mysql的最左索引匹配原则
最近复习数据库,主要看的是mysql。很多东西忘得一干二净。看到某乎上有个答案非常给力,就记录一下,以后方便查看。
链接:https://www.zhihu.com/question/36996520/answer/93256153
首先是问题:
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`),
KEY `name_INX` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
随便建了一个student表做测试。
create INDEX name_cid_INX ON student(name,cid)
;
create INDEX name_INX ON student(name);
建了两个索引,故意这样建的。
执行1:
EXPLAIN SELECT * FROM student WHERE name='小红';
 依据mysql索引最左匹配原则,两个索引都匹配上了,这个没有问题。。
依据mysql索引最左匹配原则,两个索引都匹配上了,这个没有问题。。
执行2:
EXPLAIN SELECT * FROM student WHERE cid=1;

EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
 为什么还能匹配索引。
为什么还能匹配索引。
解答:
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`),
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
索引方面:id是主键,(name,cid)是一个多列索引。
-----------------------------------------------------------------------------
下面是你有疑问的两个查询:
EXPLAIN SELECT * FROM student WHERE cid=1;

EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';

你的疑问是:sql查询用到索引的条件是必须要遵守最左前缀原则,为什么上面两个查询还能用到索引?
---------------------------------------------------------------------------------------------------------------------------
讲上面问题之前,我先补充一些知识,因为我觉得你对索引理解是狭隘的:
上述你的两个查询的explain结果中显示用到索引的情况类型是不一样的。,可观察explain结果中的type字段。你的查询中分别是:
1. type: index
2. type: ref
解释:
index:这种类型表示是mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个复合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。
所以:对于你的第一条语句:
EXPLAIN SELECT * FROM student WHERE cid=1;
判断条件是cid=1,而cid是(name,cid)复合索引的一部分,没有问题,可以进行index类型的索引扫描方式。explain显示结果使用到了索引,是index类型的方式。
---------------------------------------------------------------------------------------------------------------------------
ref:这种类型表示mysql会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一 一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。
有些了解的人可能会问,索引不都是一个有序排列的数据结构么。不过答案说的还不够完善,那只是针对单个索引,而复合索引的情况有些同学可能就不太了解了。
下面就说下复合索引:
以该表的(name,cid)复合索引为例,它内部结构简单说就是下面这样排列的:
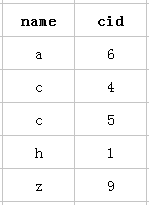
所以:第一个name字段是绝对有序的,而第二字段就是无序的了。所以通常情况下,直接使用第二个cid字段进行条件判断是用不到索引的,当然,可能会出现上面的使用index类型的索引。这就是所谓的mysql为什么要强调最左前缀原则的原因。
那么什么时候才能用到呢?
当然是cid字段的索引数据也是有序的情况下才能使用咯,什么时候才是有序的呢?观察可知,当然是在name字段是等值匹配的情况下,cid才是有序的。发现没有,观察两个name名字为 c 的cid字段是不是有序的呢。从上往下分别是4 5。
这也就是mysql索引规则中要求复合索引要想使用第二个索引,必须先使用第一个索引的原因。(而且第一个索引必须是等值匹配)。
---------------------------------------------------------------------------------------------------------------------------
所以对于你的这条sql查询:
EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
没有错,而且复合索引中的两个索引字段都能很好的利用到了!因为语句中最左面的name字段进行了等值匹配,所以cid是有序的,也可以利用到索引了。
你可能会问:我建的索引是(name,cid)。而我查询的语句是cid=1 AND name='小红'; 我是先查询cid,再查询name的,不是先从最左面查的呀?
好吧,我再解释一下这个问题:首先可以肯定的是把条件判断反过来变成这样 name='小红' and cid=1; 最后所查询的结果是一样的。
那么问题产生了?既然结果是一样的,到底以何种顺序的查询方式最好呢?
所以,而此时那就是我们的mysql查询优化器该登场了,mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。所以,当然是我们能尽量的利用到索引时的查询顺序效率最高咯,所以mysql查询优化器会最终以这种顺序进行查询执行。
mysql的最左索引匹配原则的更多相关文章
- 我说MySQL联合索引遵循最左前缀匹配原则,面试官让我回去等通知
面试官: 我看你的简历上写着精通MySQL,问你个简单的问题,MySQL联合索引有什么特性? 心想,这还不简单,这不是问到我手心里了吗? 听我给你背一遍八股文! 我: MySQL联合索引遵循最左前缀匹 ...
- mysql 最左前缀匹配原则
1.在mysql建立联合索引时会遵循最左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,示例:对列col1.列col2和列col3建一个联合索引 KEY index_col1_co ...
- mysql 联合索引匹配原则
读mysql文档有感 看了mysql关于索引的文档,网上有一些错误的博客文档,这里我自己记一下. 几个重要的概念 1.对于mysql来说,一条sql中,一个表无论其蕴含的索引有多少,但是有且只用一条. ...
- 关于MySQL索引的最左前缀匹配原则原理说明说明
假设有2个这样的SQL SELECT * FROM table WHERE a = 1 AND c = 3; // c不走索引 SELECT * FROM table WHERE a = 1 AND ...
- mysql 查看当前登陆用户匹配原则及权限user()与current_user()
Mysql在进行登陆时,会去匹配mysql库中的user表,并赋予相应的权限,但是怎么知道我们当时的登陆的用户名及相应的权限呢? 在Mysql中,有两个函数,一个是user(),一个是current_ ...
- MySQL的B+树索引和hash索引的区别
简述一下索引: 索引是数据库表中一列或多列的值进行排序的一种数据结构:索引分为聚集索引和非聚集索引,聚集索引查询类似书的目录,快速定位查找的数据,非聚集索引查询一般需要再次回表查询一次,如果不使用索引 ...
- MySQL数据库中的索引(二)——索引的使用,最左前缀原则
上文中,我们了解了MySQL不同引擎下索引的实现原理,在本文我们将继续探讨一下索引的使用以及优化. 创建索引可以大大提高系统的性能. 第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性. ...
- B+树|MYSQL索引使用原则
MySQL一直了解得都不多,之前写sql准备提交生产环境之前的时候,老员工帮我检查了下sql,让修改了一下存储引擎,当时我使用的是Myisam,后面改成InnoDB了.为什么要改成这样,之前都没有听过 ...
- mysql 建立索引的原则
建索引的几大原则 1. 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>.<.between.like)就停止匹配,比如a 1="" an ...
随机推荐
- maven项目创建4 dao层整合
项目配置文件要放在打包成war包的web项目中 创建文件步骤 1 SqlMapConfig.xml <?xml version="1.0" encoding=" ...
- 5.JavaBean
JavaBean JSP开发初期HTML,css,java代码混杂在一起,给程序的调试和维护带来很大困难.将与HTML分离并将对象和逻辑java代码封装成类就是一个JavaBean组件. 1.Java ...
- [LibreOJ 3119]【CTS2019】随机立方体【计数】【容斥】
Description Solution 记\(N=min(n,m,l)\) 首先考虑容斥,记\(f(i)\)为至少有i个位置是极大的,显然极大的位置数上界是N. 那么显然\(Ans=\sum\lim ...
- luoguP1034 矩形覆盖 x
P1034 矩形覆盖 题目描述 在平面上有 n 个点(n <= 50),每个点用一对整数坐标表示.例如:当 n=4 时,4个点的坐标分另为:p1(1,1),p2(2,2),p3(3,6),P4( ...
- Socket编程-基础使用
最后更新:2019-10-25 一 基本概念 socket, 又称为"套接字"或者"插座". 是操作系统提供的一种进程间通信机制.目前大多用于不同网络设备之间的 ...
- crontab 常见 /dev/null 2>&1 详解
大部分在 crontab 计划任务中都会年到未尾带 >/dev/null 2>&1,是什么意思呢? > 是重定向 /dev/null 代表空设备文件 1 表示stdout标准 ...
- R_Studio(cart算法决策树)对book3.csv数据用测试集进行测试并评估模型
对book3.csv数据集,实现如下功能: (1)创建训练集.测试集 (2)用rpart包创建关于类别的cart算法的决策树 (3)用测试集进行测试,并评估模型 book3.csv数据集 setwd( ...
- Redis数据结构常用命令
Redis数据结构--字符串
- python3笔记一:python基础知识
一:学习内容 注释 输入输出 标识符 变量和常量 二:注释 1. 单行注释 #:一个井号,代表我注释了这一行 2.多行注释 ''' ''':注释多行,三个单引号 3.多行注释 "" ...
- navicat常用快捷键与SQL基本使用
一.Navicat常用快捷键 1,Ctrl+q就会弹出一个sql输入窗口 2,Ctrl+r就执行sql了 3,按f6会弹出一个命令窗口 4,Ctrl+/ 注释 5,Ctrl +Shift+/ 解除注释 ...