concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能.因为同步容器将所有对容器状态的访问都串行化了,这样保证了线程的安全性,所以这种方法 ...
- 聊聊高并发(二十)解析java.util.concurrent各个组件(二) 12个原子变量相关类
这篇说说java.util.concurrent.atomic包里的类,总共12个.网上有非常多文章解析这几个类.这里挑些重点说说. watermark/2/text/aHR0cDovL2Jsb2cu ...
- 聊聊高并发(二十五)解析java.util.concurrent各个组件(七) 理解Semaphore
前几篇分析了一下AQS的原理和实现.这篇拿Semaphore信号量做样例看看AQS实际是怎样使用的. Semaphore表示了一种能够同一时候有多个线程进入临界区的同步器,它维护了一个状态表示可用的票 ...
随机推荐
- python 设置默认的导包路径
在python中 可以通过 sys 模块添加导包时的搜寻路径, sys.path 返回的是所有默认导包路径的列表(搜索次序从下标为零开始,直到寻找到需要导入的包结束) sys.path.insert( ...
- clang 编译 OC
clang -fobjc-arc -framework Foundation helloworld.m -o helloworld.out OVERVIEW: clang LLVM compiler ...
- Aizu 2249Road Construction 单源最短路变形《挑战程序设计竞赛》模板题
King Mercer is the king of ACM kingdom. There are one capital and some cities in his kingdom. Amazin ...
- webpack快速入门——打包后如何调试
在配置devtool时,webpack给我们提供了四种选项. source-map:在一个单独文件中产生一个完整且功能完全的文件.这个文件具有最好的source map,但是它会减慢打包速度: che ...
- OAuth 2.0 - Authorization Code授权方式详解
I:OAuth 2.0 开发前期准备 天上不会自然掉馅饼让你轻松地去访问到人家资源服务器里面的用户数据资源,所以你需要做的前期开发准备工作就是把AppKey, AppSecret取到手 新浪获取传送门 ...
- h5预订酒店项目|html5酒店模板|h5酒店webapp开发
近几天尝试着使用html5+css3+swiper+jqUI+layerMobile等技术开发了一款仿携程.去哪儿.艺龙webapp酒店预订系统,页面图标统一使用iconfont,仿原生app右侧弹窗 ...
- 做了三年的菜鸟web前端的感悟
作为一名真正的菜鸟我想没有比我更加实在的了,三年之中,虽然做了一二三四五六七个项目,基本都是jQuery写的,但是还是一名不折不扣的菜鸟.这让我很尴尬啊,面对前端大量要学习的东西,真的是很头疼,技术更 ...
- org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
这时windows远程调试hadoop集群出现的这里 做个记录 我用改变系统变量的方法 修正了错误 网上搜索出来大概有三种: 1.在系统的环境变量或java JVM变量里面添加HADOOP_USE ...
- 使用EntityFrameworkCore 连接 MySql
上篇文章介绍了如何在dotnetcore下使用Dapper连接MySql,这里再介绍使用使用EntityFrameworkCore 连接 MySql. 新建控制台项目,安装下面两个nuget包: In ...
- Android_Universal-Image-Load使用
一,快速使用(确保ImageLoader只初始化一次,这样图片缓存会更加优秀.) 场景:为ImageView设置一张指定Uri的图片. 1,导包,配置联网,读写SD卡权限. 2,初始化: ImageL ...