【大数据面试】【框架】Flume:Source的断点续传、重复数据、Channel选择
〇、用途
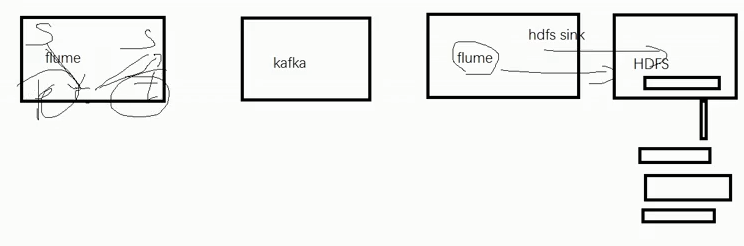
流式结构
获取磁盘日志,拦截器过滤后,传递指定数据,写入HDFS或kafka
一、组成-Source、Channel、Sink
事务(put/take)
1、Source---taildir source:
(1)特点:断点续传+多目录(维护offset)
产生自哪个版本-Apache Flume1.7,CDH 1.6
(2)没有断点续传功能时如何使用?自定义方式实现
(3)taildir挂掉怎么办,是否有影响
首先不会丢数(断点续传),但是会产生重复数据(一条或一批次)
读取成功,写入失败
(4)怎么处理重复数据?
生产环境下通常不处理,处理方案
自身:可以在taildir source内部增加自定义事务
找兄弟:下一级处理(sparkStreaming、hive、dwd、flink过滤器),手段(group by去重、开窗取窗口最小,只取第一条、Redis集群帮助去重)
(5)taildir source是否支持递归遍历文件夹读取文件?
不支持,需要自定义
递归遍历文件夹+读取文件
2、Channel
(1)常见的Channel包括哪些及对应的特点
File Channel:数据存储在磁盘上(数据可靠性高、传输速度低),默认存储容量:100w个event
Memory Channel:数据存储于内存(传输速度快、可靠性差),默认容量是100个event
Kafka Channel:数据存储于kafka/基于磁盘(数据可靠性高、传输速度也快【kafka Channel》kafka sink+Memory Channel,原因:省去了sink阶段】),在flume 1.6版本产生(原因:有bug,可以设置前缀是否带topic,但不起作用)
kafka-topic_start/topic_event,增加了额外清洗的工作量,Flume 1.7解决了该问题
(2)生产环境下如何选择
如果下一级是kafka,通常会优先选择kafka channel
如果下一级不是kafka,金融、对钱要求准确的公司,选择File Channel
如果是普通日志,通常会选择memory Channel(JD每天丢失几百万数据,每天都是PB级数据)
3、HDFS sink
不做控制,会直接落盘,产生大量小文件
可以通过参数控制:时间、大小、event的个数【或】
时间:3600-7200s(1小时-2小时)
大小:128M
event的个数(0禁止)
二、三个器(拦截器、选择器、监控器)
1、拦截器
ETL拦截器、分类型拦截器
(1)ETL拦截器
实现:数据轻度清洗(判断是否是大括号开头结尾,为了保证传输效率/实时性)
判断了数据时间:13位,必须全部是数字
(2)分类型拦截器(11张表)
start
event(商品列表、商品详情、商品点击、
广告、
点赞、评论、收藏、故障、
后台活跃、通知)
哪张表与kafka有关系,要满足所有下一级消费者
创建成特定类,不产生重复数据,针对每个表创建一个topic
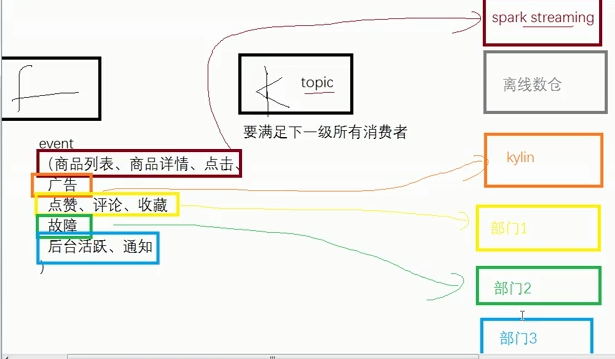
一张表一个topic,一定能满足下一级消费者
为了效率,可以做适当的聚合
(3)自定义拦截器的步骤
定义一个类,实现interceptor接口,重写内部的4个方法:
初始化、关闭、单event、多event、同时创建一个静态内部类Builder
打包==》上传至flume的lib包下==》在配置文件中关联拦截器
(4)可以不使用拦截器吗
可以不用,但需要在下一级hive的DWD层或sparkstreaming里面进行处理
(5)优势和劣势
优势:只处理一次,轻度处理,不会影响太多性能
劣势:影响性能,不适合像推荐这种对实时性要求比较高的场景
三、优化
1、File Channel可以配置多目录-多个磁盘
可以提高吞吐量
2、HDFS Sink
解决小文件:时间、大小、event的个数【或】
3、监控器
调整内存
找自己:提高自己内存
找朋友:增加flume台数
4、Flume挂掉后的操作
source挂掉,可能会产生重复数据(offset),使用事务解决
channel挂掉(File、Memory×、Kafka),会丢失100个event
【大数据面试】【框架】Flume:Source的断点续传、重复数据、Channel选择的更多相关文章
- 爬虫数据使用MongDB保存时自动过滤重复数据
本文转载自以下网站: 爬虫断了?一招搞定 MongoDB 重复数据 https://www.makcyun.top/web_scraping_withpython13.html 需要学习的地方: Mo ...
- MySQL中删除重复数据的简单方法,mysql删除重复数据
MYSQL里有五百万数据,但大多是重复的,真实的就180万,于是想怎样把这些重复的数据搞出来,在网上找了一圈,好多是用NOT IN这样的代码,这样效率很低,自己琢磨组合了一下,找到一个高效的处理方式, ...
- 删除一个表中的重复数据同时保留第一次插入那一条以及sql优化
业务:一个表中有很多数据(id为自增主键),在这些数据中有个别数据出现了重复的数据. 目标:需要把这些重复数据删除同时保留第一次插入的那一条数据,还要保持其它的数据不受影响. 解题过程: 第一步:查出 ...
- mysql 存储过程批量删除重复数据
表结构: LOAD DATA INFILE '/usr/local/phone_imsi_12' replace INTO TABLE tbl_imsi2number_new FIELDS TERMI ...
- SQL Server 一列或多列重复数据的查询,删除
业务需求 最近给公司做一个小工具,把某个数据库(数据源)的数据导进另一个数据(目标数据库).要求导入目标数据库的数据不能出现重复.但情况是数据源本身就有重复的数据.所以要先清除数据源数据. 于是就把关 ...
- Mysql中查找并删除重复数据的方法
(一)单个字段 1.查找表中多余的重复记录,根据(question_title)字段来判断 代码如下 复制代码 select * from questions where question_title ...
- php获取数组中重复数据的两种方法
分享下php获取数组中重复数据的两种方法. 1,利用php提供的函数,array_unique和array_diff_assoc来实现 <?php function FetchRepeatMem ...
- SQL Server 一列或多列重复数据的查询,删除(转载)
转载来源:https://www.cnblogs.com/sunxi/p/4572332.html 业务需求 最近给公司做一个小工具,把某个数据库(数据源)的数据导进另一个数据(目标数据库).要求导入 ...
- MongoDB实现数组中重复数据删除
这个功能真的是写死我了,对于MongoDB一点都不熟悉,本来想使用spring与MongoDB的融合mongoDBTemplate,发现压根不是web项目,懒得配置那些配置文件,就使用最原始的数据库操 ...
- mySql数据重复数据去重
1.问题来源:数据中由于并发问题,数据存在多次调用接口,插入了重复数据,需要根据多条件删除重复数据: 2.参考博客文章地址:https://www.cnblogs.com/jiangxiaobo/p/ ...
随机推荐
- Beats:使用Elastic Stack对Redis监控
- 解决RHEL7.3系统找不到yum命令,无法使用YUM源的问题
前言 RHEL的YUM源需要注册用户才能更新使用,由于CentOS和RHEL基本没有区别,并且CentOS已经被REHL收购.所以将RHEL的YUM源替换为CentOS即可. [root@NISEC- ...
- 生产环境中使用Kibana
在 Kibana 中使用 X-Pack 使用 X-Pack 安全模块 控制用户通过 Kibana 可以访问哪些 Elasticsearch 数据. 当安装 X-Pack 时,Kibana 用户必须登陆 ...
- 基于SqlSugar的开发框架循序渐进介绍(14)-- 基于Vue3+TypeScript的全局对象的注入和使用
刚完成一些前端项目的开发,腾出精力来总结一些前端开发的技术点,以及继续完善基于SqlSugar的开发框架循序渐进介绍的系列文章,本篇随笔主要介绍一下基于Vue3+TypeScript的全局对象的注入和 ...
- PAT (Basic Level) Practice 1014 福尔摩斯的约会 分数 20
大侦探福尔摩斯接到一张奇怪的字条: 我们约会吧! 3485djDkxh4hhGE 2984akDfkkkkggEdsb s&hgsfdk d&Hyscvnm 大侦探很快就明白了,字 ...
- 改善C#程序的方法-1 操作字符串
正确操作字符串 引言: 字符串是使用很频繁的一种数据类型. 如果使用不慎,则会为一次字符串操作所带来的额外性能开销而付出代价. 下面从这几个方面来探讨如何正确操作字符串: 1.确保尽量少的装箱,尽可能 ...
- 分布式存储系统之Ceph基础
Ceph基础概述 Ceph是一个对象式存储系统,所谓对象式存储是指它把每一个待管理的数据流(比如一个文件)切分成一到多个固定大小的对象数据,并以其为原子单元完成数据的存取:对象数据的底层存储服务由多个 ...
- 洛谷P4638 SHOI2011 银行 ( 最大流)
类似题目(一模一样):http://poj.org/problem?id=1149 我这里以poj1149的PIGS为例, 新建源点s和汇点t,n个顾客作为中间的点,,对于每个顾客,他可以解锁一定的猪 ...
- NOIP2015 普及组 洛谷P2671 求和 (数学)
一道数学题...... 采用分组的思想,我们要统计答案的数对满足两个条件:同奇偶,同颜色.所以可以按这两个要求分组. 然后就是分组处理了,对于每组(有k个数),这里面的任意两对数都是满足条件的,可推出 ...
- Effective java 总结
用静态工厂方法代替构造器的最主要好处 1.不必每次都创建新的对象 Boolean.valueOf Long.valueOf 2.直接返回接口的子类型,对于外界来说并不需要关心实现细节,主要知道这个接口 ...