Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads 论文解读(VLDB 2021)
Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads 论文解读(VLDB 2021)
- 本篇博客是对发表在2021 VLDB上的# Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads的解读,原文链接为Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads (acm.org)
- 本文介绍了一种不受查询负载倾斜和数据相关性影响的基于学习的索引结构。
- 特点:
- 介绍了传统的多维索引结构(K-D树)、最近提出的基于学习的多维索引(FLOOD)和本文提出的多维索引结构(Tsunami)。
- 本文提出的索引结构可以基于数据和查询负载对索引结构进行调整,使之更加适用于当前的查询负载(传统的索引值是基于数据进行索引的构建)。
- 解决了目前基于学习的索引对于倾斜的查询负载和数据相关性强情景下的实效问题。
过滤表达式与索引
基于谓词过滤是任何现代数据库最基本的操作之一,加速过滤器表达式的执行可以显著提高数据库查询优化器的效率。过去常用的提高过滤效率的方法包括:聚集索引、多维索引及二级索引(选择度较高时)。但这些传统索引方法都难以调节,而且表现极不稳定。后续会
基于学习的多维索引方法(FLOOD,后文介绍)可以根据数据集和工作负载自动优化索引结构。但是对查询倾斜和数据相关度高的数据效果不是很乐观。
传统多维索引
k-d树
一种二叉空间分割树。在每个节点上基于不同维度的中值划分,直到每个叶子节点的点数少于一页的存储范围。每个叶子节点区域的点个数大致相等 如下图
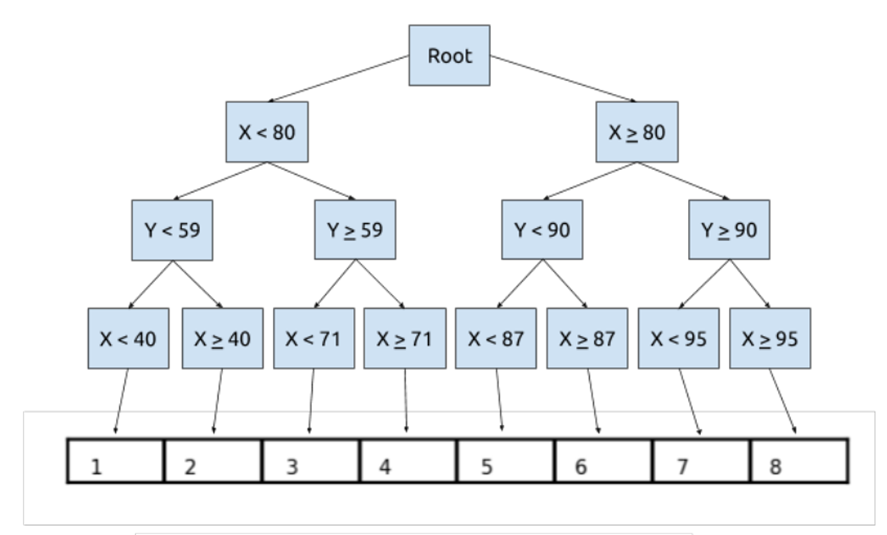
k-d树缺点:只基于数据进行构建,没有考虑查询负载,有可能划分的大部分索引点都不会有查询经过造成大量空间的浪费。
二级索引
- 二级索引:叶子节点中存储主键值,每次查找数据时,根据索引找到叶子节点中的主键值,根据主键值再到聚簇索引中得到完整的一行记录。
- 缺点:占据空间过大。适用于选择度比较大的属性,否则空间代价过大且无用。
传统多维索引缺点:
- 索引结构难以调整,需要在创建索引时仔细选择需要用到的维度以及索引的顺序,每当数据或工作负载发生变化就要重新维护索引。
- 没有一种索引模式可以概况所有情况的索引。
基于学习的索引
FLOOD
workflow:输入一个n维数据->CDF->divide into n partitions->n dimension grid->storage
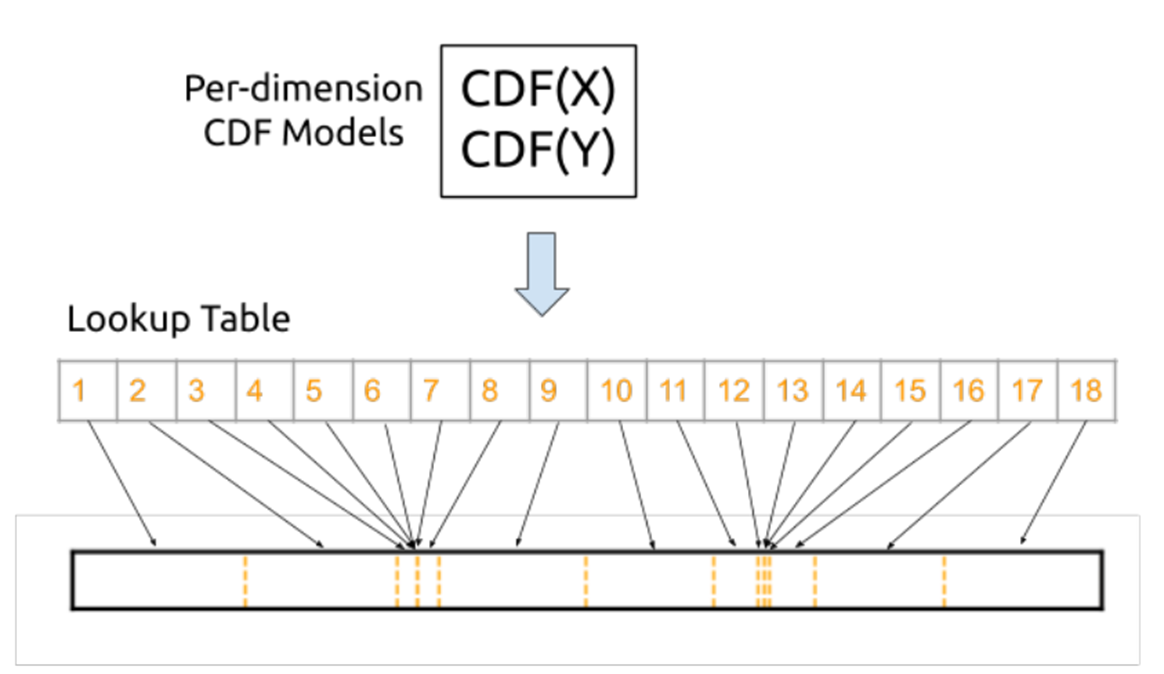
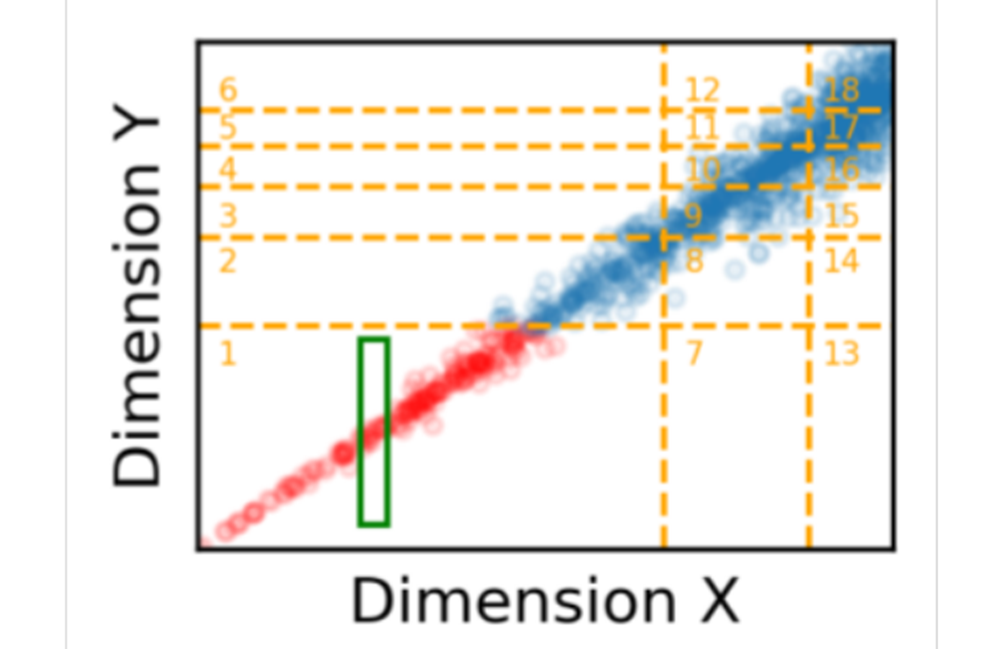
CDF:概率密度函数;根据CDF将每个维度分割成等量的k个部分(k是学习来的);n维数据,每个维度分成\(k_i\)个部分,互相交叉形成包括\(\prod_{k_i}\)个单元格的网格,每个单元格中包括满足各个属性范围的数据点。每个网格中的数据点都是连续存储的。
FLOOD优点:
- 可以根据查询负载动态的调整网格大小
- CDF模型对存储空间的消耗远远小于树形结构
FLOOD不足:
- FLOOD只参考平均查询频率来调整网格大小,当查询负载倾斜或查询不一致时,效率会大大降低。
- 当数据相关密切时,会导致各个单元格中的数据量差异较大,会降低索引的性能和存储空间使用率。
TSUNAMI
Tsunami的提出主要是为了解决FLOOD中对倾斜查询负载和处理相关数据时的效率下降问题。
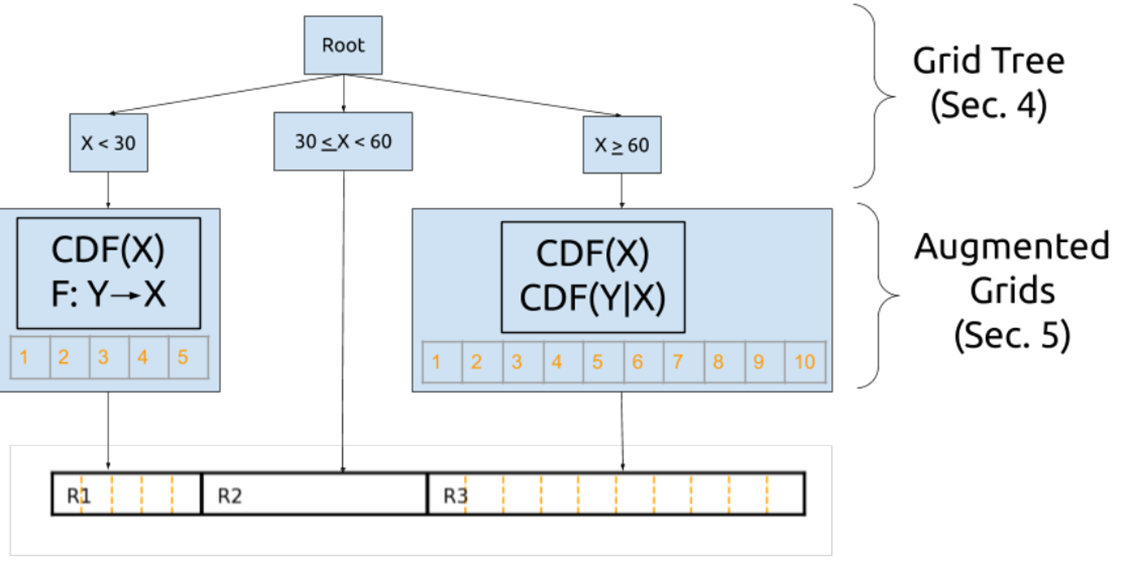
- 针对FLOOD对倾斜负载查询的不稳定性,Tsunami采用网格树的模式进行解决。
- 当查询特征在数据空间的不同部分有所不同,查询工作负载就会发生倾斜。解决方案:利用网格树将一个维度按查询分成多个不重合的部分
- 针对FLOOD对相关数据的不稳定性,Tsunami采用了增强网格进行解决。
- 基本想法与FLOOD基本一致。不同的是划分网格的依据。
(1)将当前属性视为独立属性,根据CDF(x)均匀分割
(2)如果X,Y存在单调映射,可以利用Y的过滤结果代替X的过滤结果
(3)用CDF(x|y)做均匀分割
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
觉得有帮助的话给笔者点个赞吧!O(∩_∩)O
- 基本想法与FLOOD基本一致。不同的是划分网格的依据。
Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads 论文解读(VLDB 2021)的更多相关文章
- 论文解读 - Composition Based Multi Relational Graph Convolutional Networks
1 简介 随着图卷积神经网络在近年来的不断发展,其对于图结构数据的建模能力愈发强大.然而现阶段的工作大多针对简单无向图或者异质图的表示学习,对图中边存在方向和类型的特殊图----多关系图(Multi- ...
- MySQL: Building the best INDEX for a given SELECT
Table of Contents The ProblemAlgorithmDigressionFirst, some examplesAlgorithm, Step 1 (WHERE "c ...
- 1229【MySQL】性能优化之 Index Condition Pushdown
转自http://blog.itpub.net/22664653/viewspace-1210844/ [MySQL]性能优化之 Index Condition Pushdown2014-07-06 ...
- T-SQL Recipes之Index Defragmentation
The Problem 索引一直是优化查询性能的不二法门.其中一个最直接的问题便是当审查一个低性能查询语句时,检查索引是否在正确的地方或者加索引没有.运行一个batchjob查看索引碎片,必要时采取步 ...
- Index on DB2 for z/OS: DB2 for z/OS 的索引
可以创建在任何表上的索引: Unique Index:An index that ensures that the value in a particular column or set of col ...
- Unable to handle 'index' format version '2', please update rosdistro的解决办法
之前安装的ROS是Fuerte版本的,好久没有更新,不知不觉又出来了好几个新的版本,今天删除了Fuerte,计划安装Hydro版本的尝尝新,按照官网的安装流程,很快就可以把新版本安装上去了,但是在&q ...
- elementui el-upload 在v-for里使用时 如何获取index
<div v-for = 'item in list'> <div @click="getImageTypeIndex(index)"> <el-up ...
- MySQL 执行计划中Extra(Using where,Using index,Using index condition,Using index,Using where)的浅析
关于如何理解MySQL执行计划中Extra列的Using where.Using Index.Using index condition,Using index,Using where这四者的区别 ...
- MySQL ICP(Index Condition Pushdown)特性
一.SQL的where条件提取规则 在ICP(Index Condition Pushdown,索引条件下推)特性之前,必须先搞明白根据何登成大神总结出一套放置于所有SQL语句而皆准的where查询条 ...
随机推荐
- redirect route 路由传参
return redirect()->route('exams.sign',['token'=>$token,'id'=>$result['id']]); // 签到页面 Route ...
- Semantic Text Similarity
stop word是指像the,is ,are等等方向的词 stemming意思就是将形式化为一样的形式,比如lists,listed,list都可以化为list形式.
- MM32F0020 UART1空闲中断接收
目录: 1.MM32F0020简介 2.初始化MM32F0020 UART1空闲中断和NVIC中断 3.编写MM32F0020 UART1中断接收和空闲中断函数 4.编写MM32F0020 UART1 ...
- CF802O题解
太厉害啦,出题人究竟是怎么想到的. 首先这题很显然可以使用费用流:对于 \(i \leq j\),连接一条边 \((i,j+n)\),流量为 \(1\),费用为 \(a_i+b_j\).最后连接 \( ...
- CF437C题解
思路很妙/youl 题目大意见翻译,说得很清楚/youl 首先,这个图到最后所有点都会被删除,所以所有边都会被删除. 但是考虑点的贡献会很麻烦,所以在这里我们考虑边的贡献. 边的贡献就是,左端点和右端 ...
- VuePress 博客优化之增加 Vssue 评论功能
前言 在 <一篇带你用 VuePress + Github Pages 搭建博客>中,我们使用 VuePress 搭建了一个博客,最终的效果查看:TypeScript 中文文档. 本篇讲讲 ...
- python 关于heapq模块的随笔
heapq模块提供了很多高级功能可以通过help(heapq)查看详细文档: 要点: 1优先级队列让我们可以按照重要程度来处理元素,而不是先进先出 2使用heapq可以应对长列表,因为heap不是复杂 ...
- Tomcat高级配置(应用场景总结及示例)
前言 本文将解决以下问题: 如何将Linux下任意位置的项目(虚拟目录)部署到tomcat? 如何将项目部署到服务器特定端口? 如何在一个服务器上部署多个web应用? 本例中 系统:Linux ver ...
- java案例—遍历字符串
/*案例:遍历并打印字符串 需求:键盘录入一个字符串,使用程序在控制台遍历该字符串 分析:1.使用Scanner类获取输入的字符串 2.使用public char charAt(int index)方 ...
- 关于 Linux Polkit 权限提升漏洞(CVE-2021-4034)的修复方法
镜像下载.域名解析.时间同步请点击阿里云开源镜像站 近日,国外安全团队披露了 Polkit 中的 pkexec 组件存在的本地权限提升漏洞(CVE-2021-4034),Polkit 默认安装在各个主 ...