2022!影响百万用户金融信用评分,Equifax被告上法庭,罪魁祸首——『数据漂移』!⛵

作者:韩信子@ShowMeAI
数据分析实战系列:https://www.showmeai.tech/tutorials/40
机器学习实战系列:https://www.showmeai.tech/tutorials/41
本文地址:https://www.showmeai.tech/article-detail/331
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
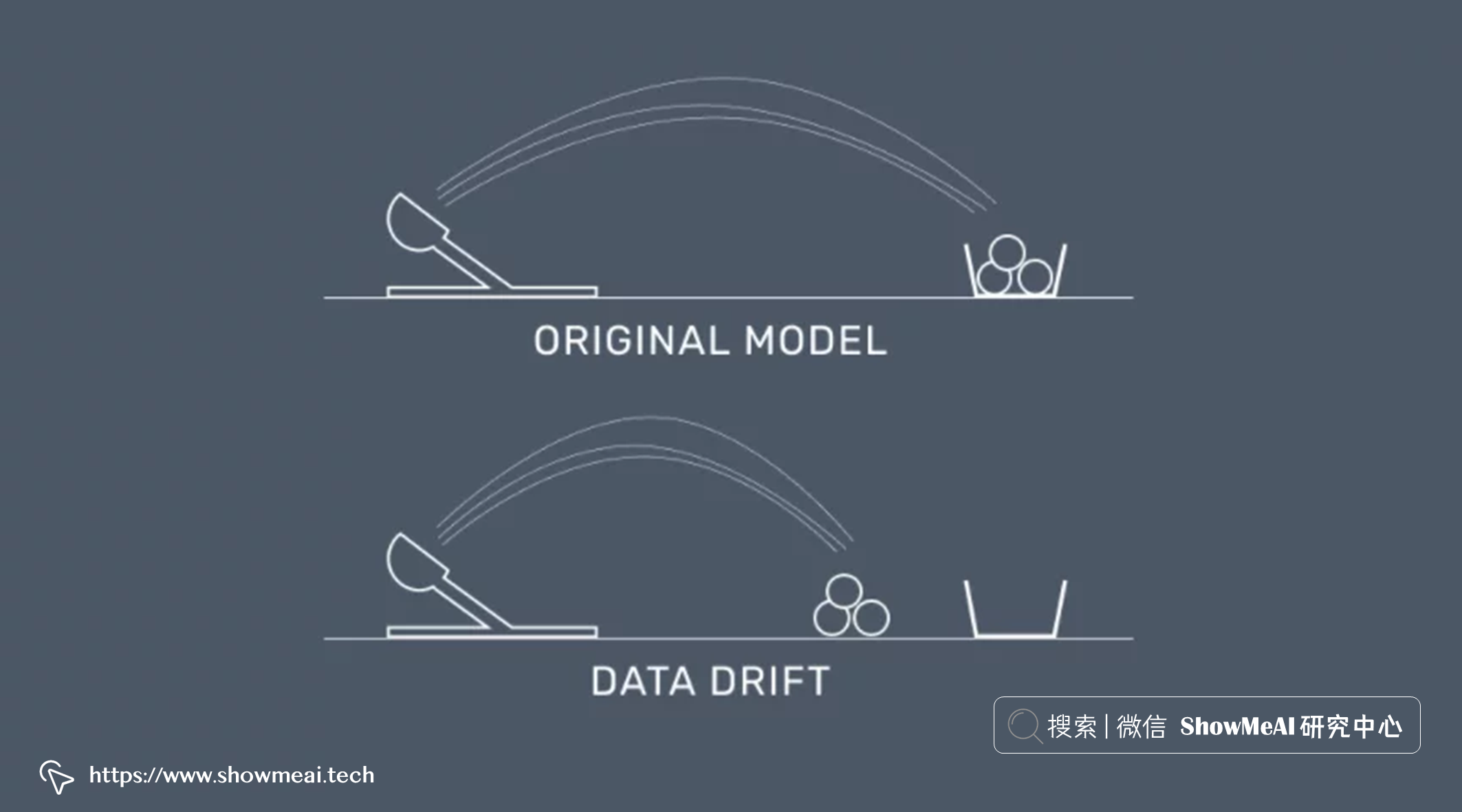
数据漂移
The Only Constant in Life Is Change. 世界上唯一不变的就是变化本身。
这是一句来自希腊的哲学家赫拉克利特写的话,它很简单但却道出了世界的真理之一。在数据科学与机器学习领域,这句话同样是非常有意义的,在生产中部署机器学习模型的许多实际应用中,数据通常会随着时间的推移而变化,因此之前构建的模型会随着时间的推移而变得不准确,效果大打折扣,这就是典型的数据漂移问题。
真实案例
2022年3月17日至4月6日,信用报告机构 Equifax 的系统出现问题,导致 信用评分不正确,影响到百万级别的消费者,并导致了针对公司的法律索赔和集体诉讼,业内专家称,这个问题的根源就是数据漂移。

数据漂移
何为数据漂移
当我们在使用数据科学方法解决场景问题时,得到方案之后,在实际生产环境中,如果我们拿到的实时预测数据,分布与用于训练模型的训练数据分布有差异时,就发生了『数据漂移』,而它的后果就是预估不再准确,效果下降甚至直接影响公司的收益。
简单的例子,例如用『口罩政策』之前的互联网数据建模,对『口罩政策』实施时的用户行为预估,那一定会有偏差;又如我们用日常数据建模,构建电商推荐系统,在 618 和双11当天预测,可能也会有偏差,模型效果下降。
训练数据和生产数据之间的差异可能是由多种因素造成的。可能本来使用的训练数据就不合适。

例如,如果使用美国道路数据集训练和检测道路状况,应用在中国的道路上,效果就会差非常多,这也是明显的数据漂移。
现代互联网时代,没分每秒都迅速产生海量大数据,我们的数据源呈现爆炸式增长也更容易会有变化。我们并不能每次都提前预判到『数据漂移』问题,甚至有时候我们会遇到特殊的网络攻击,基于『数据漂移』的知识进行调整和切换攻击方式。

例如,我们基于历史数据构建了效果非常良好的垃圾邮件检测功能,但攻击者可能在某个时候改变发送垃圾邮件的行为,因为送入模型的数据发生了变化,我们原本构建的模型可能真的会被『欺骗』。
因此,很重要的是,我们需要有一套比对和检测的机制,可以及时发现『数据漂移』,并对其进行处理。
检测方法概述
有很多数据漂移的检测方法,最简单的方式是基于统计方法来比较『训练数据』(称为基线或参考)和『实时数据』(生产数据)的分布,如果两个分布之间有着显着差异,我们就判断为发生数据漂移。
最流行的统计检验方法包括 Kolmogorov-Smirnov 检验、卡方检验、 Jensen-Shannon 散度、 Wasserstein 距离。 另一类方法是使用机器学习模型来监控数据质量。 我们也可以把两类方法混合使用。
实际生产环境中,统计的方法使用得很多,它们简单且有很不错的效果。下面 ShowMeAI 就基于代码告诉大家如何进行『数据漂移』检测。
代码实现
数据漂移检测
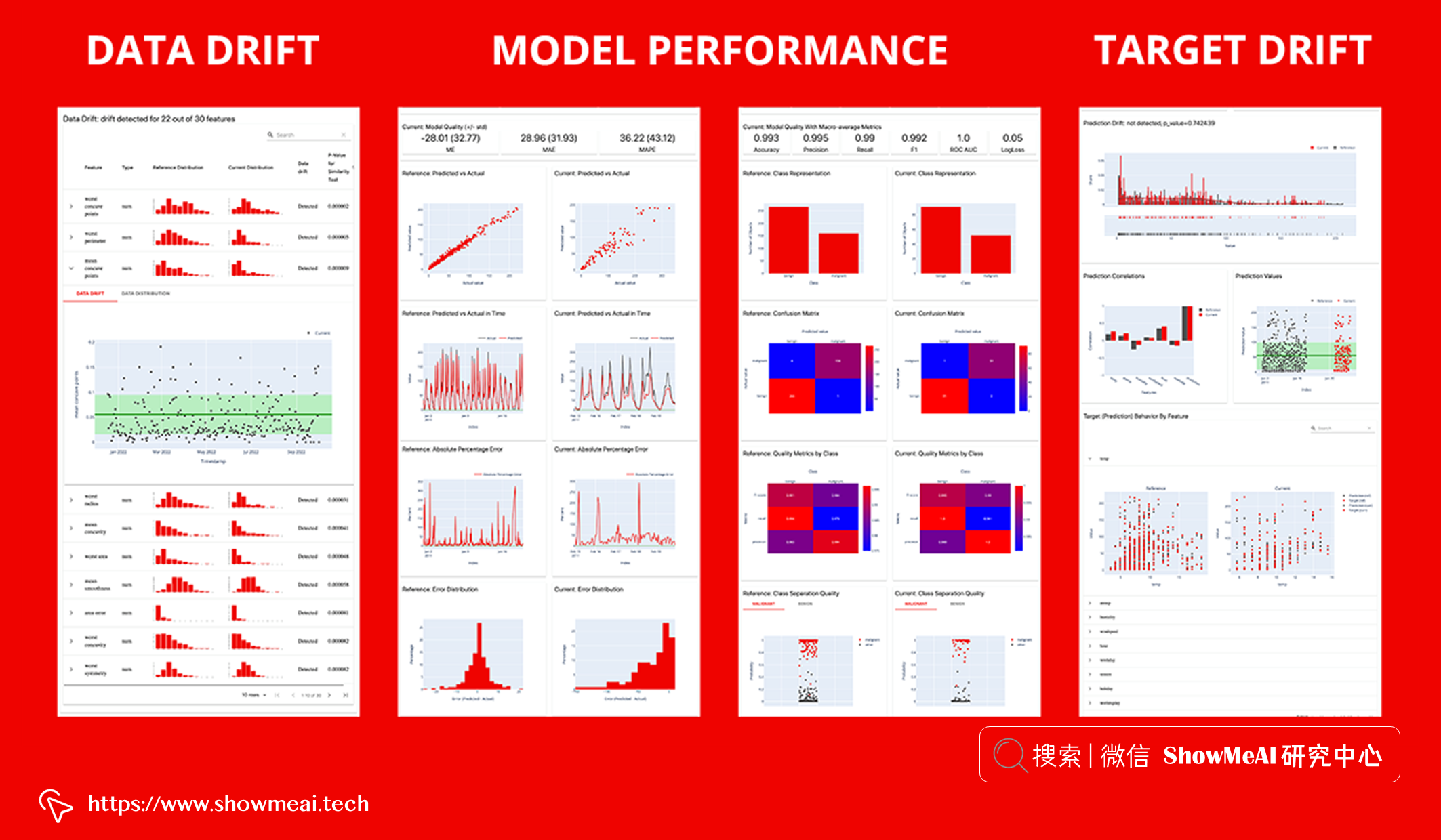
我们在这里会使用到 evidently 这个非常简单易用的工具库,它是一个专门针对『数据漂移』问题构建的工具库,可以对数据 / 标签 / 模型表现等进行检测,不仅可以输出报告,还可以启动实时看板监控。
下面导入工具库
import pandas as pd
from sklearn import datasets
from evidently.dashboard import Dashboard
from evidently.dashboard.tabs import DataDriftTab, CatTargetDriftTab
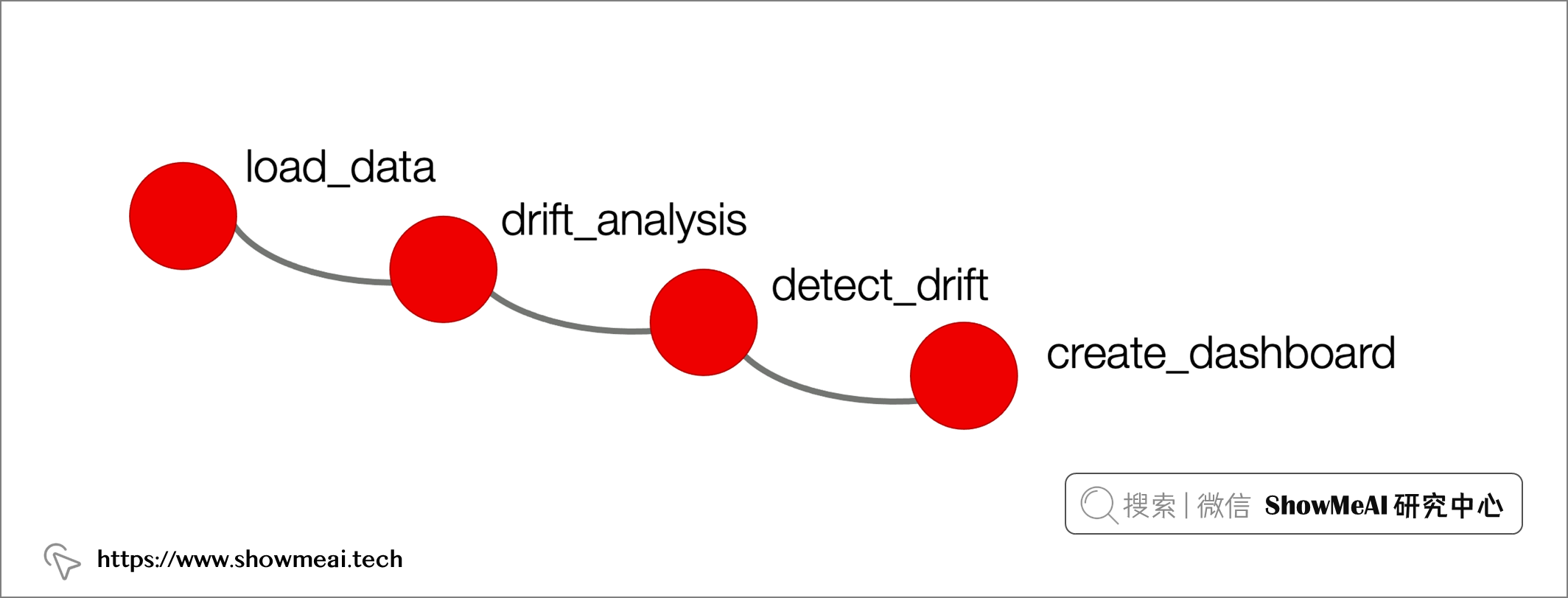
evidently的使用步骤如下,我们会先加载数据,然后做漂移分析和检测,最后可以构建看板进行分析结果的呈现。
我们使用sklearn自带的 iris 数据集作为示例来给大家讲解,我们把对应的数据和标签读取出来。
iris = datasets.load_iris()
iris_frame = pd.DataFrame(iris.data, columns = iris.feature_names)
iris_frame['target'] = iris.target
我们把完整的数据集切分为训练集和测试集,对其进行对比和数据漂移分析,最后构建仪表盘看板:
iris_data_drift_report = Dashboard(tabs=[DataDriftTab(verbose_level=verbose),
CatTargetDriftTab(verbose_level=verbose)])
iris_data_drift_report.calculate(iris_frame[:75], iris_frame[-new_samples:], column_mapping = None)
iris_data_drift_report.show(mode="inline")
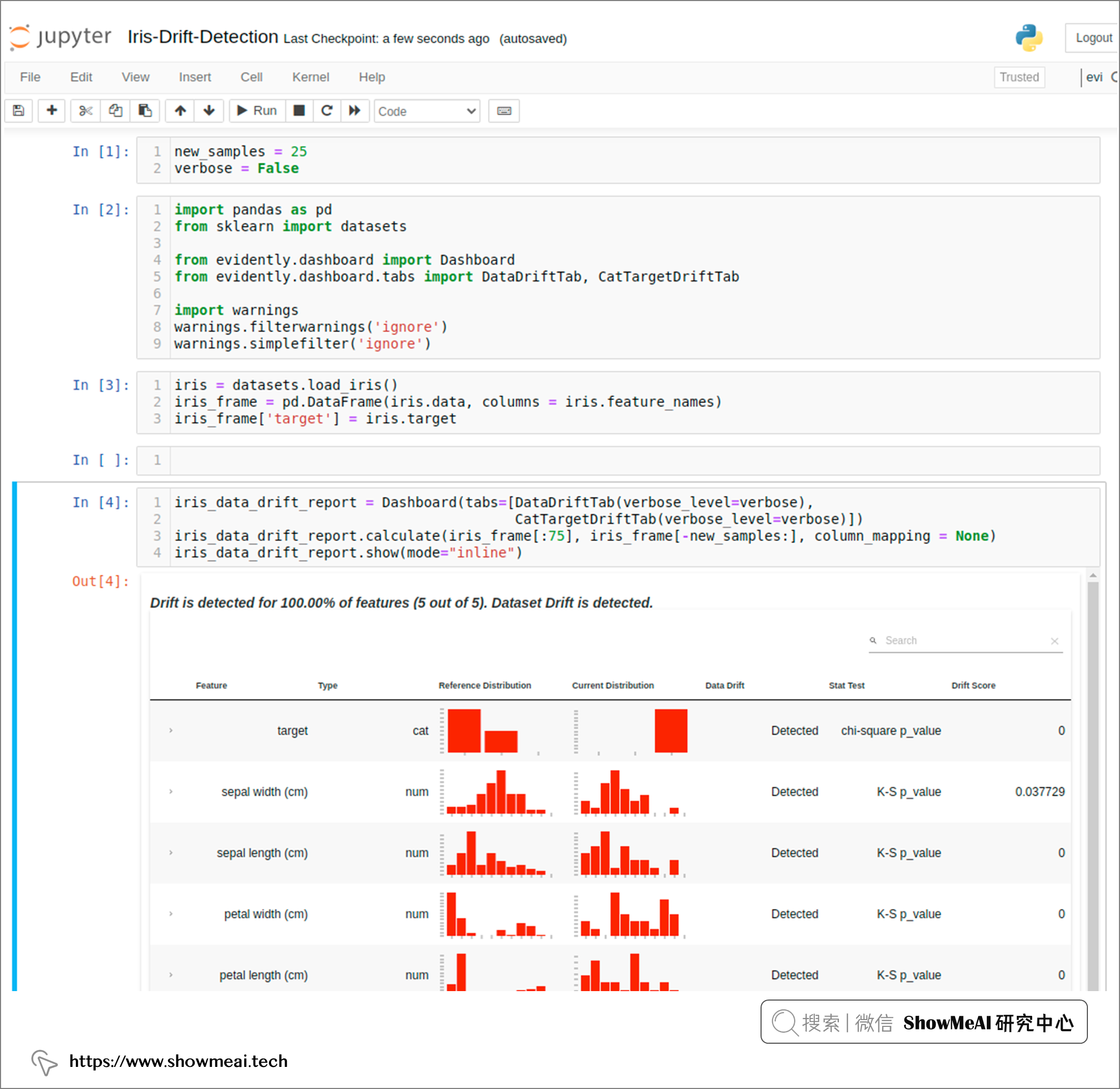
注意到参数verbose,它是布尔值,用于控制显示仪表板的详细程度。 上述代码中我们设置为 False,会得到一个报告如下,里面详细分析了训练集和测试集的『特征字段』和『标签』的分布差异情况:
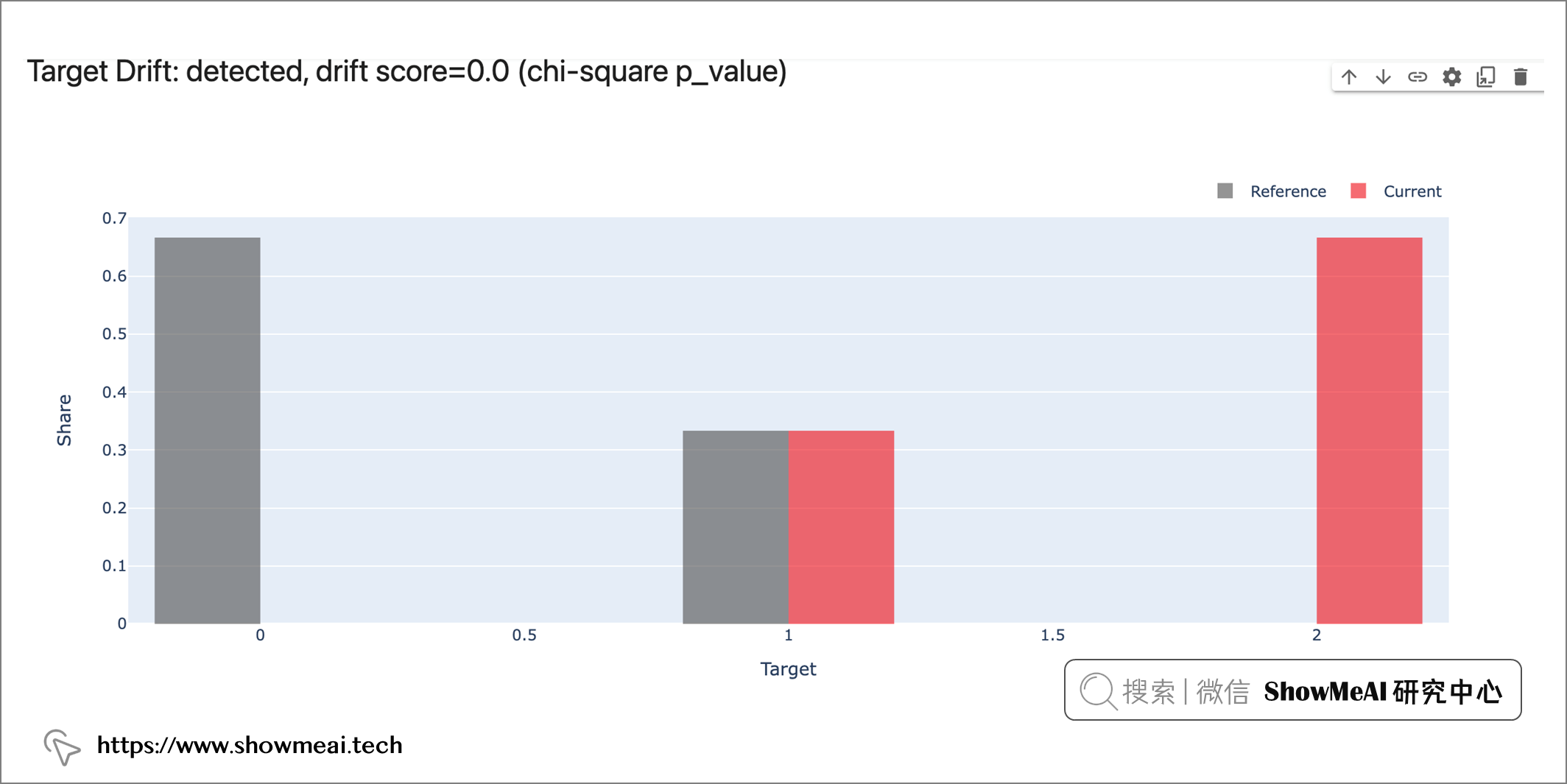
我们也可以通过下列代码去打开看板和存储html报告。
iris_target_drift_dashboard.show()
iris_target_drift_dashboard.save('iris_target_drift.html')
参考资料
- Equifax issued wrong credit scores for millions of consumers:https://www.cnn.com/2022/08/03/business/equifax-wrong-credit-scores/index.html
- Kolmogorov-Smirnov 检验:https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test
- 卡方检验:https://en.wikipedia.org/wiki/Chi-squared_test
- Jensen-Shannon 散度:https://en.wikipedia.org/wiki/Jensen%E2%80%93Shannon_divergence
- Wasserstein 距离:https://en.wikipedia.org/wiki/Wasserstein_metric
2022!影响百万用户金融信用评分,Equifax被告上法庭,罪魁祸首——『数据漂移』!⛵的更多相关文章
- 【机器学习PAI实践十二】机器学习算法基于信用卡消费记录做信用评分
背景 如果你是做互联网金融的,那么一定听说过评分卡.评分卡是信用风险评估领域常用的建模方法,评分卡并不简单对应于某一种机器学习算法,而是一种通用的建模框架,将原始数据通过分箱后进行特征工程变换,继而应 ...
- MongoDB的真正性能-实战百万用户
阅读目录 一.第一个问题:Key-Value数据库可以有好多的Key,没错,但对MongoDB来说,大错特错 二.第二个问题:FindOne({_id:xxx})就快么? 三.第三个问题:精细的使用U ...
- 笔记︱金融风险控制基础常识——巴塞尔协议+信用评分卡Fico信用分
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记源于CDA-DSC课程,由常国珍老师主讲 ...
- 3分钟搞明白信用评分卡模型&模型验证
信用评分卡模型在国外是一种成熟的预测方法,尤其在信用风险评估以及金融风险控制领域更是得到了比较广泛的使用,其原理是将模型变量WOE编码方式离散化之后运用logistic回归模型进行的一种二分类变量的广 ...
- WOE:信用评分卡模型中的变量离散化方法(生存分析)
WOE:信用评分卡模型中的变量离散化方法 2016-03-21 生存分析 在做回归模型时,因临床需要常常需要对连续性的变量离散化,诸如年龄,分为老.中.青三组,一般的做法是ROC或者X-tile等等. ...
- 信用评分卡Credit Scorecards (1-7)
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 python风控评分卡建模和风控常识 https://study.163.com/course/introductio ...
- 评分模型的检验方法和标准&信用评分及实现
评分模型的检验方法和标准通常有:K-S指标.交换曲线.AR值.Gini数等.例如,K-S指标是用来衡量验证结果是否优于期望值,具体标准为:如果K-S大于40%,模型具有较好的预测功能,发展的模型具有成 ...
- 逻辑回归原理_挑战者飞船事故和乳腺癌案例_Python和R_信用评分卡(AAA推荐)
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
- 信用评分卡(A卡/B卡/C卡)的模型简介及开发流程|干货
https://blog.csdn.net/varyall/article/details/81173326 如今在银行.消费金融公司等各种贷款业务机构,普遍使用信用评分,对客户实行打分制,以期对客户 ...
- 信用评分卡 (part 7 of 7)
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...
随机推荐
- PHP代码审计——文件操作漏洞
梦想CMS(lmxcms)任意文件删除 1. 漏洞详情--CNVD-2020-59469 2. 漏洞描述称后台Ba***.cl***.php文件存在任意文件删除,查看cms源码,只有BackdbA ...
- KingbaseES 开启事务提交跟踪
KingbaseESV8R6有个参数 track_commit_timestamp,用来开启跟踪事务提交的时间戳. 配置 编辑kingbase.conf,添加配置如下: track_commit_ti ...
- re.sub()用法
原文链接:https://blog.csdn.net/jackandsnow/article/details/103885422
- 若依代码生成的一个大坑 You have an error in your SQL syntax; check the manual that corresponds to your MySQL s
报错如下所示:显示我的xml文件的SQL语句有错 ### Error querying database. Cause: java.sql.SQLSyntaxErrorException: You h ...
- 《!--suppress ALL --> 在Android XML 文件中的用途是什么?
<!--suppress ALL --> 在Android XML 文件中的用途是什么? 警告一次又一次地出现在谷歌地图的 XML 文件中,但是当我使用时,所有警告都被禁用.那么压制所有评 ...
- C#,根据路径获取某个数字开头的所有文件夹,并获取最新文件夹进行替换文件
项目需求获取某路径下为1开头文件夹,并替换最新文件夹内容,话不多说,上代码 private void Form1_Load(object sender, EventArgs e) { try { st ...
- 我的Go gRPC之旅、01 初识gRPC,感受gRPC的强大魅力
微服务架构 微服务是一种开发软件的架构和组织方法,其中软件由通过明确定义的API 进行通信的小型独立服务组成. 这些服务由各个小型独立团队负责. 微服务架构使应用程序更易于扩展和更快地开发,从而加速创 ...
- 《吐血整理》高级系列教程-吃透Fiddler抓包教程(22)-如何使用Fiddler生成Jmeter脚本-下篇
1.简介 今天这篇文章其实和上一篇差不多也是利用一个fiddler的插件进行Jmeter脚本的导出,开始宏哥想要合在一起写一篇文章,可是结果实践的时候,两个插件还是有区别的,因此为了不绕晕小伙伴或者童 ...
- Grafana Loki 架构
转载自:https://mp.weixin.qq.com/s?__biz=MzU4MjQ0MTU4Ng==&mid=2247492186&idx=2&sn=a06954384a ...
- filebeat测试output连通性
在默认的情况下,直接运行filebeat的话,它选择的默认的配置文件是当前目录下的filebeat.yml文件. filebeat.yml文件内容 filebeat.inputs: - type: l ...