time_wait和clost_wait说明
在服务器的日常维护过程中,会经常用到下面的命令:
- netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
它会显示例如下面的信息:
TIME_WAIT 814
CLOSE_WAIT 1
FIN_WAIT1 1
ESTABLISHED 634
SYN_RECV 2
LAST_ACK 1
常用的三个状态是:ESTABLISHED 表示正在通信,TIME_WAIT 表示主动关闭,CLOSE_WAIT 表示被动关闭。
具体每种状态什么意思,其实无需多说,看看下面这种图就明白了,注意这里提到的服务器应该是业务请求接受处理的一方:
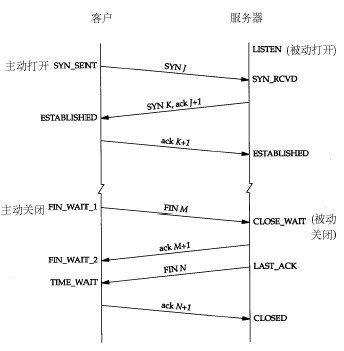
这么多状态不用都记住,只要了解到我上面提到的最常见的三种状态的意义就可以了。一般不到万不得已的情况也不会去查看网络状态,如果服务器出了异常,百分之八九十都是下面两种情况:
1.服务器保持了大量TIME_WAIT状态
2.服务器保持了大量CLOSE_WAIT状态
因为linux分配给一个用户的文件句柄是有限的(可以参考:http://blog.csdn.net/shootyou/article/details/6579139),而TIME_WAIT和CLOSE_WAIT两种状态如果一直被保持,那么意味着对应数目的通道就一直被占着,而且是“占着茅坑不使劲”,一旦达到句柄数上限,新的请求就无法被处理了,接着就是大量Too Many Open Files异常,tomcat崩溃。。。
下 面来讨论下这两种情况的处理方法,网上有很多资料把这两种情况的处理方法混为一谈,以为优化系统内核参数就可以解决问题,其实是不恰当的,优化系统内核参 数解决TIME_WAIT可能很容易,但是应对CLOSE_WAIT的情况还是需要从程序本身出发。现在来分别说说这两种情况的处理方法:
1.服务器保持了大量TIME_WAIT状态
这种情况比较常见,一些爬虫服务器或者WEB服务器(如果网管在安装的时候没有做内核参数优化的话)上经常会遇到这个问题,这个问题是怎么产生的呢?
从 上面的示意图可以看得出来,TIME_WAIT是主动关闭连接的一方保持的状态,对于爬虫服务器来说他本身就是“客户端”,在完成一个爬取任务之后,他就 会发起主动关闭连接,从而进入TIME_WAIT的状态,然后在保持这个状态2MSL(max segment lifetime)时间之后,彻底关闭回收资源。为什么要这么做?明明就已经主动关闭连接了为啥还要保持资源一段时间呢?这个是TCP/IP的设计者规定 的,主要出于以下两个方面的考虑:
1.防止上一次连接中的包,迷路后重新出现,影响新连接(经过2MSL,上一次连接中所有的重复包都会消失)
2. 可靠的关闭TCP连接。在主动关闭方发送的最后一个 ack(fin) ,有可能丢失,这时被动方会重新发fin, 如果这时主动方处于 CLOSED 状态 ,就会响应 rst 而不是 ack。所以主动方要处于 TIME_WAIT 状态,而不能是 CLOSED 。另外这么设计TIME_WAIT 会定时的回收资源,并不会占用很大资源的,除非短时间内接受大量请求或者受到攻击。
关于MSL引用下面一段话:
- MSL 為 一個 TCP Segment (某一塊 TCP 網路封包) 從來源送到目的之間可續存的時間 (也就是一個網路封包在網路上傳輸時能存活的時間),由 於 RFC 793 TCP 傳輸協定是在 1981 年定義的,當時的網路速度不像現在的網際網路那樣發達,你可以想像你從瀏覽器輸入網址等到第一 個 byte 出現要等 4 分鐘嗎?在現在的網路環境下幾乎不可能有這種事情發生,因此我們大可將 TIME_WAIT 狀態的續存時間大幅調低,好 讓 連線埠 (Ports) 能更快空出來給其他連線使用。
再引用网络资源的一段话:
- 值 得一说的是,对于基于TCP的HTTP协议,关闭TCP连接的是Server端,这样,Server端会进入TIME_WAIT状态,可 想而知,对于访 问量大的Web Server,会存在大量的TIME_WAIT状态,假如server一秒钟接收1000个请求,那么就会积压 240*1000=240,000个 TIME_WAIT的记录,维护这些状态给Server带来负担。当然现代操作系统都会用快速的查找算法来管理这些 TIME_WAIT,所以对于新的 TCP连接请求,判断是否hit中一个TIME_WAIT不会太费时间,但是有这么多状态要维护总是不好。
- HTTP协议1.1版规定default行为是Keep-Alive,也就是会重用TCP连接传输多个 request/response,一个主要原因就是发现了这个问题。
也就是说HTTP的交互跟上面画的那个图是不一样的,关闭连接的不是客户端,而是服务器,所以web服务器也是会出现大量的TIME_WAIT的情况的。
- #对于一个新建连接,内核要发送多少个 SYN 连接请求才决定放弃,不应该大于255,默认值是5,对应于180秒左右时间
- net.ipv4.tcp_syn_retries=2
- #net.ipv4.tcp_synack_retries=2
- #表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为300秒
- net.ipv4.tcp_keepalive_time=1200
- net.ipv4.tcp_orphan_retries=3
- #表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间
- net.ipv4.tcp_fin_timeout=30
- #表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
- net.ipv4.tcp_max_syn_backlog = 4096
- #表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭
- net.ipv4.tcp_syncookies = 1
- #表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭
- net.ipv4.tcp_tw_reuse = 1
- #表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
- net.ipv4.tcp_tw_recycle = 1
- ##减少超时前的探测次数
- net.ipv4.tcp_keepalive_probes=5
- ##优化网络设备接收队列
- net.core.netdev_max_backlog=3000
net.ipv4.tcp_fin_timeout
net.ipv4.tcp_keepalive_*
是CLOSE_WAIT就不一样了,从上面的图可以看出来,如果一直保持在CLOSE_WAIT状态,那么只有一种情况,就是在对方关闭连接之后服务器程
序自己没有进一步发出ack信号。换句话说,就是在对方连接关闭之后,程序里没有检测到,或者程序压根就忘记了这个时候需要关闭连接,于是这个资源就一直
被程序占着。个人觉得这种情况,通过服务器内核参数也没办法解决,服务器对于程序抢占的资源没有主动回收的权利,除非终止程序运行。
time_wait和clost_wait说明的更多相关文章
- [Nginx笔记]关于线上环境CLOSE_WAIT和TIME_WAIT过高
运维的同学和Team里面的一个同学分别遇到过Nginx在线上环境使用中会遇到TIME_WAIT过高或者CLOSE_WAIT过高的状态 先从原因分析一下为什么,问题就迎刃而解了. 首先是TIME_WAI ...
- oracle 和c3p0 数据库的Time_Wait 过多问题的一个解决方案。
项目是B/S模式,放在linux服务器上,tomcat和oracle11g在一台服务器上,tomcat读取数据库采用C3P0连接池,一直比较稳定,所以也没有去管.后来把tomcat放在一台win200 ...
- netstat监控大量ESTABLISHED连接与Time_Wait连接问题
问题描述: 在不考虑系统负载.CPU.内存等情况下,netstat监控大量ESTABLISHED连接与Time_Wait连接. # netstat -n | awk '/^tcp/ {++y[$NF] ...
- 【转】 linux 下Time_wait过多问题解决
问题起因: 自己开发了一个服务器和客户端,通过短连接的方式来进行通讯,由于过于频繁的创建连接,导致系统连接数量被占用,不能及时释放.看了一下18888,当时吓到了. 现象: 1.外部机器不能正常连接S ...
- 临时解决系统中大量的TIME_WAIT连接
今天,偶然间发现后台服务与数据库之间有大量的TIME_WAIT的连接: [root@localhost logs]# netstat -an | grep TIME_WAIT tcp a.a.a.a: ...
- 发现大量的TIME_WAIT解决办法
存在一定的TIME_WAIT是正常的,个人认为如果超过了连接数的比例就不是很正常 服务器端与客户端建立TCP/IP连接后关闭SOCKET后,服务器端连接的端口状态变为TIME_WAIT.主动关闭的一方 ...
- 传输层(2)-TCP连接的建立和终止、TIME_WAIT状态
1.TCP连接的建立和终止 1)三路握手 客户端发送一个SYN(同步)分解,告诉服务器客户将在连接中发送的数据的初始序列号. 服务器发送确认客户的SYN(ACK),同时自己也得发送一个SYN分节,它含 ...
- 服务器TIME_WAIT和CLOSE_WAIT详解和解决办法
转载的服务器TIME_WAIT和CLOSE_WAIT详解和解决办法
- Nginx做前端Proxy时TIME_WAIT过多的问题
我们的DSP系统目前基本非凌晨时段的QPS都在10W以上,我们使用Golang来处理这些HTTP请求,Web服务器的前端用Nginx来做负载均衡,通过Nginx的proxy_pass来与Golang交 ...
随机推荐
- 1.Perl 多线程:Threads
详情可查看: perldoc threads 调用线程的方法: $thr = threads->create(FUNCTION, ARGS) #This will create a new th ...
- websphere安装验证报错 忘记密码的配置
http://blog.csdn.net/yulimin/article/details/4048897 ADMU7704E: 在尝试启动与服务器相关联的 Windows 服务时失败:server1: ...
- 在自学php的路上不知道怎么走!!
在自学php的路上不知道怎么走!! 真希望有人给我指点一二!!!
- 有关android安全性的问题--代码混淆
转自:http://www.cnblogs.com/dream-sky/archive/2012/11/15/2771648.html 在project.properties里加上 proguar ...
- VNC VIEWER的使用集锦
关于颜色深度的问题, 今天用VNC Viewser ,连上去之后,发现色彩可能只有8或者16位 然后修改了 sever的depth,也不好使, 于是,就修改了 client的 colourlevel ...
- 使用monit搭建一个监控系统
上周用monit搭建或者说定制了一个监控系统,来监控服务器发生事情.当然了主要是监控异常,因为我们的产品属于服务器类型,很多进程都daemon,要不停的运行.我们搭建监控目的不过是出现问题能够及时的知 ...
- js键盘键值大全
原文地址:http://blog.csdn.net/avenccssddnn/article/details/7950524 js键盘键值 keycode 8 = BackSpace BackSpac ...
- 详细理解servlet实现的几种方式和生命周期
现在很多的开发都是用的框架,然后很多同学学习的时候又是直接接触的框架,对于底层的一些开发,完全没有任何的了解.虽然对于业务上面来说,没有什么问题.但是很多时候当你被面试问到,或者是想要了解框架底层原理 ...
- CSS3秘笈:第八章
给网页添加图片 1. 常用来处理图片的CSS属性: (1) border(边框):给图片添加边框. (2) padding(填充):边框和图片之间填充空间. (3) float ...
- PHP fpm优化【转】
在优化PHP的进程数的时候我们首先要了解我们服务器执行一个php使用的内存 1: 查询一个php占用的内存方法 pmap $(pgrep php-fpm | head -1) 我这里查询到的是 000 ...