机器学习-决策树算法+代码实现(基于R语言)
分类树(决策树)是一种十分常用的分类方法。核心任务是把数据分类到可能的对应类别。
他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。
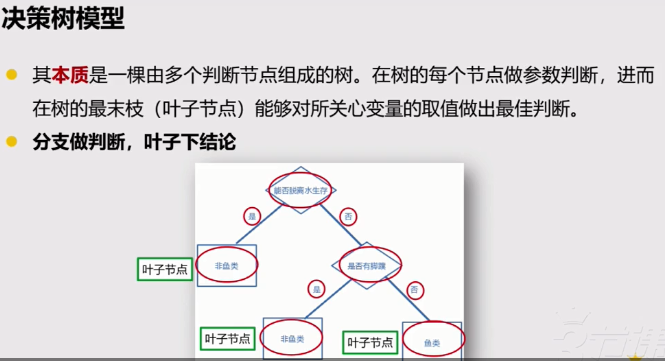

决策树的理解
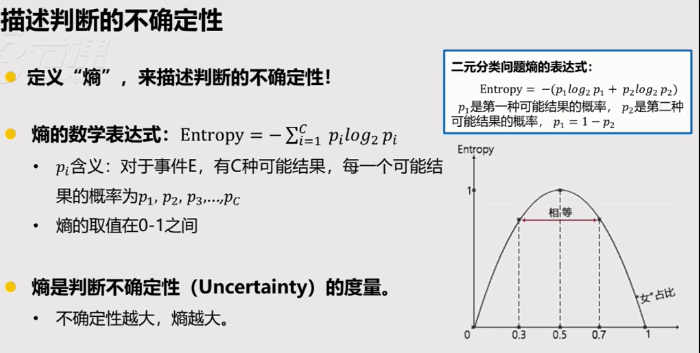
熵的概念对理解决策树很重要
决策树做判断不是百分之百正确,它只是基于不确定性做最优判断。
熵就是用来描述不确定性的。
案例:找出共享单车用户中的推荐者
解析:求出哪一类人群更可能成为共享单车的推荐者。换句话说是推荐者与其他变量之间不寻常的关系。
步骤1
测量节点对应的人群的熵
对于是否推荐这样两分的结果,推荐者比例趋近于0或者1时,熵都为0,推荐者比例趋近于50%时,熵趋近1。
分析师需要根据用户特征,区分出推荐者。通过决策树可以尽可能降低节点人群熵的值(通过决策树不断的分叉)。
步骤2
节点的分叉
不同的分叉方式会得到不同的增益值,计算机会选择最大的增益值,即最优的分叉方式。
详情见后文信息增益相关内容。
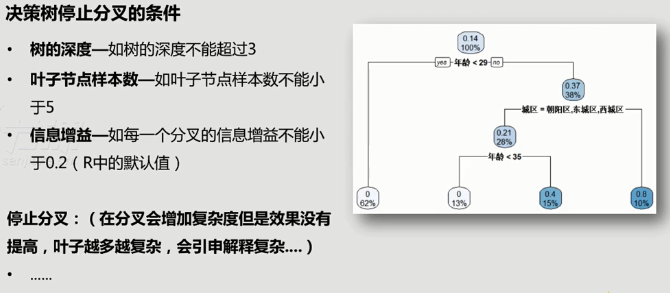
步骤3
在特定情况下停止分叉。
注意:分支节点太多会把情况搞复杂,反而不利于决策,需要在适当时候停止分叉。
信息增益(IG)的概念
表示经过决策树一次决策后,整个分类数据信息熵下降的大小。

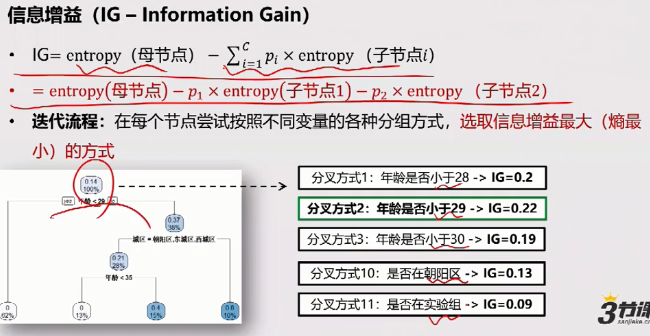
上面求得的IG是母节点的熵减去子节点熵的加权和,得到的结果,是经过一次分叉后所降低的熵的值。
不同的分叉方式会得到不同的增益值,计算机会选择最大的增益值,即最优的分叉方式。
R语言实现
> bike.data <- read.csv(Shared Bike Sample Data - ML.csv)
> library(rpart)
> library(rpart.plot)
> library(rpart.plot)
> bike.data$推荐者 <- bike.data$分数>=9
> rtree_fit <- rpart(推荐者 ~城区+年龄+组别,data=bike.data)
> rpart.plot(rtree_fit)

决策树小结
本质是一种映射关系,将对象的一组属性和对象的值映射到一起,决策树可以和概率完美结合。
优点是:适合处理多类变量,对异常值不敏感,准确度高。
缺点是:
作为一种典型的监督学习算法,在训练时需要大规模数据和计算空间。为了得到最好的决策变量排列顺序,决策树需要反复计算变量的熵信息增益,很耗时间。
决策树是一种贪心算法,每一次决策都谋求最优,追求局部最优的结果是决策树达不到全局最优(与遗传算法比,这是难以回避的缺点)。
决策树剪枝叶技术帮助决策树使用最少的节点完成分类任务,但错误剪枝会使得决策树结果准确性大幅降低,同时剪枝过程也需要大量计算。
决策树不擅长处理连续型变量。当树中连续变量过多时候,决策树犯错误的可能就会增大
机器学习-决策树算法+代码实现(基于R语言)的更多相关文章
- 基于R语言的时间序列指数模型
时间序列: (或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列.时间序列分析的主要目的是根据已有的历史数据对未来进行预测.(百度百科) 主要考虑的因素: 1.长期趋势(Lon ...
- 概率图模型 基于R语言 这本书中的第一个R语言程序
概率图模型 基于R语言 这本书中的第一个R语言程序 prior <- c(working =0.99,broken =0.01) likelihood <- rbind(working = ...
- 基于R语言的ARIMA模型
A IMA模型是一种著名的时间序列预测方法,主要是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型.ARIMA模型根据原序列是否平稳以及 ...
- Twitter基于R语言的时序数据突变检测(BreakoutDetection)
Twitter开源的时序数据突变检测(BreakoutDetection),基于无参的E-Divisive with Medians (EDM)算法,比传统的E-Divisive算法快3.5倍以上,并 ...
- 机器学习-线性回归(基于R语言)
基本概念 利用线性的方法,模拟因变量与一个或多个自变量之间的关系.自变量是模型输入值,因变量是模型基于自变量的输出值. 因变量是自变量线性叠加和的结果. 线性回归模型背后的逻辑——最小二乘法计算线性系 ...
- 机器学习-K-means聚类及算法实现(基于R语言)
K-means聚类 将n个观测点,按一定标准(数据点的相似度),划归到k个聚类(用户划分.产品类别划分等)中. 重要概念:质心 K-means聚类要求的变量是数值变量,方便计算距离. 算法实现 R语言 ...
- 基于R语言的结构方程:lavaan简明教程 [中文翻译版]
lavaan简明教程 [中文翻译版] 译者注:此文档原作者为比利时Ghent大学的Yves Rosseel博士,lavaan亦为其开发,完全开源.免费.我在学习的时候顺手翻译了一下,向Yves的开源精 ...
- 【转】基于R语言构建的电影评分预测模型
一,前提准备 1.R语言包:ggplot2包(绘图),recommenderlab包,reshape包(数据处理) 2.获取数据:大家可以在明尼苏达州大学的社会化计算研 ...
- 中文分词实践(基于R语言)
背景:分析用户在世界杯期间讨论最多的话题. 思路:把用户关于世界杯的帖子拉下来.然后做中文分词+词频统计,最后将统计结果简单做个标签云.效果例如以下: 兴许:中文分词是中文信息处理的基础.分词之后.事 ...
随机推荐
- ATM机取款过程
假设一个简单的ATM机的取款过程是这样的:首先提示用户输入密码,最多只能输入三次,超过3次则提示用户“密码错误,请取卡”结束交易.如果用户密码正确,再提示用户输入取款金额,ATM机只能输出100元的纸 ...
- MYSQL数据库类型与JAVA类型对应表
MYSQL数据库类型与JAVA类型对应表 MYSQL数据库类型与JAVA类型对应表 类型名称 显示长度 数据库类型 JAVA类型 JDBC类型 索引(int) VARCHAR L+N VARCHA ...
- RestTemplate 发送post请求
springboot使用restTemplate post提交值 restTemplate post值 post提交有 FormData和Payload 两种形式: 第一种是formdata形式,在h ...
- LA 6834 Shopping
题目链接:https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show_ ...
- Task6.神经网络基础
BP: 正向计算loss,反向传播梯度. 计算梯度时,从输出端开始,前一层的梯度等于activation' *(与之相连的后一层的神经元梯度乘上权重的和). import torch from tor ...
- Oracle12c修改时区
Oacle12c支持可插入数据库(PDB)在一个统一的数据库(CDB)中具有不同的字符集.时区文件版本和数据库时区. 出于性能原因,Oracle建议将数据库时区设置为UTC(0:00),因为不需要转换 ...
- common pom
<dependencies> <dependency> <groupId>com.github.pagehelper</groupId> <art ...
- .Net Core 学习目录(搁置)
简介 .NET Core 是.NET Framework的新一代版本,是微软开发的第一个官方版本,具有跨平台 (Windows.Mac OSX.Linux) 能力的应用程序开发框架 (Applicat ...
- 使用sys.dm_exec_cached_plans监控存储过程性能
讨论了如何使用sys.dm_exec_query_stats动态管理视图(dmv ).本文将以SQL Server 2005为例,讨论如何利用dmv信息来判断tsql的性能优劣.在这篇文章中将继续我有 ...
- HTML基础入门学习准备篇
在学习前端的开始,让我们一起来了解什么是HTML5时代的大前端开发和全栈开发的定义 传统的前端:切图-标签和样式-实现效果 H5时代的前端: 一.需要各端的兼容开发 二.可以用于APP开发和移动站点的 ...