Citus 分布式 PostgreSQL 集群 - SQL Reference(查询处理)
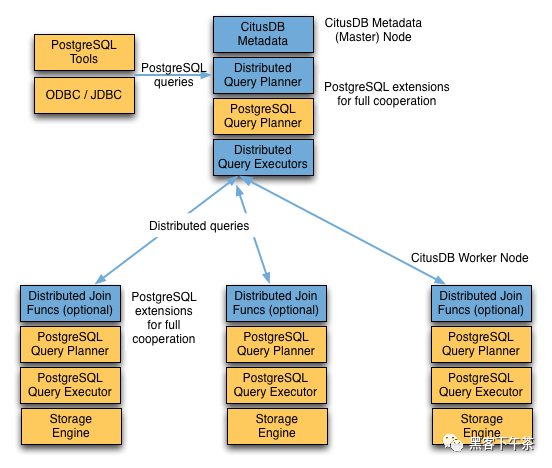
一个 Citus 集群由一个 coordinator 实例和多个 worker 实例组成。 数据在 worker 上进行分片和复制,而 coordinator 存储有关这些分片的元数据。向集群发出的所有查询都通过 coordinator 执行。 coordinator 将查询划分为更小的查询片段,其中每个查询片段可以在分片上独立运行。然后协调器将查询片段分配给 worker,监督他们的执行,合并他们的结果,并将最终结果返回给用户。 查询处理架构可以通过下图进行简要描述。
Citus 的查询处理管道涉及两个组件:
- 分布式查询计划器和执行器
- PostgreSQL 计划器和执行器
我们将在后续部分中更详细地讨论它们。
分布式查询计划器
Citus 的分布式查询计划器接收 SQL 查询并规划它以进行分布式执行。
对于 SELECT 查询,计划器首先创建输入查询的计划树,并将其转换为可交换和关联形式,以便可以并行化。 它还应用了一些优化以确保以可扩展的方式执行查询,并最大限度地减少网络 I/O。
接下来,计划器将查询分为两部分 - 在 coordinator 上运行的 coordinator 查询和在 worker 上的各个分片上运行的 worker 查询片段。 然后,计划器将这些查询片段分配给 worker,以便有效地使用他们的所有资源。 在这一步之后,分布式查询计划被传递给分布式执行器执行。
分布列上的键值查找或修改查询的规划过程略有不同,因为它们恰好命中一个分片。一旦计划器收到传入的查询,它需要决定查询应该路由到的正确分片。 为此,它提取传入行中的分布列并查找元数据以确定查询的正确分片。 然后,计划器重写该命令的 SQL 以引用分片表而不是原始表。 然后将该重写的计划传递给分布式执行器。
分布式查询执行器
Citus 的分布式执行器运行分布式查询计划并处理故障。 执行器非常适合快速响应涉及过滤器、聚合和共置连接的查询,以及运行具有完整 SQL 覆盖的单租户查询。它根据需要为每个分片打开一个与 woker 的连接,并将所有片段查询发送给他们。 然后它从每个片段查询中获取结果,合并它们,并将最终结果返回给用户。
子查询/CTE Push-Pull 执行
如有必要,Citus 可以将来自子查询和 CTE 的结果收集到 coordinator 节点中,然后将它们推送回 worker 以供外部查询使用。这允许 Citus 支持更多种类的 SQL 构造。
例如,在 WHERE 子句中包含子查询有时不能与主查询同时执行内联,而必须单独执行。假设 Web 分析应用程序维护一个按 page_id 分区的 page_views 表。要查询前 20 个访问量最大的页面上的访问者主机数,我们可以使用子查询来查找页面列表,然后使用外部查询来计算主机数。
SELECT page_id, count(distinct host_ip)
FROM page_views
WHERE page_id IN (
SELECT page_id
FROM page_views
GROUP BY page_id
ORDER BY count(*) DESC
LIMIT 20
)
GROUP BY page_id;
执行器希望通过 page_id 对每个分片运行此查询的片段,计算不同的 host_ips,并在 coordinator 上组合结果。但是,子查询中的 LIMIT 意味着子查询不能作为片段的一部分执行。通过递归规划查询,Citus 可以单独运行子查询,将结果推送给所有 worker,运行主片段查询,并将结果拉回 coordinator。 push-pull(推拉) 设计支持上述子查询。
让我们通过查看此查询的 EXPLAIN 输出来了解这一点。它相当参与:
GroupAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: remote_scan.page_id
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
-> Distributed Subplan 6_1
-> Limit (cost=0.00..0.00 rows=0 width=0)
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: COALESCE((pg_catalog.sum((COALESCE((pg_catalog.sum(remote_scan.worker_column_2))::bigint, '0'::bigint))))::bigint, '0'::bigint) DESC
-> HashAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=54.70..56.70 rows=200 width=12)
Group Key: page_id
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=4)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=84.50..86.75 rows=225 width=36)
Group Key: page_views.page_id, page_views.host_ip
-> Hash Join (cost=17.00..78.88 rows=1124 width=36)
Hash Cond: (page_views.page_id = intermediate_result.page_id)
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=36)
-> Hash (cost=14.50..14.50 rows=200 width=4)
-> HashAggregate (cost=12.50..14.50 rows=200 width=4)
Group Key: intermediate_result.page_id
-> Function Scan on read_intermediate_result intermediate_result (cost=0.00..10.00 rows=1000 width=4)
让我们把它拆开并检查每一块。
GroupAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: remote_scan.page_id
树的 root 是 coordinator 节点对 worker 的结果所做的事情。 在这种情况下,它正在对它们进行分组,并且 GroupAggregate 要求首先对它们进行排序。
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
-> Distributed Subplan 6_1
.
自定义扫描有两个大子树,从“分布式子计划”开始。
-> Limit (cost=0.00..0.00 rows=0 width=0)
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: COALESCE((pg_catalog.sum((COALESCE((pg_catalog.sum(remote_scan.worker_column_2))::bigint, '0'::bigint))))::bigint, '0'::bigint) DESC
-> HashAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=54.70..56.70 rows=200 width=12)
Group Key: page_id
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=4)
.
工作节点为 32 个分片中的每一个运行上述内容(Citus 正在选择一个代表进行显示)。 我们可以识别 IN (...) 子查询的所有部分:排序、分组和限制。 当所有 worker 完成此查询后,他们会将其输出发送回 coordinator,coordinator 将其组合为“中间结果”。
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=84.50..86.75 rows=225 width=36)
Group Key: page_views.page_id, page_views.host_ip
-> Hash Join (cost=17.00..78.88 rows=1124 width=36)
Hash Cond: (page_views.page_id = intermediate_result.page_id)
.
Citus 在第二个子树中启动另一个执行器作业。它将在 page_views 中计算不同的主机。 它使用 JOIN 连接中间结果。中间结果将帮助它限制在前二十页。
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=36)
-> Hash (cost=14.50..14.50 rows=200 width=4)
-> HashAggregate (cost=12.50..14.50 rows=200 width=4)
Group Key: intermediate_result.page_id
-> Function Scan on read_intermediate_result intermediate_result (cost=0.00..10.00 rows=1000 width=4)
.
工作人员使用 read_intermediate_result 函数在内部检索中间结果,该函数从 coordinator 节点复制的文件中加载数据。
这个例子展示了 Citus 如何使用分布式子计划在多个步骤中执行查询,以及如何使用 EXPLAIN 来了解分布式查询执行。
PostgreSQL 计划器和执行器
一旦分布式执行器将查询片段发送给 worker,它们就会像常规 PostgreSQL 查询一样被处理。 该 worker 上的 PostgreSQL 计划程序选择在相应分片表上本地执行该查询的最佳计划。 PostgreSQL 执行器然后运行该查询并将查询结果返回给分布式执行器。您可以从 PostgreSQL 手册中了解有关 PostgreSQL 计划器和执行器的更多信息。最后,分布式执行器将结果传递给 coordinator 进行最终聚合。
- 计划器
- 执行器
更多
- Citus 分布式 PostgreSQL 集群 - SQL Reference(创建和修改分布式表 DDL)
- Citus 分布式 PostgreSQL 集群 - SQL Reference(摄取、修改数据 DML)
- Citus 分布式 PostgreSQL 集群 - SQL Reference(查询分布式表 SQL)
Citus 分布式 PostgreSQL 集群 - SQL Reference(查询处理)的更多相关文章
- Citus 分布式 PostgreSQL 集群 - SQL Reference(查询分布式表 SQL)
如前几节所述,Citus 是一个扩展,它扩展了最新的 PostgreSQL 以进行分布式执行.这意味着您可以在 Citus 协调器上使用标准 PostgreSQL SELECT 查询进行查询. Cit ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(手动查询传播)
手动查询传播 当用户发出查询时,Citus coordinator 将其划分为更小的查询片段,其中每个查询片段可以在工作分片上独立运行.这允许 Citus 将每个查询分布在集群中. 但是,将查询划分为 ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(SQL支持和变通方案)
由于 Citus 通过扩展 PostgreSQL 提供分布式功能,因此它与 PostgreSQL 结构兼容.这意味着用户可以使用丰富且可扩展的 PostgreSQL 生态系统附带的工具和功能来处理使用 ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(摄取、修改数据 DML)
插入数据 要将数据插入分布式表,您可以使用标准 PostgreSQL INSERT 命令.例如,我们从 Github 存档数据集中随机选择两行. INSERT http://www.postgresq ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(创建和修改分布式表 DDL)
创建和分布表 要创建分布式表,您需要首先定义表 schema. 为此,您可以使用 CREATE TABLE 语句定义一个表,就像使用常规 PostgreSQL 表一样. CREATE TABLE ht ...
- 在 Kubernetes 上快速测试 Citus 分布式 PostgreSQL 集群(分布式表,共置,引用表,列存储)
准备工作 这里假设,你已经在 k8s 上部署好了基于 Citus 扩展的分布式 PostgreSQL 集群. 查看 Citus 集群(kubectl get po -n citus),1 个 Coor ...
- 分布式 PostgreSQL 集群(Citus),分布式表中的分布列选择最佳实践
确定应用程序类型 在 Citus 集群上运行高效查询要求数据在机器之间正确分布.这因应用程序类型及其查询模式而异. 大致上有两种应用程序在 Citus 上运行良好.数据建模的第一步是确定哪些应用程序类 ...
- 分布式 PostgreSQL 集群(Citus)官方安装指南
单节点 Citus Docker (Mac 与 Linux) Docker 镜像仅用于开发/测试目的, 并且尚未准备好用于生产用途. 您可以使用一个命令在 Docker 中启动 Citus: # st ...
- 分布式 PostgreSQL 集群(Citus)官方教程 - 迁移现有应用程序
将现有应用程序迁移到 Citus 有时需要调整 schema 和查询以获得最佳性能. Citus 扩展了 PostgreSQL 的分布式功能,但它不是扩展所有工作负载的直接替代品.高性能 Citus ...
随机推荐
- 【C# Task】开篇
概览 在学task类之前必须学习线程的知识. 以下是task命名空间的类的结构图 1.2种任务类型: 有返回值task<TResult> .无返回值task. 2.2座任务工厂 TaskF ...
- System.Console.WriteLine() 调用原理
1.System.Console.WriteLine(类的实例)默认调用类的Tostring()方法.如果自定义的新类未override ToString()方法.那么调用Object.ToStrin ...
- yapi安装 - windows
yapi官网https://hellosean1025.github.io/yapi/devops/index.html 简介 YApi 是高效.易用.功能强大的 api 管理平台,旨在为开发.产 ...
- Qt:QJsonObject
0.说明 QJsonObject在逻辑上就是一个Map或Dict!记住这一点对理解它的方法.说明很有帮助. QJsonObject类封装了JSON Object. JSON Object是一个Key- ...
- 错误try……except……else……finally 记录错误logging 抛出错误raise
1.错误处理机制 try--except--finally 格式: try: 可能出错的代码 except xxx1Error as e: 处理1 except xxx2Error as e: 处理2 ...
- 微服务入门二:SpringCloud(版本Hoxton SR6)
一.什么是SpringCloud 1.官方定义 1)官方定义:springcloud为开发人员提供了在分布式系统中快速构建一些通用模式的工具(例如配置管理.服务发现.断路器.智能路由.微代理.控制总线 ...
- 微信小程序发布列表页面处理
wxml: <!--pages/good_index/good_index.wxml--> <view class='list'> <block wx:for='{{in ...
- thinkphp 登录(未设置cookie+session)
<?php namespace app\Admin\controller; use think\Controller; use think\Loader; use think\Request; ...
- 理解并手写 bind() 函数
有了对call().apply()的前提分析,相信bind()我们也可以手到擒来. 参考前两篇:'对call()函数的分析' 和 '对apply()函数的分析',我们可以先得到以下代码: Functi ...
- iframe于iframe页面之间的函数相互调用
因为iframe页面于包括父页面在内的其他页面通讯有跨域问题,所以只有在服务器环境下或者火狐浏览器下才能测试. 在iframe页面调用父页面的函数采用parent,例子:在父页面有一个say()函数, ...