Linux性能优化从入门到实战:15 文件系统篇:磁盘 I/O
磁盘
磁盘是可以持久化存储的设备,按照存储介质来分类:
(1)机械磁盘(硬盘驱动器,Hard Disk Driver,HDD),主要由盘片和读写磁头组成,数据就存储在盘片的环状磁道中。在读写数据前,需要移动读写磁头,定位到数据所在的磁道,然后才能访问数据。如果 I/O 请求刚好连续,那就不需要磁道寻址,自然可以获得最佳性能,这就是连续 I/O 的工作原理。与之相对应的,当然就是随机 I/O,它需要不停地移动磁头,来定位数据位置,所以读写速度就会比较慢。机械磁盘的最小读写单位是 512 字节的扇区,但对逻辑块的管理是 4KB。
(2)固态磁盘(Solid State Disk,SSD),由固态电子元器件组成。固态磁盘不需要磁道寻址,所以,不管是连续 I/O,还是随机 I/O 的性能,都比机械磁盘要好得多。但固态磁盘也存在“先擦除再写入”的限制,随机读写会导致大量的垃圾回收,所以相对应的,随机 I/O 的性能比起连续 I/O 来,也还是差了很多。固态磁盘的最小读写单位是 4KB、8KB等的页。
综上,无论机械磁盘,还是固态磁盘,相同磁盘的随机 I/O 都要比连续 I/O 慢很多。并且连续 I/O 还可以通过预读的方式,来减少 I/O 请求的次数,这也是其性能优异的一个原因。
按照接口来分类,可以把硬盘分为 IDE(Integrated Drive Electronics)、SCSI(Small Computer System Interface) 、SAS(Serial Attached SCSI) 、SATA(Serial ATA) 、FC(Fibre Channel) 等。不同的接口,往往分配不同的设备名称。比如, IDE 设备会分配一个 hd 前缀的设备名,SCSI 和 SATA 设备会分配一个 sd 前缀的设备名。如果是多块同类型的磁盘,就会按照 a、b、c 等的字母顺序来编号。
按照使用方式来分类,又可以把它们划分为多种不同的架构:
(1)作为独立磁盘设备来使用,往往还需要进行逻辑分区,每个分区再用数字编号: /dev/sda 设备分为 /dev/sda1 和 /dev/sda2。
(2)把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列,RAID(Redundant Array of Independent Disks),从而可以提高数据访问的性能,并且增强数据存储的可靠性。根据容量、性能和可靠性需求的不同,RAID 一般可以划分为多个级别,如 RAID0、RAID1、RAID5、RAID10 等。RAID0 有最优的读写性能,但不提供数据冗余的功能。而其他级别的 RAID,在提供数据冗余的基础上,对读写性能也有一定程度的优化。
(3)将磁盘组合成一个网络存储集群,NFS、SMB、iSCSI。
磁盘是作为一个块设备来管理的,也就是以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主、次设备号。主设备号用在驱动程序中,用来区分设备类型;而次设备号则是用来给多个同类设备编号。
通用块层
为了减小不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理各种不同的块设备,是处在文件系统和磁盘驱动中间的一个块设备抽象层,有两功能:
(1)跟虚拟文件系统的功能类似。向上,为文件系统和应用程序,提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
(2)通用块层还会给文件系统和应用程序发来的 I/O 请求排队( I/O 调度),并通过重新排序、请求合并等方式,提高磁盘读写的效率。
四种 I/O 调度算法:
(1)NONE ,完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 其实不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。
(2)NOOP ,是最简单的一种 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。
(3)CFQ(Completely Fair Scheduler),也被称为完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。
(4)DeadLine 调度算法,分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。DeadLine 调度算法,多用在 I/O 压力比较重的场景,比如数据库等。
I/O 栈
由上到下分为三个层次,分别是文件系统层、通用块层和设备层。
(1)文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
(2)通用块层,包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
(3)设备层,包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作。
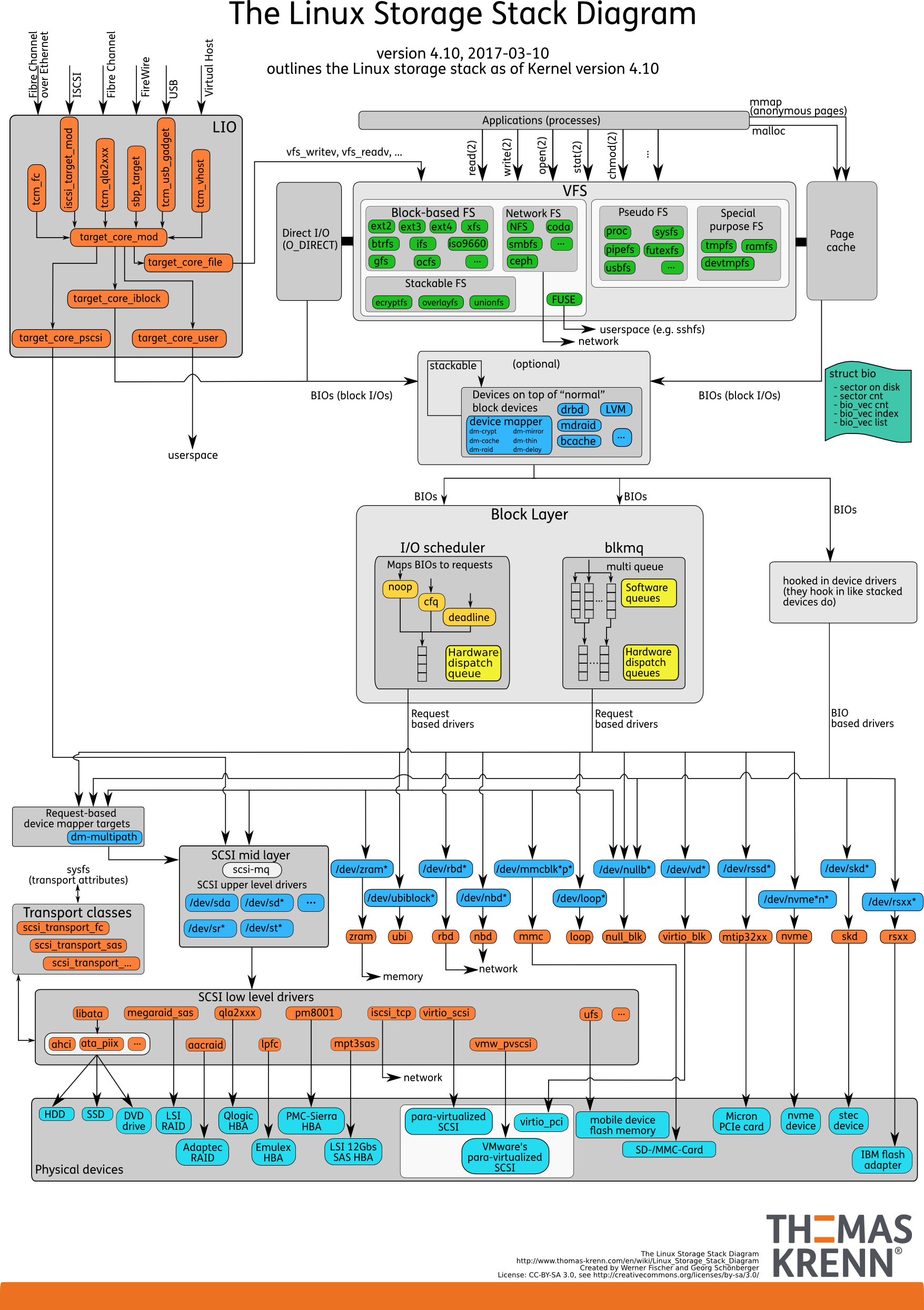
存储系统的 I/O ,通常是整个系统中最慢的一环。所以, Linux 通过多种缓存机制来优化 I/O 效率:
(1)使用页缓存、索引节点缓存、目录项缓存等多种缓存机制优化文件访问的性能;
(2)使用缓冲区,来缓存块设备的数据的访问效率。
磁盘性能指标
- 使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。使用率只考虑有没有 I/O,而不考虑 I/O 的大小,即当使用率是 100% 的时候,磁盘依然有可能接受新的 I/O 请求。
- 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
不要孤立地去比较某一指标,而要结合读写比例、I/O 类型(随机还是连续)以及 I/O 的大小,综合来分析。比如:在数据库、大量小文件等这类随机读写比较多的场景中,IOPS 更能反映系统的整体性能;而在多媒体等顺序读写较多的场景中,吞吐量才更能反映系统的整体性能。
磁盘 I/O 性能基准测试:fio(https://linux.die.net/man/1/fio),测试出不同 I/O 大小(一般是 512B 至 1MB 中间的若干值)分别在随机读、顺序读、随机写、顺序写等各种场景下的性能情况。通过用性能工具得到的这些指标,可以作为后续分析应用程序性能的依据。
(1)iostat 分析系统整体 io 情况
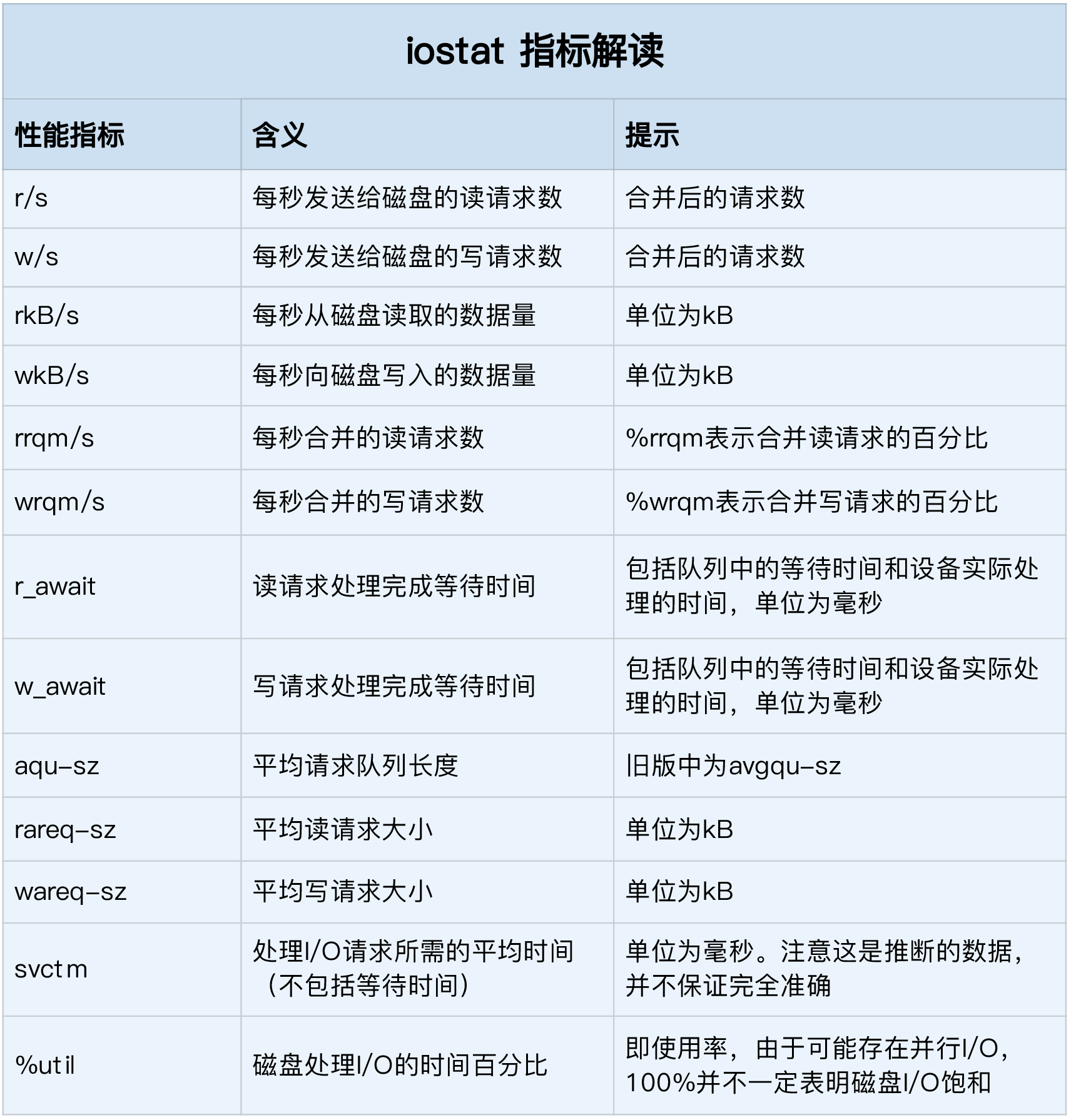
iostat 是磁盘 I/O 性能观测工具,指标来自 /proc/diskstats。
- %util ,就是我们前面提到的磁盘 I/O 使用率;
- r/s+ w/s ,就是 IOPS;
- rkB/s+wkB/s ,就是吞吐量;
- r_await+w_await ,就是响应时间。
- 结合请求的大小( rareq-sz 和 wareq-sz)一起分析
$ iostat -d -x 1 -d -x 表示显示所有磁盘 I/O 的指标
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
(2)pidstat、iotop 定位具体的进程 io 情况
pidstat 实时查看具体进程的磁盘 I/O 情况:
$ pidstat -d 1
13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
13:39:52 102 916 0.00 4.00 0.00 0 rsyslogd
- 用户 ID(UID)和进程 ID(PID) 。
- 每秒读取的数据大小(kB_rd/s) ,单位是 KB。
- 每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
- 每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
- 块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
iotop 按照 I/O 大小对进程排序:
因为缓存、缓冲区、I/O 合并等因素的影响,它们可能并不相等,进程的磁盘读写大小总数和磁盘真实的读写大小总数并不相等。
$ iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald
线程 ID、I/O 优先级、每秒读磁盘的大小、每秒写磁盘的大小、换入和等待 I/O 的时钟百分比。
(3)strace 、lsof 定位具体进程的系统调用 和 打开的文件
strace 查看指定进程的系统调用情况,查看 write 函数的情况:
-f 可以追踪多线程和多进程:写文件是由子线程执行的,所以直接strace跟踪进程没有看到write系统调用,可以通过pstree查看进程的线程信息,再用strace跟踪。或者,通过strace -fp pid 跟踪所有线程。
-e fdatasync 追踪具体的 fdatasync 函数
$ strace -f -T -tt -p 9085 # -f 表示跟踪子进程和子线程,-T 表示显示系统调用的时长,-tt 表示显示跟踪时间
[pid 9085] 14:20:16.826131 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000055>
[pid 9085] 14:20:16.826301 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:5b2e76cc-"..., 16384) = 61 <0.000071>
[pid 9085] 14:20:16.826477 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000063>
[pid 9085] 14:20:16.826645 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000173>
[pid 9085] 14:20:16.826907 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000032>
[pid 9085] 14:20:16.827030 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:55862ada-"..., 16384) = 61 <0.000044>
[pid 9085] 14:20:16.827149 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000043>
[pid 9085] 14:20:16.827285 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000141>
[pid 9085] 14:20:16.827514 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 64, NULL, 8) = 1 <0.000049>
[pid 9085] 14:20:16.827641 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-"..., 16384) = 61 <0.000043>
[pid 9085] 14:20:16.827784 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000034>
[pid 9085] 14:20:16.827945 write(8, "$4\r\ngood\r\n", 10) = 10 <0.000288>
[pid 9085] 14:20:16.828339 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 63, NULL, 8) = 1 <0.000057>
[pid 9085] 14:20:16.828486 read(8, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 16384) = 67 <0.000040>
[pid 9085] 14:20:16.828623 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000052>
[pid 9085] 14:20:16.828760 write(7, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 67) = 67 <0.000060>
[pid 9085] 14:20:16.828970 fdatasync(7) = 0 <0.005415>
[pid 9085] 14:20:16.834493 write(8, ":1\r\n", 4) = 4 <0.000250>
lsof 查看指定进程打开的文件:
$ lsof -p 18940
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 18940 root cwd DIR 0,50 4096 1549389 /
python 18940 root rtd DIR 0,50 4096 1549389 /
…
python 18940 root 2u CHR 136,0 0t0 3 /dev/pts/0
python 18940 root 3w REG 8,1 117944320 303 /tmp/logtest.txt
(4)filetop、opensnoop 动态追踪临时文件情况(追踪快速完成文件操作的情况)
若上述工具不能定位出 write 函数,可能是快速完成文件操作的情况,则需要采用这两工具。
filetop 动态跟踪内核中文件的读写情况,并输出线程ID(TID)、读写大小、读写类型以及文件名称,就可以找出调用频繁的文件。
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
$ echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list
$ sudo apt-get update
$ sudo apt-get install bcc-tools libbcc-examples linux-headers-$(uname -r)
$ cd /usr/share/bcc/tools # 切换到工具目录
$ ./filetop -C # -C 选项表示输出新内容时不清空屏幕
TID COMM READS WRITES R_Kb W_Kb T FILE
514 python 0 1 0 2832 R 669.txt
514 python 0 1 0 2490 R 667.txt
514 python 0 1 0 2685 R 671.txt
514 python 0 1 0 2392 R 670.txt
514 python 0 1 0 2050 R 672.txt
opensnoop 动态跟踪内核中的 open 系统调用,这样就可以找出文件的路径。
$ opensnoop
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/650.txt
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/651.txt
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/652.txt
PS
nsenter - run program with namespaces of other processes
# 由于这两个容器共享同一个网络命名空间,所以我们只需要进入 app 的网络命名空间即可
$ PID=$(docker inspect --format {{.State.Pid}} app)
# -i 表示显示网络套接字信息
$ nsenter --target $PID --net -- lsof -i
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
redis-ser 9085 systemd-network 6u IPv4 15447972 0t0 TCP localhost:6379 (LISTEN)
redis-ser 9085 systemd-network 8u IPv4 15448709 0t0 TCP localhost:6379->localhost:32996 (ESTABLISHED)
python 9181 root 3u IPv4 15448677 0t0 TCP *:http (LISTEN)
python 9181 root 5u IPv4 15449632 0t0 TCP localhost:32996->localhost:6379 (ESTABLISHED)
Linux性能优化从入门到实战:15 文件系统篇:磁盘 I/O的更多相关文章
- Linux性能优化从入门到实战:01 Linux性能优化学习路线
我通过阅读各种相关书籍,从操作系统原理.到 Linux内核,再到硬件驱动程序等等. 把观察到的性能问题跟系统原理关联起来,特别是把系统从应用程序.库函数.系统调用.再到内核和硬件等不同的层级贯 ...
- Linux性能优化从入门到实战:07 CPU篇:CPU性能优化方法
性能优化方法论 动手优化性能之前,需要明确以下三个问题: (1)如何评估性能优化的效果? 确定性能的量化指标.测试优化前的性能指标.测试优化后的性能指标. 量化指标的选择.至少要从应用程序 ...
- Linux性能优化从入门到实战:16 文件系统篇:总结磁盘I/O指标/工具、问题定位和调优
(1)磁盘 I/O 性能指标 文件系统和磁盘 I/O 指标对应的工具 文件系统和磁盘 I/O 工具对应的指标 (2)磁盘 I/O 问题定位分析思路 (3)I/O 性能优化思路 Step 1:首先采用 ...
- Linux性能优化从入门到实战:10 内存篇:如何利用Buffer和Cache优化程序的运行效率?
缓存命中率 缓存命中率,是指直接通过缓存获取数据的请求次数,占所有数据请求次数的百分比,可以衡量缓存使用的好坏.命中率越高,表示使用缓存带来的收益越高,应用程序的性能也就越好. 实际上,缓存是 ...
- Linux性能优化从入门到实战:14 文件系统篇:Linux 文件系统基础
磁盘为系统提供了最基本的持久化存储. 文件系统则在磁盘的基础上,提供了一个用来管理文件的树状结构. 文件系统:索引节点和目录项 文件系统是对存储设备上的文件,进行组织管理的机制.组织方式不 ...
- Linux性能优化从入门到实战:09 内存篇:Buffer和Cache
Buffer 是缓冲区,而 Cache 是缓存,两者都是数据在内存中的临时存储. 避免跟文中的"缓存"一词混淆,而文中的"缓存",则通指内存中的临时存储 ...
- Linux性能优化从入门到实战:17 网络篇:网络基础
网络模型 为了解决网络互联中异构设备的兼容性问题,并解耦复杂的网络包处理流程,国际标准化组织制定了开放式系统互联通信参考模型(Open System Interconnection Reference ...
- Linux性能优化从入门到实战:04 CPU篇:CPU使用率
CPU使用率是单位时间内CPU使用情况的统计,以百分比方式展示. $ top top - 11:46:45 up 7 days, 11:52, 1 user, load average: 0.00 ...
- Linux性能优化从入门到实战:03 CPU篇:CPU上下文切换
linux操作系统是将CPU轮流分配给任务,分时执行的.而每次执行任务时,CPU需要知道CPU寄存器(CPU内置的内存)和程序计数器PC(CPU正在执行指令和下一条指令的位置)值,这些值是CPU执 ...
随机推荐
- Nginx与Lua开发
1.Lua及基础语法 Nginx与Lua环境 场景:用Nginx结合Lua实现代码的灰度发布 1.Lua 是一个简洁.轻量.可扩展的脚本语言 2.Nginx+Lua优势 充分的结合Nginx的并发处理 ...
- All men are brothers
All men are brothers 牛客多校第九场E 给定n个人,起初互不认识 然后m各阶段 每个阶段有两个人x.y认识 求每个阶段选出四个人互不认识的方式 并查集 #include<bi ...
- 大数据笔记(五)——HDFS的高级特性
一.HDFS的回收站: recyclebin 1.HDFS的回收站默认是关闭的 2.启用回收站:去core-site.xml配置 路径:/root/training/hadoop-2.7.3/etc/ ...
- Hadoop 服务SYS CPU过高导致宕机问题
最近某hadoop集群多次出现机器宕机,现象为瞬间机器的sys cpu增长至100%,机器无法登录.只能硬件重启,ganglia cpu信息如下: 首先怀疑有用户启动了比较奇葩的job,导致不合理的系 ...
- 500 cannot be cast to javax.xml.registry.infomodel
在使用mybatis的时候每次一调用一个返回User类型的sql时,总是会报错如下: com.xx.all.domain.User cannot be cast to javax.xml.regist ...
- (转)GitHub中PR(Pull request)操作 - 请求合并代码
转:https://www.jianshu.com/p/b365c743ec8d 前言 本文尽量使用图形工具介绍如何向开源项目提交 Pull Request,一次亲身经历提交 PR 1.fork 项目 ...
- Linux内核调试方法总结之ddebug
[用途] Linux内核动态调试特性,适用于驱动和内核各子系统调试.动态调试的主要功能就是允许你动态的打开或者关闭内核代码中的各种提示信息.适用于驱动和内核线程功能调试. [使用方法] 依赖于CONF ...
- 多线程threading初识二--多线程等待
.join() :子线程等待主线程 下面程序运行流程: 主线程负责启动5个子线程,把每个线程放在threads list里,然后等待所有线程等待完毕后,再执行end_time = time.time( ...
- MVC 源码系列之路由(一)
路由系统 注释:这部分的源码是通过Refector查看UrlRoutingModule的源码编写,这部分的代码没有写到MVC中,却是MVC的入口. 简单的说一下激活路由之前的一些操作.一开始是由MVC ...
- Mac 10.14 下为php 安装xdebug 并让vscode支持
安装Xdebug 寻找对应php版本的xdebug版本 先将info输出到一个文件 php -i > info.txt 打开info.txt 复制所有内容 打开寻找合适xdebug的页面http ...