MYSQL索引优化之单表示例
1. 创建表
CREATE TABLE IF NOT EXISTS `article` (
`id` BIGINT(10) NOT NULL AUTO_INCREMENT,
`author_id` INT(10) NOT NULL,
`category_id` INT(10) NOT NULL,
`views` INT(10) NOT NULL,
`comments` INT(10) NOT NULL,
`title` VARCHAR(10) COLLATE utf8_unicode_ci NOT NULL,
`content` TEXT COLLATE utf8_unicode_ci NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
2. 添加数据
INSERT INTO article(author_id,category_id,views,comments,title, content)
VALUES (1,1,1,1,'1','1'), (2,2,2,2,'2','2'),(1,1,3,3,'3','3');
3. 查询
SELECT * FROM article;

4. 需求
查询category_id 为1 且comments 大于1 的情况下,views 最多的article_id.
5. SQL
SELECT id, author_id FROM article WHERE category_id =1 AND comments>1 ORDER BY views DESC LIMIT 1;
6. 索引优化分析过程
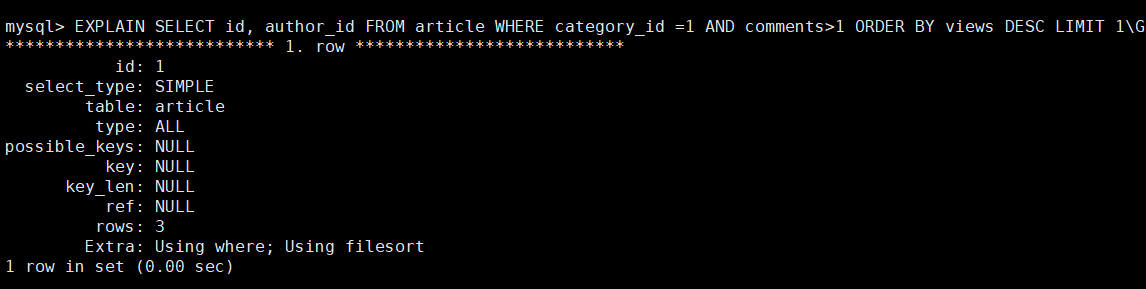
type = ALL : 全表扫描
key = NULL : 没有用到索引,
Extra 中还出现了Using filesort , 产生了二次排序
结论: 垃圾,需要优化。
(1) 第一次创建索引
先查看article原有索引
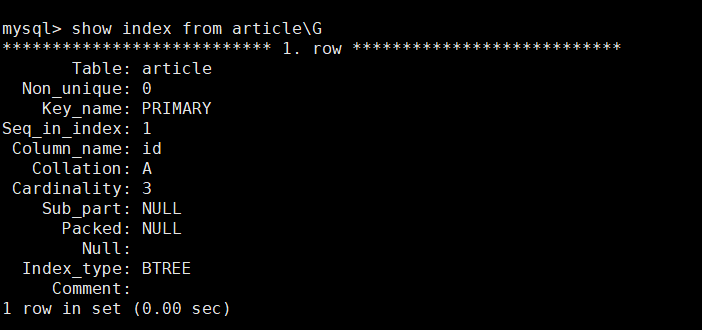
就一主键primary索引。与where ,order by 使用列没得任何关系 ,所以不走索引正常。
下面根据where,order by字段创建一个多列索引
create index idx_c_c_v on article(category_id,comments, views);

再次查看索引
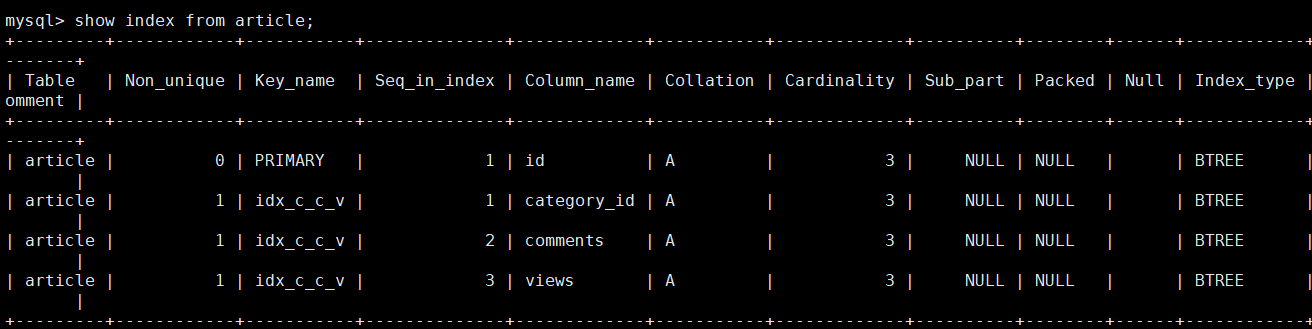
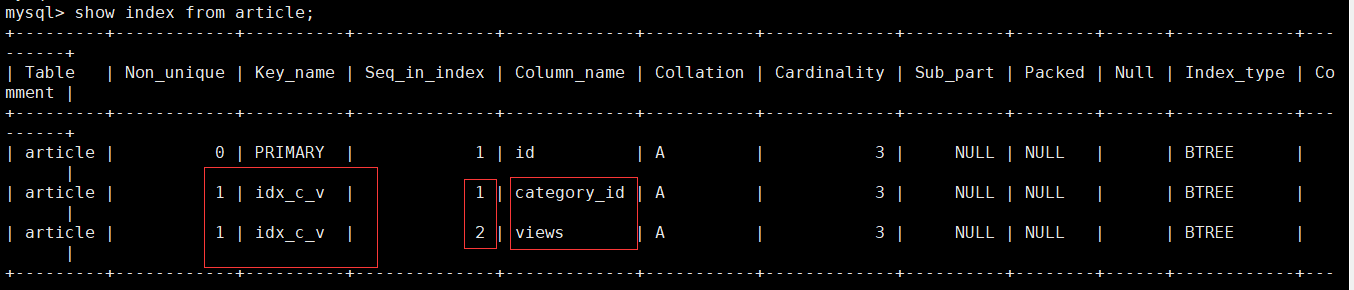
注意索引inx_c_c_v, Seq_in_index 表示索引列查找顺序 ,以上为例 ,表示在使用inx_c_c_v时,先找category_id,再找comments,最后找views。
创建索引之后,我们再分析一下 SELECT id, author_id FROM article WHERE category_id =1 AND comments>1 ORDER BY views DESC LIMIT 1的执行计划。
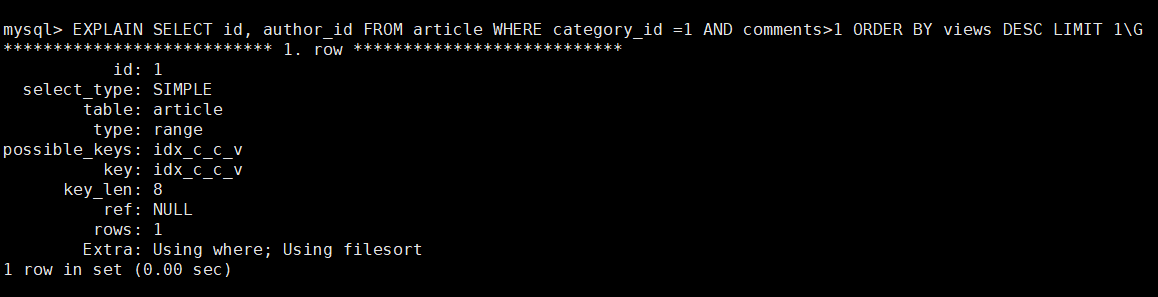
type=range : 范围扫描 ,比之前的type = ALL全表扫描效率要高。
key = inx_c_c_v : 使用了创建的索引。 OK,
Extra : Using filesort , 。。。。。。这个坑货还在。。。。
接着我们再来看下面这个执行计划
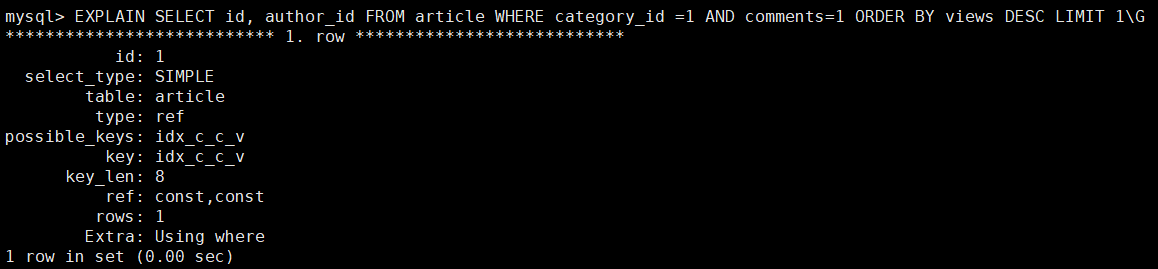
type = ref : 非唯一索引扫描 ,比上面的range 范围扫描效率高呀
key = inx_c_v_v : 使用了索引
ref = const,const : 两个常量,优秀!
Extra ,干掉了Using filesorting
通过对比,我们不难发现,inx_c_c_v不变的情况下,仅是由于查询语句的不同,直接造成执行计划的巨大差异。 其根本原因是comment> 1是个type=range范围查询,它会导致该索引列之后索引列失效,即是(category --√--- comments -----×--views)
所以,index_c_v_v这个索引不行呀,都是因为comments造成的, 所以我们建索引时,不要它,试试!
drop index idx_c_c_v on article;

(2) 第二次创建索引
create index idx_c_v on article(category_id,views);

查看表索引。。。
最后来看一下explain SELECT id, author_id FROM article WHERE category_id =1 AND comments>1 ORDER BY views DESC LIMIT 1\G
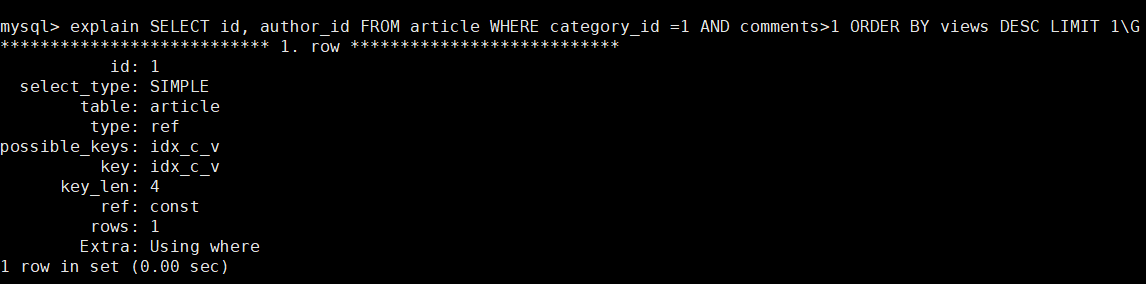
type = ref : 完美
ref = const : 完美
Extra ,没有Using filesort, 也算完美!
总之,还可以吧!
7. 总结
相同的索引 ,select 语句的差别也会造成不同的执行计划,性能差别距大
创建索引时,范围查询需要 特别注意。
MYSQL索引优化之单表示例的更多相关文章
- 深入浅出Mysql索引优化专题分享|面试怪圈
文章纲要 该文章结合18张手绘图例,21个SQL经典案例.近10000字,将Mysql索引优化经验予以总结,你可以根据纲要来决定是否继续阅读,完成这篇文章大概需要25-30分钟,相信你的坚持是不负时光 ...
- Mysql 索引优化分析
MySQL索引优化分析 为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字 ...
- mysql索引优化比普通查询速度快多少
mysql索引优化比普通查询速度快多少 一.总结 一句话总结:普通查询全表查询,速度较慢,索引优化的话拿空间换时间,一针见血,所以速度要快很多. 索引优化快很多 空间换时间 1.软件层面优化数据库查询 ...
- mySql索引优化分析
MySQL索引优化分析 为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字 ...
- MySQL索引优化入门
索引简介 官方定义:索引(Index) 是帮助MySQL高效获取数据的数据结构.大家一定很好奇,索引为什么是一种数据结构,它又是怎么提高查询的速度?我们拿最常用的二叉树来分析索引的工作原理.看下面的图 ...
- 聊聊Mysql索引和redis跳表 ---redis的有序集合zset数据结构底层采用了跳表原理 时间复杂度O(logn)(阿里)
redis使用跳表不用B+数的原因是:redis是内存数据库,而B+树纯粹是为了mysql这种IO数据库准备的.B+树的每个节点的数量都是一个mysql分区页的大小(阿里面试) 还有个几个姊妹篇:介绍 ...
- mysql索引优化
mysql 索引优化 >mysql一次查询只能使用一个索引.如果要对多个字段使用索引,建立复合索引. >越小的数据类型通常更好:越小的数据类型通常在磁盘.内存和CPU缓存中都需要更少的空间 ...
- 聊聊Mysql索引和redis跳表
摘要 面试时,交流有关mysql索引问题时,发现有些人能够涛涛不绝的说出B+树和B树,平衡二叉树的区别,却说不出B+树和hash索引的区别.这种一看就知道是死记硬背,没有理解索引的本质.本文旨在剖析这 ...
- 知识点:Mysql 索引优化实战(3)
知识点:Mysql 索引原理完全手册(1) 知识点:Mysql 索引原理完全手册(2) 知识点:Mysql 索引优化实战(3) 知识点:Mysql 数据库索引优化实战(4) 索引原理知识回顾 索引的性 ...
随机推荐
- 相同name,取最小的id的值,mysql根据相同字段 更新其它字段
id name info1 a 1232 a 2353 a 1244 b 125 b 987相同name,取最小的id的值id name info1 a 1232 a 1233 a 1234 b 12 ...
- BZOJ 5170: Fable
离散化+树状数组 求当前位之前是否有k位比它大 这样的话它就需要前移k位 剩下的按照原来的顺序依次填入 其实我觉得sort一下就可以做出来了 太久没写树状数组了 所以写了一下树状数组 #include ...
- JS-生成器函数(function 星号)的暂停和恢复(yield)
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Statements/function* https://devel ...
- 【经验分享】 解决CentOS7 安装VMTools提示找不到Kernel头文件的方案
配置一个Linux的开发环境,用VM10+CentOS7(Kernel版本3.10.0-327.10.1.el7),之后发现VMTools功能不全,查证后发现需要卸载重装,于是开始折腾. 按照各种说明 ...
- 用notepad++ 打造轻量级Java编译器
http://blog.163.com/jackie_howe/blog/static/19949134720125591752396/ 用notepad++ 打造轻量级Java编译器 2012-06 ...
- WCF身份验证之用户名密码认证
WCF支持多种认证技术,例如Windowns认证.X509证书.Issued Tokens.用户名密码认证等,在跨Windows域分布的系统中,用户名密码认证是比较常用的,要实现用户名密码认证,就必须 ...
- 编程语言-Java-问题整理
jar文件运行报错 - Exception in thread "main" java.lang.UnsupportedClassVersionError 低版本运行高版本文件 ...
- springboot异步任务、定时任务
打开浏览器 http://localhost:8080/hello ,连续刷新可以看到不会 等待 3秒时间了,pom.xml controller service 代码如下. -----------S ...
- ELK日志分析系统之logstash7.x最新版安装与配置
2 .Logstash的简介 2.1 logstash 介绍 LogStash由JRuby语言编写,基于消息(message-based)的简单架构,并运行在Java虚拟机(JVM)上.不同于分离的代 ...
- phpcms列表分页ajax加载更多
1.在phpcms\modules\content\index.php文件中添加以下函数: /*列表分页ajax加载更多*/ public function homeajaxlist() { if( ...