fashion_mnist 计算准确率、召回率、F1值
本文发布于 2020-12-27,很可能已经过时
fashion_mnist 计算准确率、召回率、F1值
1、定义
首先需要明确几个概念:
假设某次预测结果统计为下图:
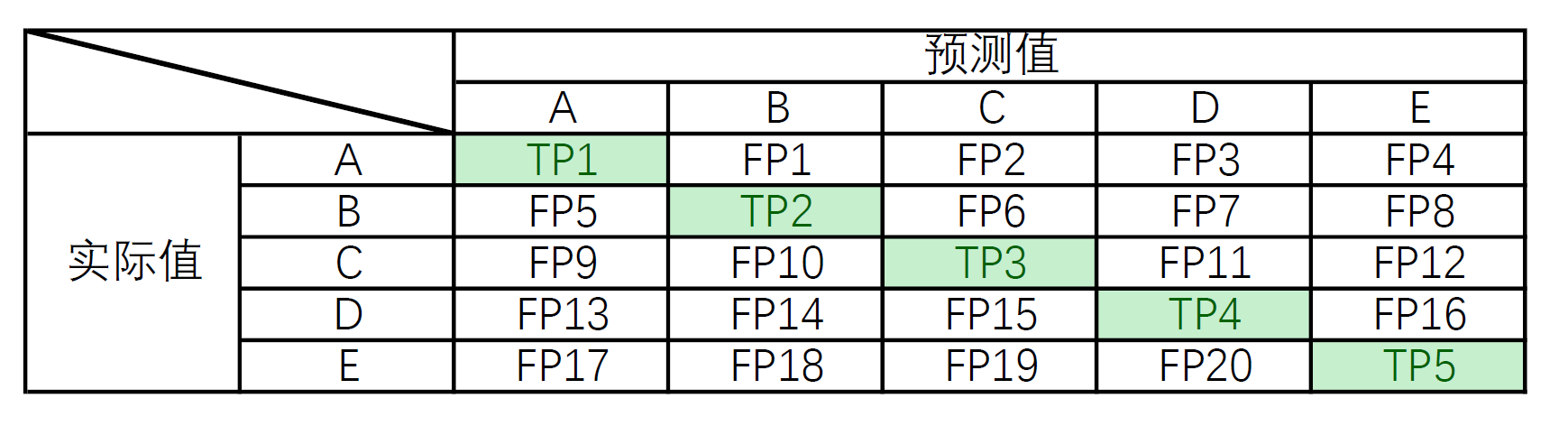
那么各个指标的计算方法为:
- A类的准确率:TP1/(TP1+FP5+FP9+FP13+FP17) 即预测为A的结果中,真正为A的比例
- A类的召回率:TP1/(TP1+FP1+FP2+FP3+FP4) 即实际上所有为A的样例中,能预测出来多少个A(的比例)
- A类的F1值:(准确率*召回率*2)/(准确率+召回率)
实际上我们在训练出某个模型后,会将测试集中每个测试样例进行一次结果预测,因此只需统计这些结果,经过计算即可得到各类数据的准确率、召回率、F1值
2、使用fashion_mnist
需要提前pip安装tensorflow、prettytable、numpy
from tensorflow import keras
import numpy as np
import prettytable
# 下载数据集
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 制作标签名称
class_names = ['T-shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Boot']
# 图片数据归一化
train_images = train_images / 255.0
test_images = test_images / 255.0
# 构建3层DNN模型,使用激活函数softmax
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
# 定义模型的损失函数,优化器与评估指标
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=0.001),
loss=keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy']
)
# 训练模型
model.fit(train_images, train_labels, epochs=5)
# 评估模型
predictions = model.predict(test_images)
train_result = np.zeros((10, 10), dtype=int)
for i in range(10000):
train_result[test_labels[i]][np.argmax(predictions[i])] += 1
result_table = prettytable.PrettyTable()
result_table.field_names = ['Type', 'Accu', 'Recall', 'F1']
for i in range(10):
ac = train_result[i][i] / sum(train_result.T[i])
rc = train_result[i][i] / sum(train_result[i])
result_table.add_row([class_names[i], round(ac, 3), round(rc, 3), round(ac * rc * 2 / (ac + rc), 3)])
print(result_table)
实际效果:
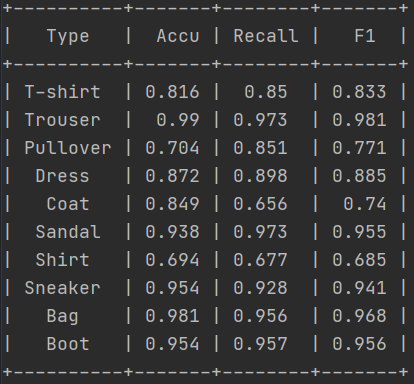
fashion_mnist 计算准确率、召回率、F1值的更多相关文章
- 机器学习笔记--classification_report&精确度/召回率/F1值
https://blog.csdn.net/akadiao/article/details/78788864 准确率=正确数/预测正确数=P 召回率=正确数/真实正确数=R F1 F1值是精确度和召回 ...
- 准确率,召回率,F值,ROC,AUC
度量表 1.准确率 (presion) p=TPTP+FP 理解为你预测对的正例数占你预测正例总量的比率,假设实际有90个正例,10个负例,你预测80(75+,5-)个正例,20(15+,5-)个负例 ...
- 机器学习classification_report方法及precision精确率和recall召回率 说明
classification_report简介 sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息. 主要 ...
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
原文地址:http://blog.csdn.net/pkueecser/article/details/8229166 在信息检索.分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常 ...
- 准确率、精确率、召回率、F1
在搭建一个AI模型或者是机器学习模型的时候怎么去评估模型,比如我们前期讲的利用朴素贝叶斯算法做的垃圾邮件分类算法,我们如何取评估它.我们需要一套完整的评估方法对我们的模型进行正确的评估,如果模型效果比 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- 准确率P 召回率R
Evaluation metricsa binary classifier accuracy,specificity,sensitivety.(整个分类器的准确性,正确率,错误率)表示分类正确:Tru ...
- 机器学习 F1-Score 精确率 - P 准确率 -Acc 召回率 - R
准确率 召回率 精确率 : 准确率->accuracy, 精确率->precision. 召回率-> recall. 三者很像,但是并不同,简单来说三者的目的对象并不相同. 大多时候 ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
随机推荐
- 按照递推的思想求解next[]数组
按照递推的思想求解next[]数组 根据定义next[0]=-1,假设next[j]=k, 即P[0...k-1]==P[j-k,j-1] 若P[j]P[k],则有P[0..k]P[j-k,j],很显 ...
- llinux_2
1.显示/etc目录下,以非字母开头,后面跟了一个字母以及其它任意长度任意字符的文件或目录 [root@lhq ~]#ls /etc/ | grep "^[^[:alpha:]][[:alp ...
- 申请Google AdSense联盟(还没有通过)
最近我把我的博客移动到了我自己搭建的一个网站上这里,想申请goole联盟,但是连续申请了今天都没有被通过 不知道什么原因,goole没有有回复就告诉你不通过,这让我摸不到头脑, 我网站用的是hexo搭 ...
- Solution -「Gym 102956F」Border Similarity Undertaking
\(\mathcal{Description}\) Link. 给定一张 \(n\times m\) 的表格,每个格子上写有一个小写字母.求其中长宽至少为 \(2\),且边界格子上字母相同的矩 ...
- Solution -「ARC 101E」「AT 4352」Ribbons on Tree
\(\mathcal{Description}\) Link. 给定一棵 \(n\) 个点的树,其中 \(2|n\),你需要把这些点两两配对,并把每对点间的路径染色.求使得所有边被染色的方案数 ...
- Solution -「LOCAL」「cov. 牛客多校 2020 第五场 C」Easy
\(\mathcal{Description}\) Link.(完全一致) 给定 \(n,m,k\),对于两个长度为 \(k\) 的满足 \(\left(\sum_{i=0}^ka_i=n\r ...
- Windows RestartManeger重启管理器
介绍 重启管理器API可以消除或是减少在完成安装或是更新的过程中系统需要重启的次数.软件安装或是更新过程之所以需要重启系统的原因在于一些需要更新的文件正在被运行中的程序或服务使用.而重启管理器可以 ...
- 怎么说服领导,能让我用DDD架构肝项目?
作者:小傅哥 博客:https://bugstack.cn 原文:https://mp.weixin.qq.com/s/ezd-6xkRiNfPH1lGwhLd8Q 沉淀.分享.成长,让自己和他人都能 ...
- 【摸鱼神器】UCode Cms管理系统 内置超好用的代码生成器 解决多表连接痛点
一.序言 UCode Cms管理系统是面向企业级应用软件开发的脚手架.当前版本1.3.4.快速体验: git clone https://gitee.com/decsa/demo-cms.git (一 ...
- Java 使用jcifs读写共享文件夹报错jcifs.smb.SmbException: Failed to connect: 0.0.0.0<00>/10.1.*.*
Q:使用jcifs读写Windows 10 共享文件夹中的文件报jcifs.smb.SmbException: Failed to connect: 0.0.0.0<00>/10.1.*. ...