机器学习-决策树算法+代码实现(基于R语言)
分类树(决策树)是一种十分常用的分类方法。核心任务是把数据分类到可能的对应类别。
他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。
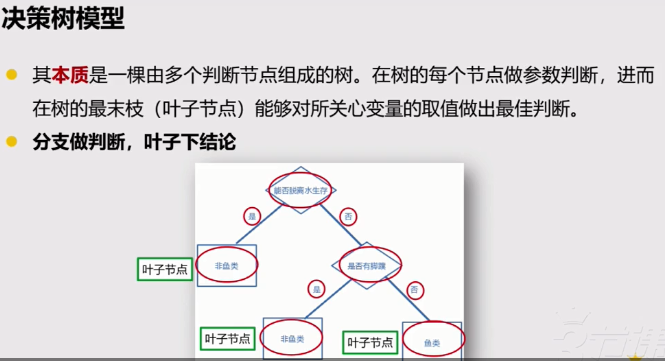

决策树的理解
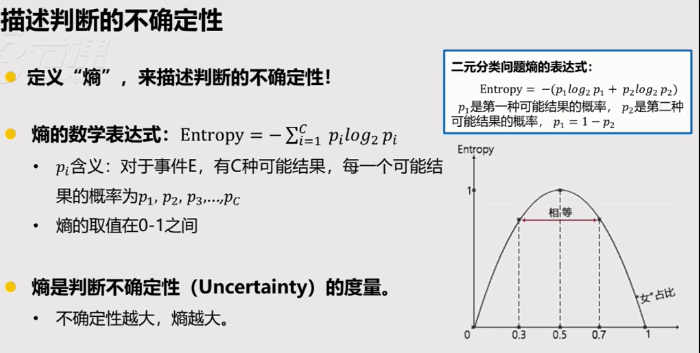
熵的概念对理解决策树很重要
决策树做判断不是百分之百正确,它只是基于不确定性做最优判断。
熵就是用来描述不确定性的。
案例:找出共享单车用户中的推荐者
解析:求出哪一类人群更可能成为共享单车的推荐者。换句话说是推荐者与其他变量之间不寻常的关系。
步骤1
测量节点对应的人群的熵
对于是否推荐这样两分的结果,推荐者比例趋近于0或者1时,熵都为0,推荐者比例趋近于50%时,熵趋近1。
分析师需要根据用户特征,区分出推荐者。通过决策树可以尽可能降低节点人群熵的值(通过决策树不断的分叉)。
步骤2
节点的分叉
不同的分叉方式会得到不同的增益值,计算机会选择最大的增益值,即最优的分叉方式。
详情见后文信息增益相关内容。
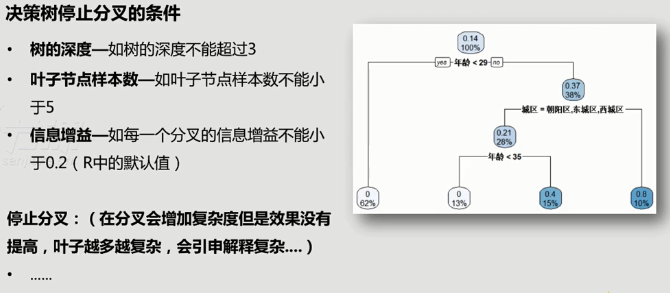
步骤3
在特定情况下停止分叉。
注意:分支节点太多会把情况搞复杂,反而不利于决策,需要在适当时候停止分叉。
信息增益(IG)的概念
表示经过决策树一次决策后,整个分类数据信息熵下降的大小。

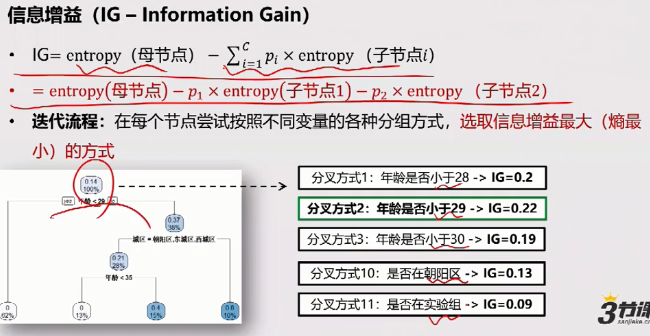
上面求得的IG是母节点的熵减去子节点熵的加权和,得到的结果,是经过一次分叉后所降低的熵的值。
不同的分叉方式会得到不同的增益值,计算机会选择最大的增益值,即最优的分叉方式。
R语言实现
> bike.data <- read.csv(Shared Bike Sample Data - ML.csv)
> library(rpart)
> library(rpart.plot)
> library(rpart.plot)
> bike.data$推荐者 <- bike.data$分数>=9
> rtree_fit <- rpart(推荐者 ~城区+年龄+组别,data=bike.data)
> rpart.plot(rtree_fit)

决策树小结
本质是一种映射关系,将对象的一组属性和对象的值映射到一起,决策树可以和概率完美结合。
优点是:适合处理多类变量,对异常值不敏感,准确度高。
缺点是:
作为一种典型的监督学习算法,在训练时需要大规模数据和计算空间。为了得到最好的决策变量排列顺序,决策树需要反复计算变量的熵信息增益,很耗时间。
决策树是一种贪心算法,每一次决策都谋求最优,追求局部最优的结果是决策树达不到全局最优(与遗传算法比,这是难以回避的缺点)。
决策树剪枝叶技术帮助决策树使用最少的节点完成分类任务,但错误剪枝会使得决策树结果准确性大幅降低,同时剪枝过程也需要大量计算。
决策树不擅长处理连续型变量。当树中连续变量过多时候,决策树犯错误的可能就会增大
机器学习-决策树算法+代码实现(基于R语言)的更多相关文章
- 基于R语言的时间序列指数模型
时间序列: (或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列.时间序列分析的主要目的是根据已有的历史数据对未来进行预测.(百度百科) 主要考虑的因素: 1.长期趋势(Lon ...
- 概率图模型 基于R语言 这本书中的第一个R语言程序
概率图模型 基于R语言 这本书中的第一个R语言程序 prior <- c(working =0.99,broken =0.01) likelihood <- rbind(working = ...
- 基于R语言的ARIMA模型
A IMA模型是一种著名的时间序列预测方法,主要是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型.ARIMA模型根据原序列是否平稳以及 ...
- Twitter基于R语言的时序数据突变检测(BreakoutDetection)
Twitter开源的时序数据突变检测(BreakoutDetection),基于无参的E-Divisive with Medians (EDM)算法,比传统的E-Divisive算法快3.5倍以上,并 ...
- 机器学习-线性回归(基于R语言)
基本概念 利用线性的方法,模拟因变量与一个或多个自变量之间的关系.自变量是模型输入值,因变量是模型基于自变量的输出值. 因变量是自变量线性叠加和的结果. 线性回归模型背后的逻辑——最小二乘法计算线性系 ...
- 机器学习-K-means聚类及算法实现(基于R语言)
K-means聚类 将n个观测点,按一定标准(数据点的相似度),划归到k个聚类(用户划分.产品类别划分等)中. 重要概念:质心 K-means聚类要求的变量是数值变量,方便计算距离. 算法实现 R语言 ...
- 基于R语言的结构方程:lavaan简明教程 [中文翻译版]
lavaan简明教程 [中文翻译版] 译者注:此文档原作者为比利时Ghent大学的Yves Rosseel博士,lavaan亦为其开发,完全开源.免费.我在学习的时候顺手翻译了一下,向Yves的开源精 ...
- 【转】基于R语言构建的电影评分预测模型
一,前提准备 1.R语言包:ggplot2包(绘图),recommenderlab包,reshape包(数据处理) 2.获取数据:大家可以在明尼苏达州大学的社会化计算研 ...
- 中文分词实践(基于R语言)
背景:分析用户在世界杯期间讨论最多的话题. 思路:把用户关于世界杯的帖子拉下来.然后做中文分词+词频统计,最后将统计结果简单做个标签云.效果例如以下: 兴许:中文分词是中文信息处理的基础.分词之后.事 ...
随机推荐
- 【leetcode】1028. Recover a Tree From Preorder Traversal
题目如下: We run a preorder depth first search on the root of a binary tree. At each node in this traver ...
- NoSQL数据库的分布式算法详解
系统的可扩展性是推动NoSQL运动发展的的主要理由,包含了分布式系统协调,故障转移,资源管理和许多其他特性.这么讲使得NoSQL听起来像是一个大筐,什么都能塞进去.尽管NoSQL运动并没有给分布式数据 ...
- p5341 [TJOI2019]甲苯先生和大中锋的字符串
分析 TJOI白给题 建出sam,对于每个点如果它的子树siz和等于k 那么对于这个满足的点它有贡献的长度一定是一个连续区间 直接差分即可 代码 #include<bits/stdc++.h&g ...
- p4111 [HEOI2015]小Z的房间[简述矩阵树定理]
分析 [1]无向图 图G的度数矩阵为D,邻接矩阵为A 我们定义这个图的Kirchhoff矩阵为D-A 这个矩阵的任意一个n-1阶主子式的行列式的绝对值就是这个图的生成树个数 [2]有向图 如果要求内向 ...
- Selenium WebDriver 常用API
public class Demo1 { WebDriver driver; @BeforeMethod public void visit(){ //webdriver对象的声明 System.se ...
- Altium Designer chapter5总结
PCB设计环境中需要注意的如下: (1)PCB设计步骤:绘制原理图和生成网表—规划电路板—载入网表—元件布局—制定设计规则—布线—后期处理—DRC检查—信号完整性分析—gerbera文件输出 (2)P ...
- Oracle基本操作练习(一)
--创建表空间 create tablespace test datafile 'c:\test.dbf' size 100m autoextend on next 10m; --删除表空间 drop ...
- VScode 常用快捷键 2019
窗口操作 Ctrl + b : 显示/隐藏左侧工作区文件目录 View Appearance show Activity bar : 最左侧工具栏 显示/隐藏 Preferences ...
- [Linux] 002 预备知识
1. 开源软件 (1) 常见开源软件 Apache NGINXTM MySQL PHP Saamba mongoDB Python Ruby Sphinx -- (2) 开源软件的特点 绝大多数开源软 ...
- mysql解析json字符串相关问题
很多时候,我们需要在sql里面直接解析json字符串.这里针对mysql5.7版本的分水岭进行区分. 1.对于mysql5.7以上版本 使用mysql的内置函数JSON_EXTRACT(column, ...