elasticsearch中使用runtime fields
1、背景
在我们使用es的开发过程中可能会遇到这么一种情况,比如我们的线路名称字段lineName字段在设置mapping的时候使用的是text类型,但是后期发现需要使用这个字段来进行聚合操作,那么我们除了对索引进行reindex操作外,还有什么办法可以解决这个问题呢?此处我们通过runtime field来解决。
2、runtime field介绍
2.1 runtime field可以实现的功能
运行时字段是在查询时评估的字段。是在es7.11之后增加的运行时字段使您能够:
- 将字段添加到现有文档,而无需重新索引数据
- 在不了解数据结构的情况下开始处理数据
- 在查询时覆盖从索引字段返回的值
- 定义特定用途的字段,而不修改原始mapping

2.2 runtime field优缺点
- runtime field是运行时增加的字段,不会被索引和存储,不会增加索引的大小。
- runtime field 可以像普通字段一样使用,可以进行
查询,排序,聚合等操作。 - 可以动态的添加字段。
- 可以在查询时覆盖字段的值。即
fields中和_source中可以返回同名的字段,但是值可能不一样。 - 阻止mapping爆炸,可以先使用后定义。
- 针对经常被搜索或聚合等操作的字段,不适合使用runtime field,而应该定义在mapping中。
- runtime field不会出现在
_source中,需要通过fields api来获取。
3、创建runtime field的方式
3.1 通过mapping的方式创建
3.1.1、添加runtime field
PUT /index_script_fields
{
"mappings": {
"runtime": {
"aggLineName": {
"type": "keyword",
"script": {
"source": "emit(doc['lineName'].value)"
}
}
},
"properties": {
"lineId": {
"type": "keyword"
},
"lineName": {
"type": "text"
}
}
}
}
3.1.2、更新 runtime field
POST /index_script_fields/_mapping
{
"runtime": {
"aggLineName": {
"type": "keyword",
"script": {
"source": "emit(doc['lineName'].value)"
}
}
}
}
3.1.3、删除runtime field
POST /index_script_fields/_mapping
{
"runtime": {
"aggLineName": null
}
}
3.2 通过search request定义runtime field
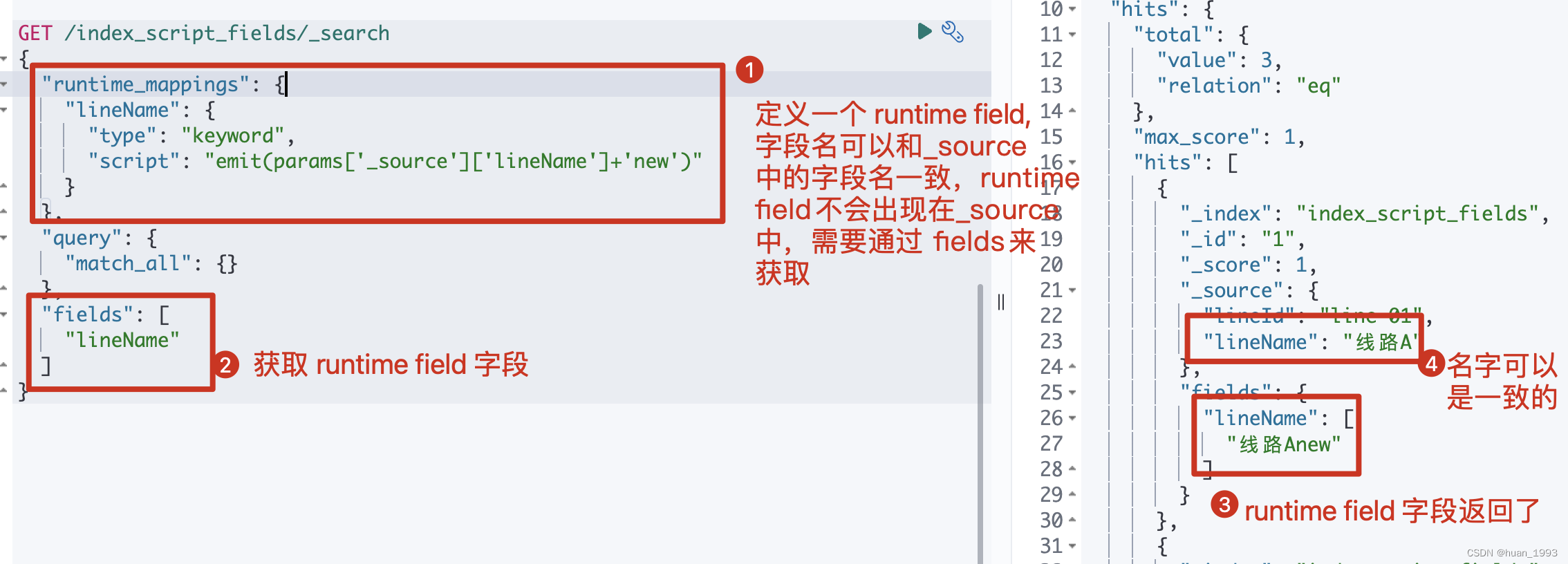
GET /index_script_fields/_search
{
"runtime_mappings": {
"lineName": {
"type": "keyword",
"script": "emit(params['_source']['lineName']+'new')"
}
},
"query": {
"match_all": {}
},
"fields": [
"lineName"
]
}
4、需求
我们存在一个线路mapping,其中lineName在设计的使用使用了text类型,现在我们需要根据这个字段来进行聚合操作,那么使用runtime field该如何操作呢?
5、实现
5.1 mapping
PUT /index_script_fields
{
"mappings": {
"properties": {
"lineId": {
"type": "keyword"
},
"lineName": {
"type": "text"
}
}
}
}
注意此时的lineName的类型是text
5.2 插入数据
PUT /index_script_fields/_bulk
{"index":{"_id":1}}
{"lineId":"line-01","lineName":"线路A"}
{"index":{"_id":2}}
{"lineId":"line-01","lineName":"线路A"}
{"index":{"_id":3}}
{"lineId":"line-02","lineName":"线路C"}
5.3、根据线路来进行聚合
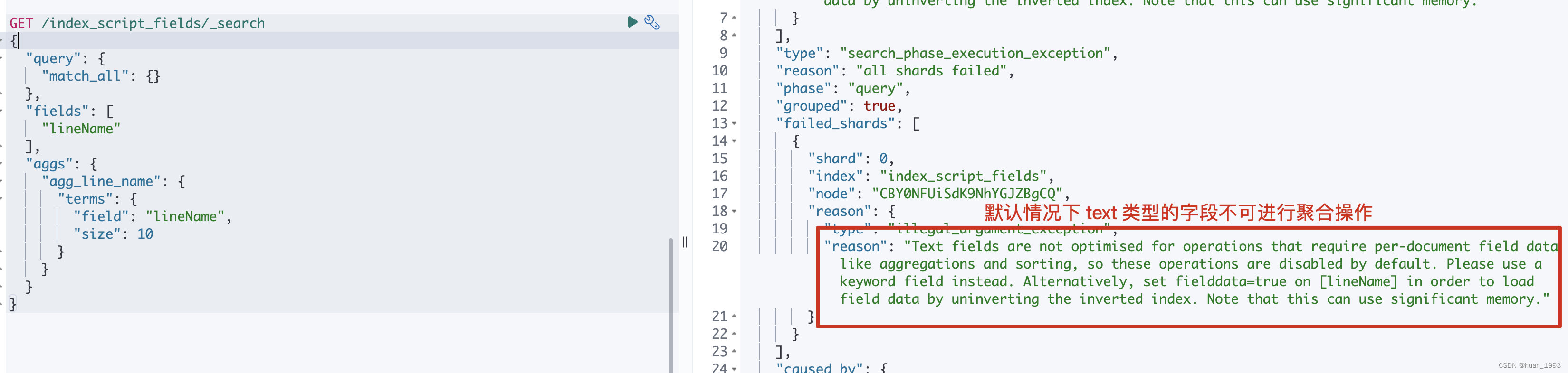
从上方的mapping中可以lineName是text类型,是不可进行聚合操作的,那么此时我们想进行聚合操作,就可以使用runtime field来实现。
5.3.1 不使用runtime field
5.3.2 使用runtime field
5.3.2.1 dsl
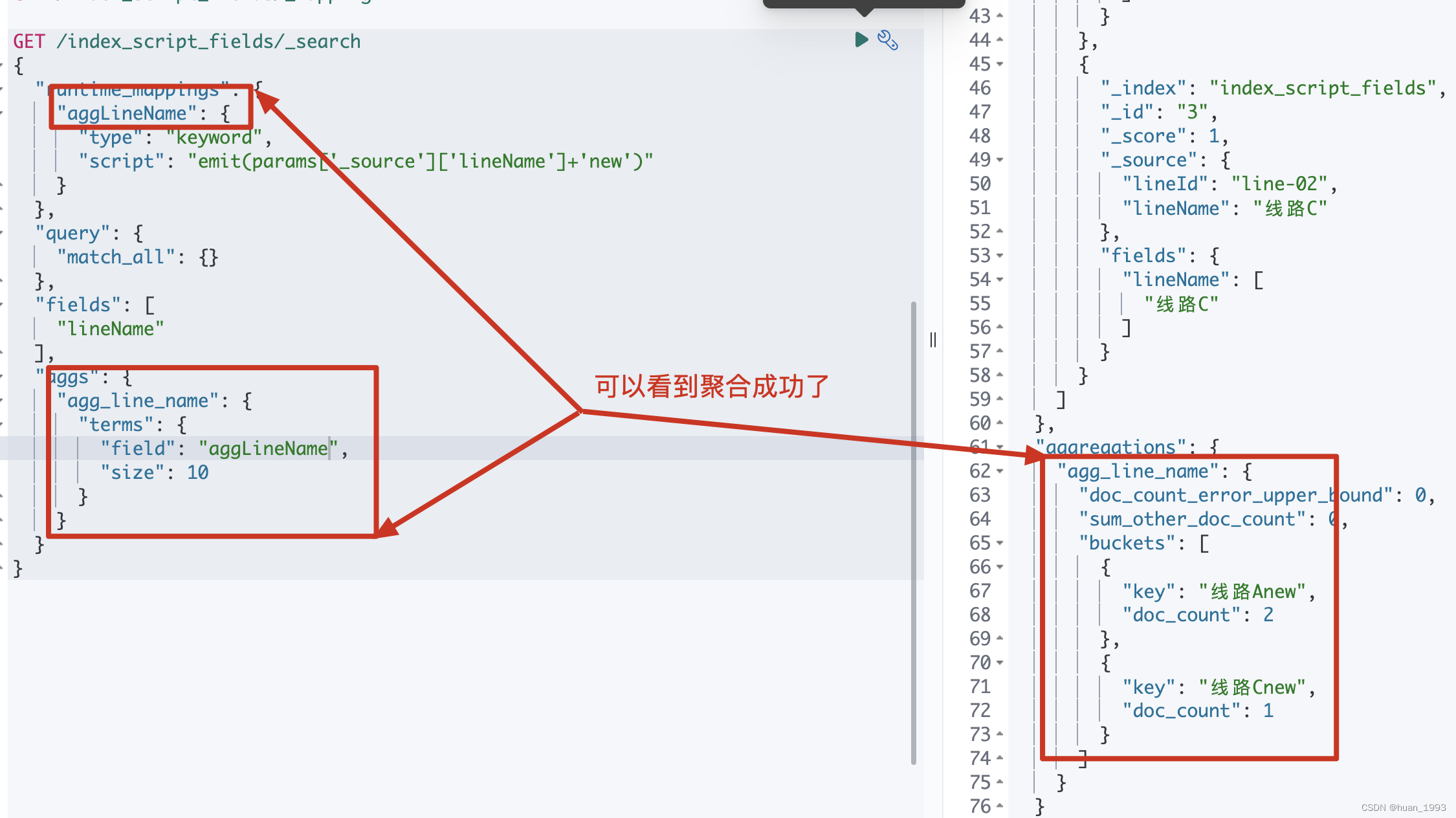
GET /index_script_fields/_search
{
"runtime_mappings": {
"aggLineName": {
"type": "keyword",
"script": "emit(params['_source']['lineName']+'new')"
}
},
"query": {
"match_all": {}
},
"fields": [
"lineName"
],
"aggs": {
"agg_line_name": {
"terms": {
"field": "aggLineName",
"size": 10
}
}
}
}
5.3.2.2 java代码
@Test
@DisplayName("lineName字段是text类型,无法进行聚合操作,定义一个runtime field来进行聚合操作")
public void test01() throws IOException {
SearchRequest request = SearchRequest.of(searchRequest ->
searchRequest.index(INDEX_NAME)
// 查询所有数据
.query(query -> query.matchAll(matchAll -> matchAll))
// runtime field字段不会出现在 _source中,需要使用使用 fields api来获取
.fields(fields -> fields.field("lineName"))
// 创建一个 runtime filed 字段类型是 keyword
.runtimeMappings("aggLineName", runtime ->
runtime
// 此处给字段类型为keyword
.type(RuntimeFieldType.Keyword)
.script(script ->
script.inline(inline ->
// runtime field中如果使用 painless脚本语言,需要使用emit
inline.lang(ScriptLanguage.Painless)
.source("emit(params['_source']['lineName']+'new')")
)
)
)
// 进行聚合操作
.aggregations("agg_line_name", agg ->
// 此处的 aggLineName即为上一步runtime field的字段
agg.terms(terms -> terms.field("aggLineName").size(10))
)
.size(100)
);
System.out.println("request: " + request);
SearchResponse<Object> response = client.search(request, Object.class);
System.out.println("response: " + response);
5.3.3.3 运行结果
6、完整代码
7、参考链接
1、https://www.elastic.co/guide/en/elasticsearch/reference/8.6/runtime.html
elasticsearch中使用runtime fields的更多相关文章
- 如何在Elasticsearch中安装中文分词器(IK+pinyin)
如果直接使用Elasticsearch的朋友在处理中文内容的搜索时,肯定会遇到很尴尬的问题--中文词语被分成了一个一个的汉字,当用Kibana作图的时候,按照term来分组,结果一个汉字被分成了一组. ...
- elasticsearch中常用的API
elasticsearch中常用的API分类如下: 文档API: 提供对文档的增删改查操作 搜索API: 提供对文档进行某个字段的查询 索引API: 提供对索引进行操作,查看索引信息等 查看API: ...
- 在Elasticsearch中查询Term Vectors词条向量信息
这篇文章有点深度,可能需要一些Lucene或者全文检索的背景.由于我也很久没有看过Lucene了,有些地方理解的不对还请多多指正. 更多内容还请参考整理的ELK教程 关于Term Vectors 额, ...
- elasticsearch中的mapping映射配置与查询典型案例
elasticsearch中的mapping映射配置与查询典型案例 elasticsearch中的mapping映射配置示例比如要搭建个中文新闻信息的搜索引擎,新闻有"标题".&q ...
- ES 15 - Elasticsearch中的数据类型 (text、keyword、date、geo等)
目录 1 核心数据类型 1.1 字符串类型 - string(不再支持) 1.1.1 文本类型 - text 1.1.2 关键字类型 - keyword 1.2 数字类型 - 8种 1.3 日期类型 ...
- Elasticsearch学习之图解Elasticsearch中的_source、_all、store和index属性
转自 : https://blog.csdn.net/napoay/article/details/62233031 1. 概述 Elasticsearch中有几个关键属性容易混淆,很多人搞不清楚_s ...
- 【分布式搜索引擎】Elasticsearch中的基本概念
一.Elasticsearch中的基本概念 以下概念基于这个例子:存储员工数据,每个文档代表一个员工 1)索引(index) 在Elasticsearch中存储数据的行为就叫做索引(indexing ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 四十六 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
前面我们讲到的elasticsearch(搜索引擎)操作,如:增.删.改.查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个pyt ...
- Elasticsearch 中映射参数doc_values 和 fielddata分析比较
doc_values 默认情况下,大部分字段是索引的,这样让这些字段可被搜索.倒排索引(inverted index)允许查询请求在词项列表中查找搜索项(search term),并立即获得包含该词项 ...
随机推荐
- JS学习笔记 (四) 数组进阶
1.基本知识 1.数组是值的有序集合.每个值叫做一个元素,而每个元素在数组中的位置称为索引,以数字表示,以0开始. 2.数组是无类型的.数组元素可以是任意类型,并且同一个数组中的不同元素也可能有不同的 ...
- 1.docker的基本使用
1.简介 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化.容器是完 ...
- 【笔记】入门DP
复习一下近期练习的入门 \(DP\) .巨佬勿喷.\(qwq\) 重新写一遍练手,加深理解. 代码已经处理,虽然很明显,但请勿未理解就贺 \(qwq\) 0X00 P1057 [NOIP2008 普及 ...
- Installing ClickHouse-22.10.2.11 on openEuler
一.Installing ClickHouse-22.10.2.11 on openEuler 1 地址 https://clickhouse.com https://packages.clickho ...
- Go语言核心36讲28
我在前面用20多篇文章,为你详细地剖析了Go语言本身的一些东西,这包括了基础概念.重要语法.高级数据类型.特色语句.测试方案等等. 这些都是Go语言为我们提供的最核心的技术.我想,这已经足够让你对Go ...
- 一张VR图像帧的生命周期
"VR 应用程序每帧渲染两张图像,一张用于左眼,一张用于右眼."人们通常这样来解释 VR 渲染,虽然没有错,但可能过于简单化了.对于 Quest 开发人员来说,了解全貌是有益的,这 ...
- 【每日一题】【List与Array互转】【工具类的使用】2021年12月10日-56. 合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] .请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入 ...
- 【JUC】信号量Semaphore详解
欢迎关注专栏[JAVA并发] 欢迎关注个人公众号-- JAVA旭阳 前言 大家应该都用过synchronized 关键字加锁,用来保证某个时刻只允许一个线程运行.那么如果控制某个时刻允许指定数量的线程 ...
- Service层
package com.neu.service; import java.util.List; import com.neu.bean.User;import com.neu.dao.UserDao; ...
- referer的反爬和爬虫下载视频
一.缘由 在梨视频等一些网站中会使用防盗链作为反爬的基础方法,这个反爬并不严重,只是平时的时候需要多加留意.此次实现对应链接中梨视频的下载. 二.代码实现 #1.拿到contid #2.拿到video ...