系统评价——主成分分析PCA的R语言实现(六)
主成分分析(Principal Component Analysis,PCA),是将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法,起到数据约减和集成的作用。在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律。多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的工作量。更重要的是在很多情形下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性。因此需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。主成分分析就属于这类降维算法,尽管每个变量都在不同程度上反映这个课题的某些信息,但使用起来很不方便,引入主成分对这些原始数据进行信息提取会得到极大的简化。

一、差异才是信息
考虑下面生活中的例子,小明买了五个西瓜,每个西瓜都有重量、颜色、形状、纹路、气味五种属性:
| 指标 | 西瓜A | 西瓜B | 西瓜C | 西瓜D | 西瓜E |
|---|---|---|---|---|---|
| 重量 | 1 | 3 | 2 | 8 | 8 |
| 颜色 | 1 | 2 | 2 | 8 | 9 |
| 形状 | 6 | 7 | 6 | 6 | 7 |
| 纹路 | 3 | 2 | 3 | 9 | 9 |
| 气味 | 1 | 2 | 1 | 1 | 1 |
注:这里的离散属性我们已经做了某种数字化处理,比如颜色数值越小表示越接近浅黄色,颜色数值越大越接近深绿色,形状数值越接近1代表越接近球形等。
小明回到家,观察了西瓜们的五种属性,他觉得对于这五个西瓜来说,气味和形状是完全没有必要去关注的,可以直接丢弃不看。对于西瓜的重量属性和形状属性,他发现这俩种似乎是不同的两种性质。把西瓜们的重量\(X\)和形状属性\(Y\)拿出来画图示意:

从数据分布上估计,相比\(X\)属性来说,\(Y\)属性的方差(variance)不大,即所有的西瓜这个属性都不怎么变化,因此比较所有的西瓜时其实不用考虑\(Y\)这一属性(反正所有西瓜的\(Y\)属性数值都差不多相同,所以就不用关注了)。方差在这方面最著名的应用就是量化金融领域中的风险,感兴趣的读者可参看经典马科维茨投资组合理论(https://zhuanlan.zhihu.com/p/353421604)。这属于数据过渡收集,会造成收集、处理等多方面的问题,也是试收集的原因所在。在数据科学和统计应用中,通常需要对含有多个变量的数据进行观测,多变量的大数据集固然不错,但是也在一定程度上增加了数据采集的工作量和问题分析和建立模型的复杂性。
一项十分著名的工作是美国的统计学家斯通(stone)在1947年关于国民经济的研究。他曾利用美国1929一1938年各年的数据,得到了17个反映国民收入与支出的变量要素,例如雇主补贴、消费资料和生产资料、纯公共支出、净增库存、股息、利息外贸平衡等等。在进行主成分分析后,竟以97.4%的精度,用三新变量就取代了原17个变量。根据经济学知识,斯通给这三个新变量分别命名为总收入F1、总收入变化率F2和经济发展或衰退的趋势F3。
一九九零年代,主成分分析引入到人脸识别领域后,随即挂起一阵旋风, 大家对其人脸图像数据的高效特征抽取能力爱不释手,因其不仅将图像数据的维数大大降低,而且还能取得很优的人脸识别效果。

二、主成分分析PCA的基本思想
PCA可以对相关变量进行归类,从而降低数据维度,提高对数据的理解。分析的主要目的一般是:1)识别数据集中的潜在变量,2)通过去除数据中的噪声和冗余来降低数据的维度,3)识别相关变量。随着变量数量的增加,模型估计所需的样本数量呈指数增长(维数灾难)。过多的变量中,某些变量可能彼此关联,最后起到的作用是一样的。PCA分析可以对相关变量进行归类,从而得到一个更小的,但保留原来大部分信息的变量集合。这些新的变量(主成分,PC)的彼此高度不相关,可继续用于监督式学习和可视化。
如图所示,平面上散落着\(N\)个点,无论是沿\(x_1\)轴方向,还是沿\(x_2\)轴方向,均有较大的离散性,即这些点所代表的信息由两个指标\(x_1,x_2\)所决定,若只考虑\(x_1\)和\(x_2\)中的任何一个,原始数据中的信息均会有较大的损失。
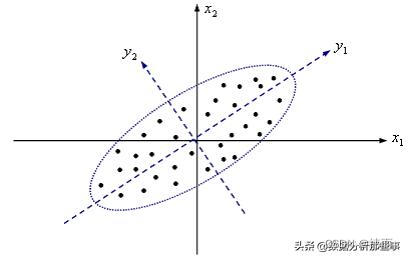
但是我们将坐标轴进行一个旋转操作,得到新的坐标轴\(y_1\)和\(y_2\),如上图所示,则会发现这些点只在\(y_1\)方向上由较大的离散性,即\(y_1\)可以代表原始数据的绝大部分信息。也就是说原来需要2个指标才能表示的信息,经过一些处理,变成只需要1个指标,而且不会损失太多的信息,即所谓的降维。主成分其实是变量的规范化线性组合,PC1是能够最大程度解释数据中的方差的特征线性组合,PC2是另一种特征线性组合,其在保持与PC1方向上垂直(PC1与PC2完全不相关)的情况下,最大程度解释数据中的方差。求解主成分,就是根据原始数据的协方差阵,求解特征根,特征向量的过程。主成分可以利用协方差阵的特征值对应的单位正交特征向量来表示。贡献率等于单个特征根除以总特征根之和。协相关系数矩阵的特征向量为主成分系数 征值除以总的特征值之和就是相应主成分分析的占比。
三、 主成分分析的计算步骤
该方法可以用来数据降维,把很多的评价指标减少为几个主要的评价指标,即主成分,同样这个方法也可以用来求权重。设有\(m\)个评价对象和\(n\)个评价指标(亦即原始的数据结构)
对原始数据进行标准化处理
\]
式中:\(μ\)是样本均值,\(s\)是样本标准差
相关系数矩阵(标准化协方差矩阵)的计算
\]
\(k_i\)是第\(k\)个评价对象的第\(i\)个指标,\(k_j\)是第\(k\)个评价对象的第\(j\)个指标;求和是为了计算所有\(k\)个评价对象的第\(i\)个指标,第\(j\)个指标的关系;\(r\)为第\(i\)个指标和第\(j\)个指标的总相关系数,与评价对象无关,只是评价指标间的相互关系,最后得到\(R=[r_{ij}]\)为一个\(n\times n\)的矩阵。
特征值和特征向量
计算出\(R\)的特征值\(λ_1>λ_2>λ_3>...λ_n>0\),和对应的特征向量\(u_1,u_2,...,u_n\),那么构成\(n\)个新的指标向量
\]
其中
\]
称\(y_1\)为第1主成分,\(y_2\)为第2主成分,\(y_3\)为第3主成分,...,\(y_n\)为第\(n\)主成分
对选取的\(p(p<=n)\)个主成分,计算综合评价值
a 计算特征值λ的信息贡献率和累积贡献率
称
\]
称
\]
实际上就是对特征值\(λ\)的归一化过程,将其都约束在0,1范围内。当累积贡献率接近1(达到0.85以上,这个值和研究的问题有关,有时也取0.80),就可以选择这前\(p\)个主成分来代替原来的\(n\)个指标变量,从而可以对这\(p\)个主成分进行总和分析。
\]
\(b\)为第\(j\)个主成分的信息贡献率,\(y_j\)为第\(j\)个主成分,就是以各个主成分的贡献率\(b\)为权重对各个主成分进行加权求和,而各个主成分其实就是以特征值\(λ\)为权重对各个标准化指标向量求和。
四、R语言计算示例
4.1 常用函数
R中作为主成分分析最主要的函数是princomp()函数。
scale()函数 原始数据标准化
cor()函数(cov()函数) 数据的相关矩阵(协方差矩阵)
princomp() 主成分分析 可以从相关阵或者从协方差阵做主成分分析
summary() 提取主成分信息
loadings() 显示主成分分析或因子分析中载荷的内容
predict() 预测主成分的值
screeplot() 画出主成分的碎石图
biplot() 画出数据关于主成分的散点图和原坐标在主成分下的方向
4.2 计算过程
现有30名中学生身高、体重、胸围、坐高数据,对身体的四项指标数据做主成分分析,原始数据收集如下:
test<-data.frame(
X1=c(148,139, 160, 149, 159, 142, 153, 150, 151, 139,140, 161, 158, 140, 137, 152, 149,145, 160, 156,151, 147, 157, 147, 157, 151, 144, 141, 139, 148),
X2=c(41, 34,49, 36, 45, 31, 43, 43, 42, 31,29, 47, 49, 33, 31, 35, 47, 35, 47, 44,42, 38,39, 30, 48, 36, 36, 30, 32, 38),
X3=c(72, 71,77, 67, 80, 66, 76, 77, 77, 68,64, 78, 78, 67, 66, 73, 82, 70, 74, 78,73, 73,68, 65, 80, 74, 68, 67, 68, 70),
X4=c(78, 76,86, 79, 86, 76, 83, 79, 80, 74,74, 84, 83, 77, 73, 79, 79, 77, 87, 85,82, 78,80, 75, 88, 80, 76, 76, 73, 78))
主成分分析
test.pr<-princomp(test,cor=TRUE)
#cor是逻辑变量,当cor=TRUE时表示用样本的相关矩阵R(!!!)做主成分分析;当cor=FALSE时表示用样本的协方差阵S(!!!)做主成分分析,常选取相关矩阵做主成分分析
summary(test.pr,loadings=TRUE)
#loading是逻辑变量,当loading=TRUE时表示显示loading 的内容,loadings的输出结果为载荷,是主成分对应于原始变量的系数即Q矩阵
结果展示
Importance of components:
Comp.1 Comp.2 Comp.3 Comp.4
Standard deviation 1.8817805 0.55980636 0.28179594 0.25711844
Proportion of Variance 0.8852745 0.07834579 0.01985224 0.01652747
Cumulative Proportion 0.8852745 0.96362029 0.98347253 1.00000000
Loadings:
Comp.1 Comp.2 Comp.3 Comp.4
X1 0.497 0.543 0.450 0.506
X2 0.515 -0.210 0.462 -0.691
X3 0.481 -0.725 -0.175 0.461
X4 0.507 0.368 -0.744 -0.232
Standard deviation 标准差 其平方为方差=特征值
Proportion of Variance 方差贡献率
Cumulative Proportion 方差累计贡献率
由结果显示 前两个主成分的累计贡献率已经达到96%,因而可舍去另外两个主成分,达到降维的目的。可以得到两个主成分的函数表达式:
Z2=0.543X1-0.210X2-0.725X3+0.368X4
\]
主成分的碎石图
screeplot(test.pr,type="lines")

由图可以看出,第二个主成分之后图线变化趋于平稳,因此可以选择前两个主成分做分析。
原始数据的主成分重构
p<-predict(test.pr)
predict函数根据主成分生成最后的新变量(即将原始数据矩阵X与主成分系数矩阵A结合,生成最后的主成分新变量,用这个生成的新变量代替原始变量)。
Comp.1 Comp.2 Comp.3 Comp.4
[1,] -0.06990950 -0.23813701 0.35509248 -0.266120139
[2,] -1.59526340 -0.71847399 -0.32813232 -0.118056646
[3,] 2.84793151 0.38956679 0.09731731 -0.279482487
[4,] -0.75996988 0.80604335 0.04945722 -0.162949298
[5,] 2.73966777 0.01718087 -0.36012615 0.358653044
[6,] -2.10583168 0.32284393 -0.18600422 -0.036456084
[7,] 1.42105591 -0.06053165 -0.21093321 -0.044223092
[8,] 0.82583977 -0.78102576 0.27557798 0.057288572
..........(30个数据)
主成分得分
test.pr$scores #给出各个主成分的得分
test.pr$scores
Comp.1 Comp.2 Comp.3 Comp.4
[1,] -0.06990950 -0.23813701 0.35509248 -0.266120139
[2,] -1.59526340 -0.71847399 -0.32813232 -0.118056646
[3,] 2.84793151 0.38956679 0.09731731 -0.279482487
[4,] -0.75996988 0.80604335 0.04945722 -0.162949298
[5,] 2.73966777 0.01718087 -0.36012615 0.358653044
[6,] -2.10583168 0.32284393 -0.18600422 -0.036456084
[7,] 1.42105591 -0.06053165 -0.21093321 -0.044223092
[8,] 0.82583977 -0.78102576 0.27557798 0.057288572
...................
在本例中,综合得分Score为 综合得分=各主成分的得分*各主成分方差/各主成分的方差和
\]
其中,Comp.1为主成分1的得分,Comp.2为主成分2的得分。现通过自编函数,进行综合得分的计算。
#下面程序给出了各行原始数据的得分排序
#m为主成分个数
caculate_score<-function(PCA,m){
comp_sd<-summary(PCA)$sdev[1:m] #各主成分标准差
comp_score_matrix<-PCA$scores[,1:m] #各主成分得分矩阵
comp_score<-data.frame(comp_score_matrix)
#计算综合得分
comp_score$PC<-as.numeric(comp_score_matrix%*%comp_sd^2/sum(comp_sd^2))
#计算排名
comp_score$rank<-rank(-comp_score$PC)
return(comp_score)
}
score<-caculate_score(test.pr,2)
rownames(score)<-rownames(test)
head(score)
Comp.1 Comp.2 PC rank
1 -0.0699095 -0.23813701 -0.0835870 16
2 -1.5952634 -0.71847399 -1.5239773 22
3 2.8479315 0.38956679 2.6480576 2
4 -0.7599699 0.80604335 -0.6326474 19
5 2.7396678 0.01718087 2.5183198 3
6 -2.1058317 0.32284393 -1.9083716 25
...............
主成分得分图
plot(score$Comp.1,score$Comp.2,xlab='Comp.1',ylab='Comp.2',main='主成分得分图')
abline(h=0,lty=3);abline(v=0,lty=3)
text(score$Comp.1,score$Comp.2,rownames(score))

分析结果双标图(第1主成分和第2主成分)
biplot(test.pr)

五、R语言完整代码
#data.csv的数据结构模仿R语言自带数据swiss
raw_data<-read.csv("data.csv",header=T)
#raw_data=swiss
new_data<-raw_data[,-1]
options(digits=2)
cor(new_data)
PCA=princomp(new_data,cor=T)
summary(PCA)
screeplot(PCA,type="lines")
#计算综合得分
caculate_score<-function(PCA,m){
comp_sd<-summary(PCA)$sdev[1:m] #各主成分标准差
comp_score_matrix<-PCA$scores[,1:m] #各主成分得分矩阵
comp_score<-data.frame(comp_score_matrix)
#计算综合得分
comp_score$PC<-as.numeric(comp_score_matrix%*%comp_sd^2/sum(comp_sd^2))
#计算排名
comp_score$rank<-rank(-comp_score$PC)
return(comp_score)
}
score<-caculate_score(PCA,2)
rownames(score)<-raw_data[,1]
head(score)
#绘制得分图
plot(score$Comp.1,score$Comp.2,
xlab='Comp.1',ylab='Comp.2',main='主成分得分图')
abline(h=0,lty=3);abline(v=0,lty=3)
text(score$Comp.1,score$Comp.2,rownames(score))
总结
主成分分析(PCA)是一种经典的线性维归约方法,基于高维空间的数据寻找主成分将其转换至低维空间,并保证低维空间下每个维度具有最大方差且不相关性。主成分分析,就是一种降维的分析方法,其考察多个变量间相关性的一种多元统计方法,研究如何通过少数几个主成分来揭示多个变量间的内部结构,即从原始变量中导出少数几个主成分,使它们尽可能多地保留原始变量的信息,且彼此间互不相关。主成分与原始变量之间的关系:
(1)主成分保留了原始变量绝大多数信息。
(2)主成分的个数大大少于原始变量的数目。
(3)各个主成分之间互不相关。
(4)每个主成分都是原始变量的线性组合。
利用上面数据之间的关系,可以在学生成绩综合评估、地区发展综合评估、运动员综合能力评估等场景中,用较少的几个新变量代替原本的变量而尽可能保留原有信息,计算出综合得分进而给出综合评价结果。
参考文献
主成分分析法PCA(评价与决策)
主成分分析法
用R语言做主成分分析
详解R语言中的PCA分析与可视化
系统评价——主成分分析PCA的R语言实现(六)的更多相关文章
- 主成分分析(PCA)原理及R语言实现
原理: 主成分分析 - stanford 主成分分析法 - 智库 主成分分析(Principal Component Analysis)原理 主成分分析及R语言案例 - 文库 主成分分析法的原理应用及 ...
- 主成分分析(PCA)原理及R语言实现 | dimension reduction降维
如果你的职业定位是数据分析师/计算生物学家,那么不懂PCA.t-SNE的原理就说不过去了吧.跑通软件没什么了不起的,网上那么多教程,copy一下就会.关键是要懂其数学原理,理解算法的假设,适合解决什么 ...
- R语言主成分分析(PCA)
数据的导入 > data=read.csv('F:/R语言工作空间/pca/data.csv') #数据的导入> > ls(data) #ls()函数列出所有变量 [1] " ...
- 【转】R语言主成分分析(PCA)
https://www.cnblogs.com/jin-liang/p/9064020.html 数据的导入 > data=read.csv('F:/R语言工作空间/pca/data.csv') ...
- PCA主成分分析 R语言
1. PCA优缺点 利用PCA达到降维目的,避免高维灾难. PCA把所有样本当作一个整体处理,忽略了类别属性,所以其丢掉的某些属性可能正好包含了重要的分类信息 2. PCA原理 条件1:给定一个m*n ...
- 主成分分析、实例及R语言原理实现
欢迎批评指正! 主成分分析(principal component analysis,PCA) 一.几何的角度理解PCA -- 举例:将原来的三维空间投影到方差最大且线性无关的两个方向(二维空间). ...
- [R语言] R语言PCA分析教程 Principal Component Methods in R
R语言PCA分析教程 Principal Component Methods in R(代码下载) 主成分分析Principal Component Methods(PCA)允许我们总结和可视化包含由 ...
- R语言数据分析系列六
R语言数据分析系列六 -- by comaple.zhang 上一节讲了R语言作图,本节来讲讲当你拿到一个数据集的时候怎样下手分析,数据分析的第一步.探索性数据分析. 统计量,即统计学里面关注的数据集 ...
- [译]用R语言做挖掘数据《六》
异常值检测 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到程序: ...
- 第六篇:R语言数据可视化之数据分布图(直方图、密度曲线、箱线图、等高线、2D密度图)
数据分布图简介 中医上讲看病四诊法为:望闻问切.而数据分析师分析数据的过程也有点相似,我们需要望:看看数据长什么样:闻:仔细分析数据是否合理:问:针对前两步工作搜集到的问题与业务方交流:切:结合业务方 ...
随机推荐
- 运行不出来真的QAQ
学C的时候最大的苦恼是编译不通过和运行不正确 学了C++之后就开始有编译过了但运行不出来的情况了TAT
- tp 获取器的使用中应该怎么append 自定义数据
$data = model('organization_area')->getListByNoPage($where, 'create_time asc');foreach ($data as ...
- 虚拟机VMware15的CentOS7.3的docker下安装Oracle11g
1.拉取镜像docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g 2.安装容器:docker run -d --name o ...
- 港湾云服务器 香港新世界 节点 centos7.7 64 部署java项目
开通云服务器 使用Xshell远程登录 XFTP连接服务器查看文件(这个步骤可有可无) yum安装jdk 在linux上使用yum安装是非常粗暴无脑的,但仍然有需要注意的点,不然会掉坑里.这里说一下步 ...
- Hyper-V 直连主机USB设备
因为授权问题不让用 Vmware 了.所以换成微软自带的 Hyper V 但是碰到一个很头痛的问题,就是外部设备没法像 Vmware 那样直接连接到虚拟机里面,很多第三方设备没法调试了. 找了很久终于 ...
- C# 高精度定时器
https://blog.gkarch.com/2015/09/high-resolution-timer.html https://www.cnblogs.com/samgk/articles/57 ...
- 【js】js执行机制-js单线程-同步和异步
js是单线程 即同一个时间只能做一件事,JavaScript是为处理页面中用户的交互,以及操作DOM而诞生的.比如我们对某个DOM元素进行添加和删除操作,不能同时进行.应该先进行添加,之后在进行删除. ...
- 【vue】数据代理
Object.defineProperty()方法 我们先来看几段代码 常用添加属性的方法,以添加age举例 ,点击查看代码 let person = { name: '张三', sex: '男', ...
- C/S 架构 和 B/S 架构
C/S架构的理解: 官方称:clinet-server 客户端需要下载的软件: 今日头条,爱奇艺等 能在手机和浏览器打开的软件 B/S架构的理解: 官方称:web-server 客户端为浏览器的: ...
- SQL的分类
DDL: 数据定义语言,用来定义数据库对象(数据表,表 ,字段) : DML:数据操作语言,用来对数据库表中的数据进行增删改 : DQL:数据库查询语言,用来查询数据库中的表的记录 DCL:数据控制语 ...