4.10:Spark之wordcount
〇、概述
1、拓扑结构
2、目标
使用spark完成计数实验
一、启动环境
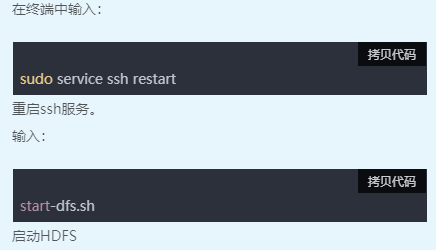
二、新建数据文件

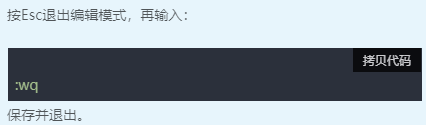
三、查看文件内容

四、启动spark服务
五、编写代码
复制以下代码到shell中(复制后在终端右键->粘贴):
import org.apache.spark.HashPartitioner
import java.io.PrintWriter
import java.io.File val links = sc.parallelize(List(("A",List("B","C")),("B",List("A","C")),("C",List("A","B","D")),("D",List("C")))).partitionBy(new HashPartitioner(100)).persist() var ranks=links.mapValues(v=>1.0) for (i <- 0 until 10) {
val contributions=links.join(ranks).flatMap {
case (pageId,(links,rank)) => links.map(dest=>(dest,rank/links.size))
}
ranks=contributions.reduceByKey((x,y)=>x+y).mapValues(v=>0.15+0.85*v)
} ranks.sortByKey().collect() var input = sc.textFile("hdfs://localhost:9000/wordcount/srcdata/article.data")
val writer = new PrintWriter(new File("/home/user/bigdata/spark_output.txt"))
writer.println(input.flatMap(x=>x.split(" ")).countByValue())
writer.close()
input.flatMap(x=>x.split(" ")).countByValue()
之后可以查看输出结果。

4.10:Spark之wordcount的更多相关文章
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- Spark版wordcount,并根据词频进行排序
import org.apache.spark.{SparkConf, SparkContext}/** * Created by loushsh on 2017/10/9. */object Wor ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- Spark 实现wordcount
配置完spark之后,使用spark实现wordcount,这一部分完全参考<深入理解Spark:核心思想与源码分析> 依然使用hadoop wordcountTest的那几个txt文件 ...
- spark 例子wordcount topk
spark 例子wordcount topk 例子描述: [单词计算wordcount ] [词频排序topk] 单词计算在代码方便很简单,基本大体就三个步骤 拆分字符串 以需要进行记数的单位为K,自 ...
- .Net for Spark 实现 WordCount 应用及调试入坑详解
.Net for Spark 实现WordCount应用及调试入坑详解 1. 概述 iNeuOS云端操作系统现在具备物联网.视图业务建模.机器学习的功能,但是缺少一个计算平台产品.最近在调研使用 ...
- 在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包 ...
- spark学习之IDEA配置spark并wordcount提交集群
这篇文章包括以下内容 (1)IDEA中scala的安装 (2)hdfs简单的使用,没有写它的部署 (3) 使用scala编写简单的wordcount,输入文件和输出文件使用参数传递 (4)IDEA打包 ...
随机推荐
- Elasticsearch:使用 IP 过滤器限制连接
文章转载自:https://elasticstack.blog.csdn.net/article/details/107154165
- Kubernetes DevOps: Jenkins
提到基于 Kubernete 的CI/CD,可以使用的工具有很多,比如 Jenkins.Gitlab CI 以及新兴的 drone 之类的,我们这里会使用大家最为熟悉的 Jenkins 来做 CI/C ...
- MinIO Client完全指南
官方文档地址:http://docs.minio.org.cn/docs/master/minio-client-complete-guide 下载,添加云存储服务参考这篇文章:https://www ...
- MongoDB 副本集的用户和权限一般操作步骤
步骤总结: 在主节点上添加超管用户,副本集会自动同步 按照仲裁者.副本节点.主节点的先后顺序关闭所有节点服务 创建副本集认证的key文件,复制到每个服务所在目录 修改每个服务的配置文件,增加参数 启动 ...
- 打造企业自己代码规范IDEA插件(中)
一些基本概念 在开始独立研发公司自己的代码规范检查规则之前,先介绍一些相关的基本概念.阿里巴巴代码规范很多规则其实都是基于开源框架PMD进行的研发.PMD用官方的话语介绍来说:PMD是一个源代码分析器 ...
- HBase(1/5)
HBase学习(一) 一.了解HBase 官方文档:https://hbase.apache.org/book.html 1.1 HBase概述 HBase 是一个高可靠性.高性能.面向列.可伸缩的分 ...
- P2680 [NOIP2015 提高组] 运输计划 (树上差分-边差分)
P2680 题目的大意就是走完m条路径所需要的最短时间(边权是时间), 其中我们可以把一条边的权值变成0(也就是题目所说的虫洞). 可以考虑二分答案x,找到一条边,使得所有大于x的路径都经过这条边(差 ...
- 洛谷P2627 [USACO11OPEN]Mowing the Lawn G (单调队列优化DP)
一道单调队列优化DP的入门题. f[i]表示到第i头牛时获得的最大效率. 状态转移方程:f[i]=max(f[j-1]-sum[j])+sum[i] ,i-k<=j<=i.j的意义表示断点 ...
- 驱动开发:内核中实现Dump进程转储
多数ARK反内核工具中都存在驱动级别的内存转存功能,该功能可以将应用层中运行进程的内存镜像转存到特定目录下,内存转存功能在应对加壳程序的分析尤为重要,当进程在内存中解码后,我们可以很容易的将内存镜像导 ...
- Vue学习之--------监视属性(2022/7/10)
文章目录 1.监视属性 1.1 监视属性--天气案例 1.1.1 基础知识 1.1.2 代码实例 1.1.2 测试效果 1.2 深度监视-天气案例 1.2.1 基础知识 1.2.2 代码实例 1.2. ...