迁移学习(CDAN)《Conditional Adversarial Domain Adaptation》(已复现迁移)
论文信息
论文标题:Conditional Adversarial Domain Adaptation
论文作者:Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain
论文来源:JMLR 2016
论文地址:download
论文代码:download
引用次数:5292
1 背景
1. 1 问题
- 普通的对抗域自适应方法仅独立对齐特征,而未对于标签进行对齐,往往不充分 ==============> 对齐特征与类别的联合分布
- 当数据分布包含复杂的多模态结构时,对抗性自适应方法可能无法捕捉到这样的多模态结构,多模态结构只能通过特征和类之间的交叉协方差依赖性来充分捕获;即使判别器完全混淆,也不能保证两个分布完全相似 ==============> 多线性调整
- 条件域判别器强制使不同的样本具有相同的重要性,可能导致不确定预测的难迁移样本也许会对抗适应产生不良影响 ==============> 熵调整
1.2 条件生成对抗网络(CGAN)
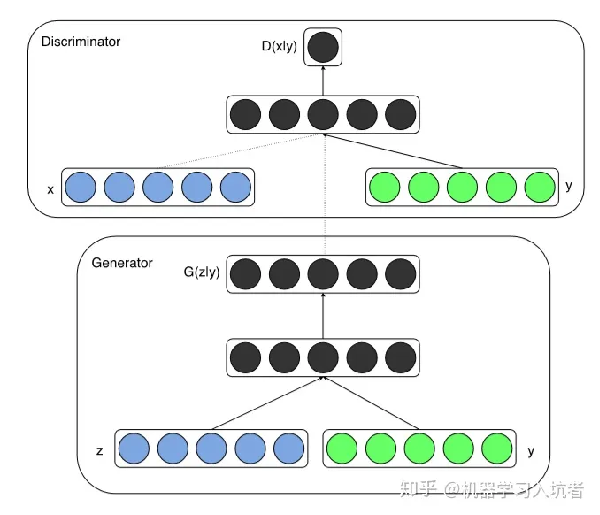
- CGAN 是在 GAN 基础上做的一种改进,通过给原始 GAN 的生成器和判别器添加额外的条件信息(类别标签或者其它辅助信息),实现条件生成模型
- 对于生成器将类别标签与噪声信号的组合作为生成图片的输入;对于判别器将类别标签与图像数据拼接结果 x⨁y 作为输入
- CGAN 可解决带标签的数据生成问题
2 方法
2.1 整体框架(CDAN)
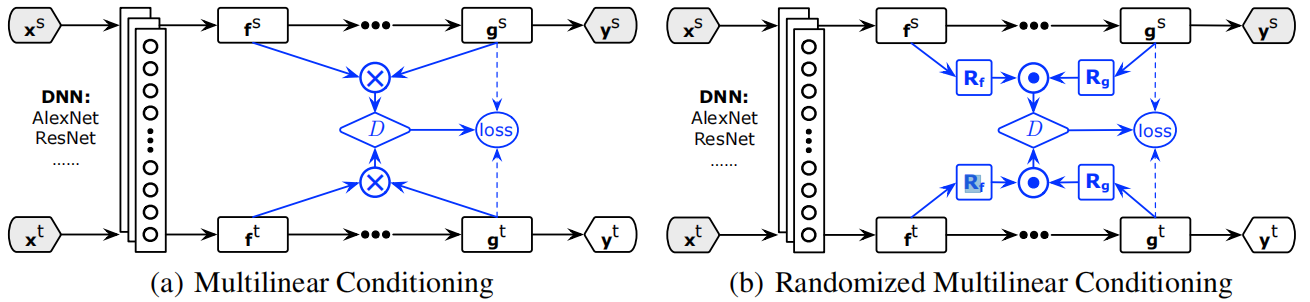
(a) 多线性调整:适用于低维场景, 将特征与类别的多线性映射 $T_{\otimes}(f, g)$ 作为鉴别器 $D$ 的输入
(b) 随机多线性调整:适用于高维场景, 随机抽取 $f$, $g$ 上的某些维度的多线性映射 $T_{\odot}(f, g)$ 作为鉴别器的输入损失函数
损失函数:
$\begin{array}{l}\mathcal{E}(G)=\mathbb{E}_{\left(\mathbf{x}_{i}^{s}, \mathbf{y}_{i}^{s}\right) \sim \mathcal{D}_{s}} L\left(G\left(\mathbf{x}_{i}^{s}\right), \mathbf{y}_{i}^{s}\right) \\\mathcal{E}(D, G)=-\mathbb{E}_{\mathbf{x}_{i}^{s} \sim \mathcal{D}_{s}} \log \left[D\left(\mathbf{f}_{i}^{s}, \mathbf{g}_{i}^{s}\right)\right]-\mathbb{E}_{\mathbf{x}_{j}^{t} \sim \mathcal{D}_{t}} \log \left[1-D\left(\mathbf{f}_{j}^{t}, \mathbf{g}_{j}^{t}\right)\right] \\ \underset{G}{\text{min}} \quad \mathcal{E}(G)-\lambda \mathcal{E}(D, G) \\ \underset{D}{\text{min}} \quad \mathcal{E}(D, G) \end{array}$
2.2 $f \oplus g$ 与 $f \otimes g$
$f \oplus g$ 串联: 直接将特征表示和分类器预测的类别标签拼接起来,由于 $f$, $g$ 相互独立,无法完全捕获特征表示和分类器预测之间的乘法交互作用,均值映射独立计算 $x$, $y$ 的均值:
$\mathbb{E}_{\mathbf{x y}}[\mathbf{x} \oplus \mathbf{y}]=\mathbb{E}_{\mathbf{x}}[\mathbf{x}] \oplus \mathbb{E}_{\mathbf{y}}[\mathbf{y}]$
即:将类信息和特征信息简单拼接;
$f \otimes g$ 多线性映射:模拟了不同变量之间的乘法相互作用,可以完全捕捉复杂数据分布背后的多模态结构,均值映射计算了每个类条件分布 $P(x \mid y)$ 的 均值:
$\mathbb{E}_{\mathbf{x y}}[\mathbf{x} \otimes \mathbf{y}]=\mathbb{E}_{\mathbf{x}}[\mathbf{x} \mid y=1] \oplus \ldots \oplus \mathbb{E}_{\mathbf{x}}[\mathbf{x} \mid y=C]$
即:用类信息对每个样本特征加权,然后拼接;
2.3 梯度爆炸
多线性映射的维度为 $f$, $g$ 的维度之积,易导致维度爆炸, 因此采用随机方法解决此问题,抽取 $f$, $g$ 上的某些维度做多线性映射,以近似 $f \otimes g$ :
$T_{\odot}(\mathbf{f}, \mathbf{g})=\frac{1}{\sqrt{d}}\left(\mathbf{R}_{\mathbf{f}} \mathbf{f}\right) \odot\left(\mathbf{R}_{\mathbf{g}} \mathbf{g}\right)$
其中 $\boldsymbol{R}_{\boldsymbol{f}}$, $\boldsymbol{R}_{g}$ 为训练过程中固定不变的随机矩阵,每个元素服从单方差对称分布, 适用分布包括均匀分布、高斯分布等; $\odot$ 表示矩阵对应位置元素相乘的操作; $d$ 表示抽取的维度数。
Note:显然公式是错误的 [ 矩阵左乘考虑的是样本之间的线性关系],$\mathbf{R}_{\mathbf{f}} \mathbf{f}$ 和 $\mathbf{R}_{\mathbf{g}} \mathbf{g}$ 的维度都对不上,正确如下:
$T_{\odot}(\mathbf{f}, \mathbf{g})=\frac{1}{\sqrt{d}}\left( \mathbf{f} \mathbf{R}_{\mathbf{f}}\right) \odot\left( \mathbf{g}\mathbf{R}_{\mathbf{g}}\right)$
可证明 $T_{\odot}$ 上进行内积近似 $T_{\otimes}$ 上进行内积,且 $T_{\odot}$ 是 $T_{\otimes}$ 的无偏估计,以深度网络最大单无数 4096 作为阈值:
$T(\mathbf{h})=\left\{\begin{array}{ll}T_{\otimes}(\mathbf{f}, \mathbf{g}) & \text { if } d_{f} \times d_{g} \leqslant 4096 \\T_{\odot}(\mathbf{f}, \mathbf{g}) & \text { otherwise }\end{array}\right.$
2.4 熵调整(CDAN+E)
公式如下:
$\begin{array}{l}\underset{G}{\text{min}} \quad \mathbb{E}_{\left(\mathbf{x}_{i}^{s}, \mathbf{y}_{i}^{s}\right) \sim \mathcal{D}_{o}} L\left(G\left(\mathbf{x}_{i}^{s}\right), \mathbf{y}_{i}^{s}\right) \\ \quad\quad+\lambda\left(\mathbb{E}_{\mathbf{x}_{i}^{s} \sim \mathcal{D}_{s}} \log \left[D\left(T\left(\mathbf{h}_{i}^{s}\right)\right)\right]+\mathbb{E}_{\mathbf{x}_{j}^{t} \sim \mathcal{D}_{t}} \log \left[1-D\left(T\left(\mathbf{h}_{j}^{t}\right)\right)\right]\right) \\\end{array}$
$\underset{D}{\text{max}} \quad \mathbb{E}_{\mathbf{x}_{i}^{s} \sim \mathcal{D}_{s}} \log \left[D\left(T\left(\mathbf{h}_{i}^{s}\right)\right)\right]+\mathbb{E}_{\mathbf{x}_{j}^{t} \sim \mathcal{D}_{t}} \log \left[1-D\left(T\left(\mathbf{h}_{j}^{t}\right)\right)\right]$
损失问题:条件域判别器的最大最小优化方法强制使不同的样本具有相同的重要性,可能导致不确定预测的难迁移样本也许会对抗适应产生不良影响
分类器预测不确定性的量化,使用熵定量预测的不确定性:
$H(\mathrm{~g})=-\sum_{c=1}^{C} g_{c} \log g_{c}$
预测的确定性则可表示为 $e^{-H(g)}$
损失改进:使用熵权重 $w(H(g))$调整条件域判别器接收的各个训练样本,使易于迁移的样本优先级更高,规避难迁移样本的影响:
$w(H(\mathbf{g}))=1+e^{-H(\mathbf{g})}$
熵调整后的损失函数:
$\begin{array}{l}\underset{G}{\text{min}} \quad \mathbb{E}_{\left(\mathbf{x}_{i}^{s}, \mathbf{y}_{i}^{s}\right) \sim \mathcal{D}_{s}} L\left(G\left(\mathbf{x}_{i}^{s}\right), \mathbf{y}_{i}^{s}\right) \\\quad+\lambda\left(\mathbb{E}_{\mathbf{x}_{i}^{s} \sim \mathcal{D}_{s}} w\left(H\left(\mathbf{g}_{i}^{s}\right)\right) \log \left[D\left(T\left(\mathbf{h}_{i}^{s}\right)\right)\right]+\mathbb{E}_{\mathbf{x}_{j}^{t} \sim \mathcal{D}_{t}} w\left(H\left(\mathbf{g}_{j}^{t}\right)\right) \log \left[1-D\left(T\left(\mathbf{h}_{j}^{t}\right)\right)\right]\right) \\\end{array}$
$\underset{D}{\text{max}} \quad \mathbb{E}_{\mathbf{x}_{i}^{s} \sim \mathcal{D}_{s}} w\left(H\left(\mathbf{g}_{i}^{s}\right)\right) \log \left[D\left(T\left(\mathbf{h}_{i}^{s}\right)\right)\right]+\mathbb{E}_{\mathbf{x}_{j}^{t} \sim \mathcal{D}_{t}} w\left(H\left(\mathbf{g}_{j}^{t}\right)\right) \log \left[1-D\left(T\left(\mathbf{h}_{j}^{t}\right)\right)\right]$
Note:熵越大,权重越小;
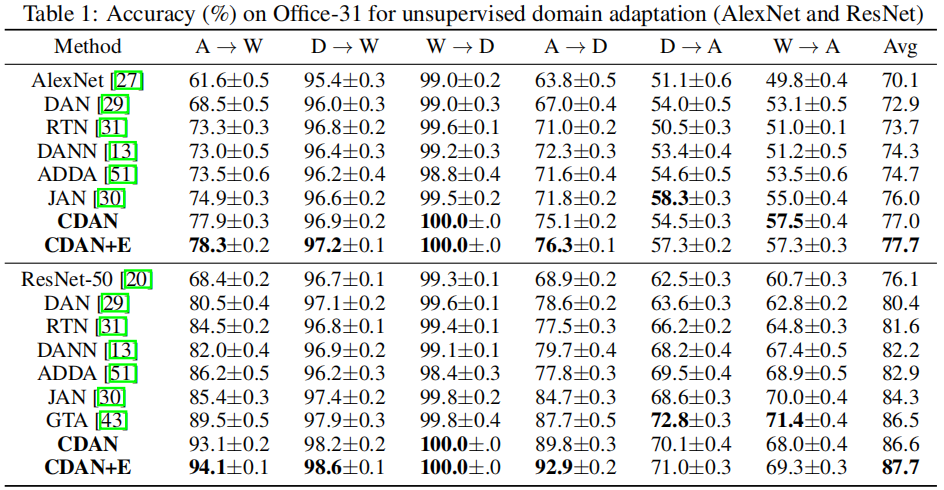
3 实验
迁移学习(CDAN)《Conditional Adversarial Domain Adaptation》(已复现迁移)的更多相关文章
- 【深度学习系列】迁移学习Transfer Learning
在前面的文章中,我们通常是拿到一个任务,譬如图像分类.识别等,搜集好数据后就开始直接用模型进行训练,但是现实情况中,由于设备的局限性.时间的紧迫性等导致我们无法从头开始训练,迭代一两百万次来收敛模型, ...
- 迁移学习(Transformer),面试看这些就够了!(附代码)
1. 什么是迁移学习 迁移学习(Transformer Learning)是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中.迁移学习是通过从已学习的相 ...
- 迁移学习、fine-tune和局部参数恢复
参考:迁移学习——Fine-tune 一.迁移学习 就是把已训练好的模型参数迁移到新的模型来帮助新模型训练. 模型的训练与预测: 深度学习的模型可以划分为 训练 和 预测 两个阶段. 训练 分为两种策 ...
- 【转载】 第四范式首席科学家杨强:AlphaGo的弱点及迁移学习的应对(附视频)
原文地址: https://www.jiqizhixin.com/articles/2017-06-02-2 ============================================= ...
- 《A Survey on Transfer Learning》迁移学习研究综述 翻译
迁移学习研究综述 Sinno Jialin Pan and Qiang Yang,Fellow, IEEE 摘要: 在许多机器学习和数据挖掘算法中,一个重要的假设就是目前的训练数据和将来的训练数据 ...
- 使用PyTorch进行迁移学习
概述 迁移学习可以改变你建立机器学习和深度学习模型的方式 了解如何使用PyTorch进行迁移学习,以及如何将其与使用预训练的模型联系起来 我们将使用真实世界的数据集,并比较使用卷积神经网络(CNNs) ...
- 迁移学习( Transfer Learning )
在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型:然后利用这个学习到的模型来对测试文档进行分类与预测.然而,我们看到机器学习算法在当前的Web挖掘研究中存在着一个关 ...
- 迁移学习(Transfer Learning)(转载)
原文地址:http://blog.csdn.net/miscclp/article/details/6339456 在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型 ...
- 迁移学习(Transfer Learning)
原文地址:http://blog.csdn.net/miscclp/article/details/6339456 在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型 ...
- 基于双向LSTM和迁移学习的seq2seq核心实体识别
http://spaces.ac.cn/archives/3942/ 暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下.模型的效果不是最好的,但是胜在“端到端”, ...
随机推荐
- openwrt从gitee pull代码并编译go项目
安装ssh opkg update # openssh-keygen 可以用来生产密钥 opkg install openssh-keygen # 连接其他服务器 opkg install opens ...
- 创建一个简单的signalr项目
1:新建一个empty的MVC项目 2:如果没有安装过signalr过那么要通过Nuget安装signalr 3:新建一个controller 然后建一个view =>index 4:新建一个s ...
- bzoj 2337
有人说这题像游走... 关于游走的思想,他死了... 明明直接从期望dp的角度考虑更简单合理嘛 首先由于是异或运算不妨逐位考虑 对于每一位,设状态$f[i]$表示从第$i$个点到第$n$个点,这一位上 ...
- 在windows下使用dbus
介绍 DBUS是一种很方便的IPC远程调用的通信机制.可以很方便地调用其他进程提供的函数,甚至是不同计算机上提供的函数,内部通过TCP套接字进行相互通信. 不过甚至你可以修改成其他通信方式,比如USB ...
- Linux(CentOS7)中安装Docker
Linux(CentOS7)中安装Docker 什么是Docker? Docker是一个开源项目, 诞生于2013年初,最初是dotCloud公司内部的一个业余项目.它基于Google公司推出的Go语 ...
- 前端JS常用设计模式
话不多说,这里记录一些常见的设计模式,常看常新,也能提升JavaScript编程水平 一.设计原则 二.单例模式 单例模式的定义是,保证一个类仅有一个实例,并且要提供访问他的全局api 单例模式在前端 ...
- SpringBoot整合其他框架
SpringBoot整合Junit 实现步骤 搭建SpringBoot工程 引入starter-test起步依赖 编写测试类 添加测试相关注解 @RunWith(SpringRunner.class) ...
- 【python】第一模块 步骤五 第二课、Python多线程
第二课.Python多线程 一.课程介绍 1.1 课程概要 章节概要 进程.线程与并发 对多核的利用 实现一个线程 线程之间的通信 线程的调度和优化 1.2 为什么要学习多线程 (线程)使用场景 快速 ...
- GIS介绍(详细)一、什么是GIS?
其他GIS空间分析文章 博主的参考书籍是科学出版社的地理信息系统原理(华一新.赵军喜等) 一.什么是GIS? 要说明什么是GIS,我们就得学习其基本术语,从而引出GIS的定义: 1.信息 狭义的信息论 ...
- Linux 中最常用 150 个命令汇总