[PY3]——heap模块 和 堆排序
heapify( )
heapify()函数用于将一个序列转化为初始化堆
nums=[16,7,3,20,17,8,-1]
print('nums:',nums)
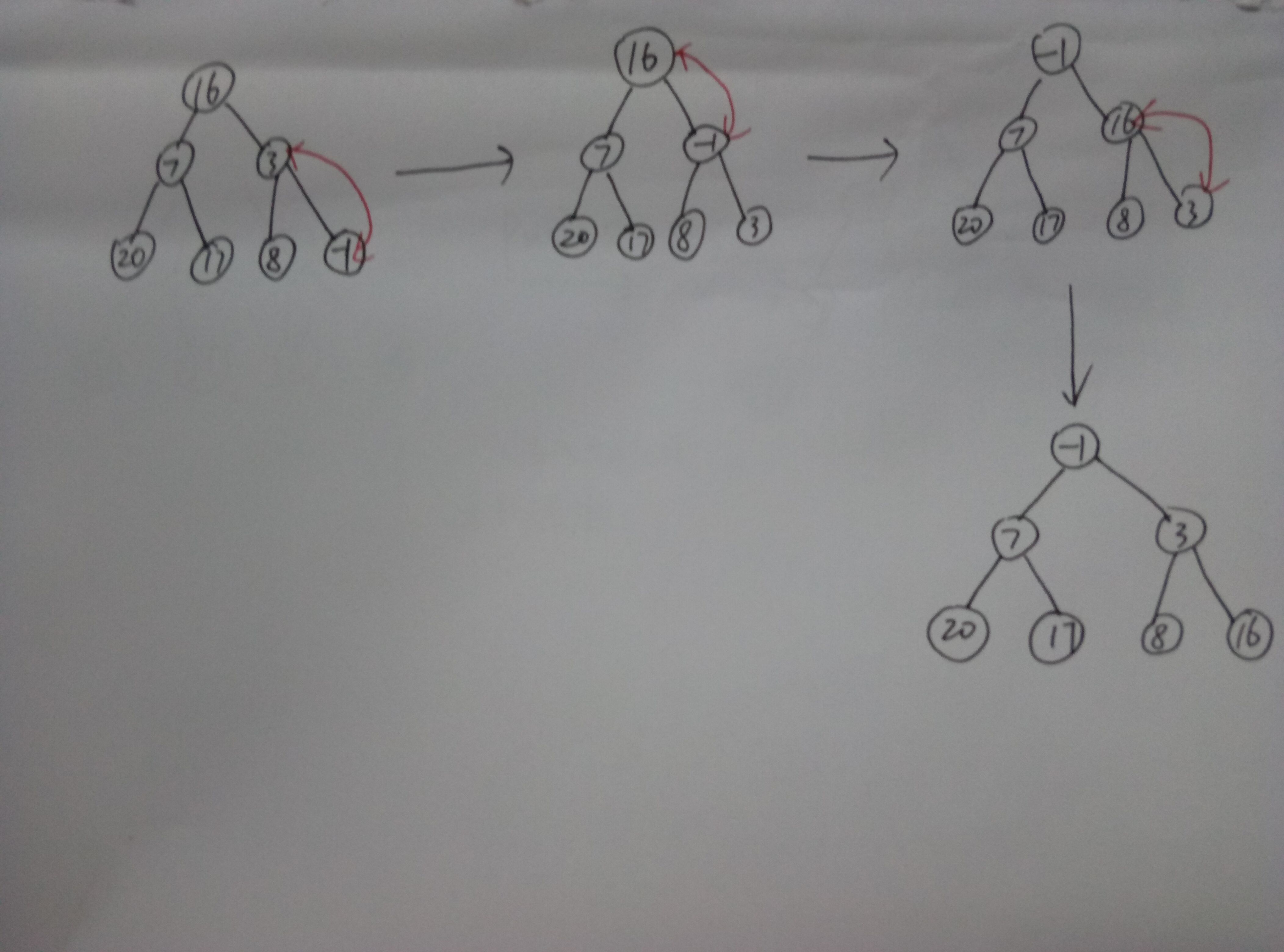
show_tree(nums) nums: [16, 7, 3, 20, 17, 8, -1] 16
7 3
20 17 8 -1
------------------------------------ heapq.heapify(nums)
print('nums:',nums)
show_tree(nums) nums: [-1, 7, 3, 20, 17, 8, 16] -1
7 3
20 17 8 16
------------------------------------
heappush( )
heappush()是实现将元素插入到堆的操作
heappush()操作前一定要先将序列初始化成堆!heappush是对于"堆"的操作!不然是没有意义
nums=[16,7,3,20,17,8,-1]
print(nums)
show_tree(nums) [16, 7, 3, 20, 17, 8, -1] 16
7 3
20 17 8 -1
------------------------------------
heapq.heapify(nums)
print('初始化成堆:',nums)
show_tree(nums) 初始化成堆: [-1, 7, 3, 20, 17, 8, 16] -1
7 3
20 17 8 16
------------------------------------
for i in random.sample(range(1,8),2):
print("本次push:",i)
heapq.heappush(nums,i)
print(nums)
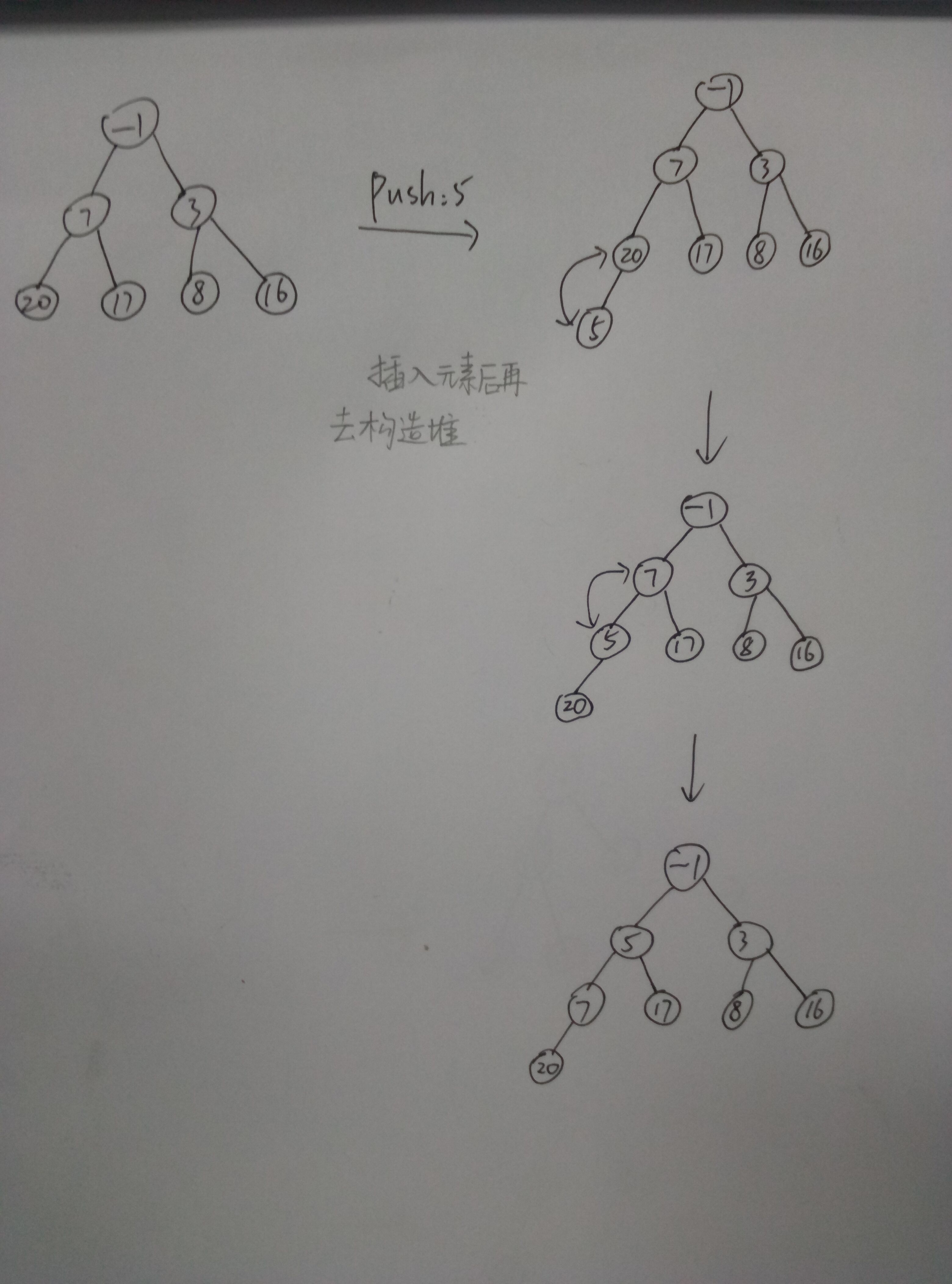
show_tree(nums) 本次push: 5
[-1, 5, 3, 7, 17, 8, 16, 20] -1
5 3
7 17 8 16
20
------------------------------------ 本次push: 7
[-1, 5, 3, 7, 17, 8, 16, 20, 7] -1
5 3
7 17 8 16
20 7
------------------------------------
heappop( )
heappop()是实现将元素删除出堆的操作
同样的操作前一定要先将序列初始化成堆,否则也没什么意义
nums=[16,7,3,20,17,8,-1]
print(nums)
show_tree(nums) [16, 7, 3, 20, 17, 8, -1] 16
7 3
20 17 8 -1
------------------------------------ heapq.heapify(nums)
print('初始化成堆:',nums)
show_tree(nums) 初始化成堆: [-1, 7, 3, 20, 17, 8, 16] -1
7 3
20 17 8 16
------------------------------------
for i in range(0,2):
print("本次pop:",heapq.heappop(nums))
print(nums)
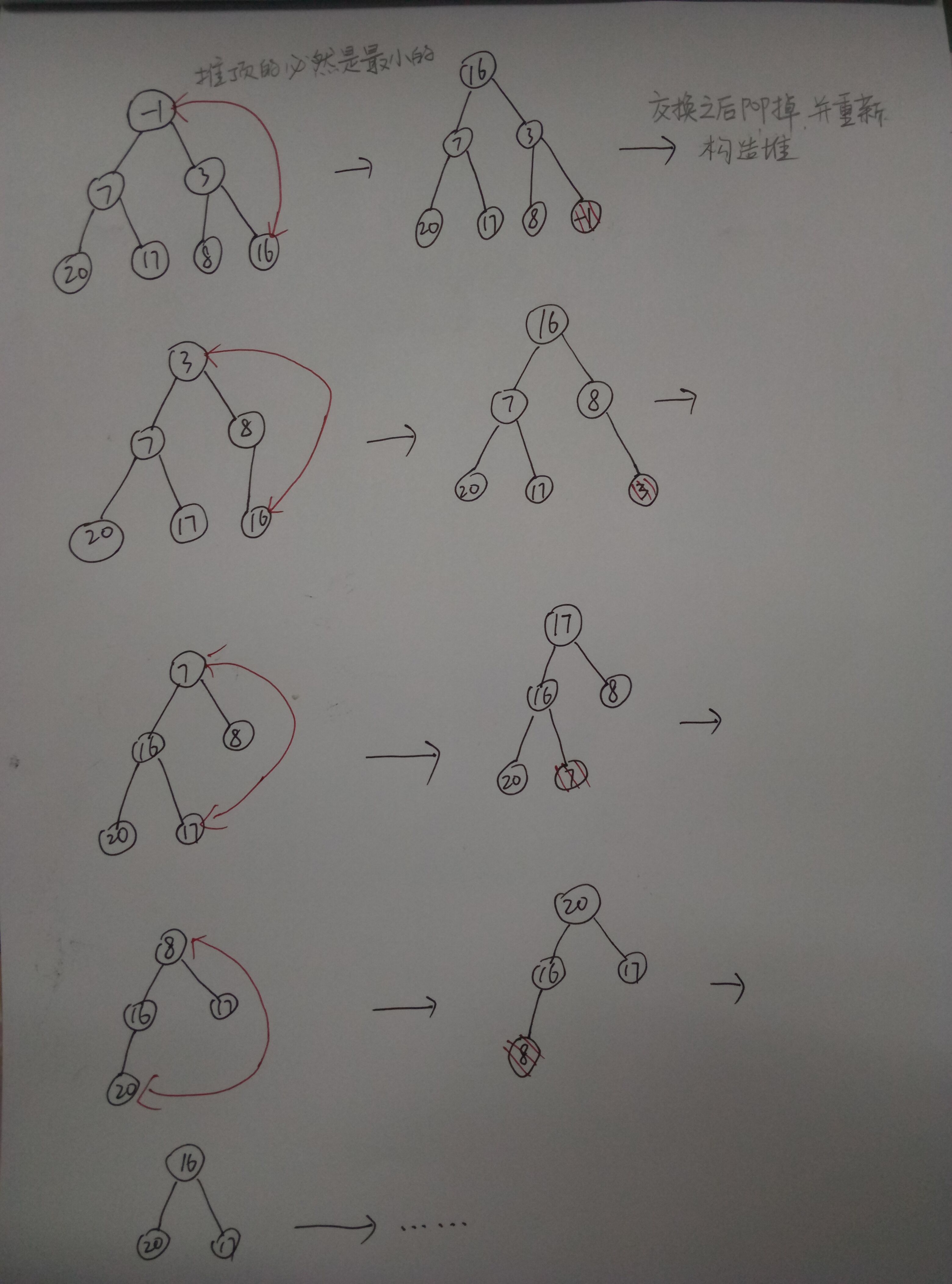
show_tree(nums) 本次pop: -1
[3, 7, 8, 20, 17, 16] 3
7 8
20 17 16
------------------------------------ 本次pop: 3
[7, 16, 8, 20, 17] 7
16 8
20 17
------------------------------------
nlargest( )/nsmallest( )
sorted(iterable, key=key, reverse=True)[:n]
- nlargest(n,iterable) 求序列iterable中的TopN | nsmallest(n,iterable) 求序列iterable中的BtmN
import heapq
nums=[16,7,3,20,17,8,-1]
print(heapq.nlargest(3,nums))
print(heapq.nsmallest(3,nums)) [20, 17, 16]
[-1, 3, 7]
- nlargest(n, iterable, key=lambda) | nsmallest(n, iterable, key=lambda) key接受关键字参数,用于更复杂的数据结构中
def print_price(dirt):
for i in dirt:
for x,y in i.items():
if x=='price':
print(x,y) portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
] cheap=heapq.nsmallest(3,portfolio,key=lambda x:x['price'])
expensive=heapq.nlargest(3,portfolio,key=lambda y:y['price'])
print_price(cheap)
print_price(expensive) price 16.35
price 21.09
price 31.75 price 543.22
price 115.65
price 91.1
关于heap和heap sort
对于上面的nums=[16,7,3,20,17,8,-1]序列,图解了:
{kind=link}
{kind=link}
{kind=link}
参考文章
详解Python中heapq模块的用法(包括show_tree())
[PY3]——heap模块 和 堆排序的更多相关文章
- 模块 heapq_堆排序
_heapq_堆排序 该模块提供了堆排序算法的实现.堆是二叉树,最大堆中父节点大于或等于两个子节点,最小堆父节点小于或等于两个子节点. 创建堆 heapq有两种方式创建堆, 一种是使用一个空列表,然后 ...
- [数据结构]——堆(Heap)、堆排序和TopK
堆(heap),是一种特殊的数据结构.之所以特殊,因为堆的形象化是一个棵完全二叉树,并且满足任意节点始终不大于(或者不小于)左右子节点(有别于二叉搜索树Binary Search Tree).其中,前 ...
- PAT Advanced 1098 Insertion or Heap Sort (25) [heap sort(堆排序)]
题目 According to Wikipedia: Insertion sort iterates, consuming one input element each repetition, and ...
- [PY3]——实现一个优先级队列
import heapq class PriorityQueue: def __init__(self): self._queue=[] self._index=0 def push(self,ite ...
- 【算法】堆排序(Heap Sort)(七)
堆排序(Heap Sort) 堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法.堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父 ...
- 算法 排序NB二人组 堆排序 归并排序
参考博客:基于python的七种经典排序算法 常用排序算法总结(一) 序前传 - 树与二叉树 树是一种很常见的非线性的数据结构,称为树形结构,简称树.所谓数据结构就是一组数据的集合连同它们的储 ...
- 有k个list列表, 各个list列表的元素是有序的,将这k个列表元素进行排序( 基于堆排序的K路归并排序)
解题思路: 排序方法:多路归并排序 每次将n个list的头元素取出来,进行排序(堆排序),最小元素从堆中取出后,将其所在list的下一个元素 放入堆中,调整堆序列. 函数实现原型: void list ...
- day39 算法基础
参考博客: http://www.cnblogs.com/alex3714/articles/5474411.html http://www.cnblogs.com/wupeiqi/articles/ ...
- fasttext源码剖析
fasttext源码剖析 目的:记录结合多方资料以及个人理解的剖析代码: https://heleifz.github.io/14732610572844.html http://www.cnbl ...
随机推荐
- 新入门PGSQL数据库(尝试利用PGPOOL实现分布式),摘录笔记
概念: PostgreSQL (pronounced "post-gress-Q-L") is an open source relational database managem ...
- hadoop2.2.0编译、安装和测试
搭建环境:单机64位CentOS6.5 .jdk1.6.0_45.Hadoop2.2.0 1.准备编译环境 从http://www.apache.org/dyn/closer.cgi/hadoop/c ...
- 使用bmfont制作字体
本地显示正常 将制作好的字体上传 别人用不好使 制作完场景没ctrl+s 保存 ctrl+s保存之后生成另外的文件
- OCP 052最新考试题库和答案收集-34
34.Which two can be backed up by using RMAN when a database Is open in ARCHIVELOG mode, so that medi ...
- php运行环境学习
web服务器,负责响应客户端请求.对于静态页面请求,会立即返回相应页面给客户端:如果是动态页面,web服务器会根据 httpd.conf中的AddType配置,提交给合适的动态脚本解析程序预处理,然后 ...
- [ActionSprit 3.0] FMS客户端与服务器端交互(传参)
客户端as: import flash.net.NetConnection; import flash.events.NetStatusEvent; var nc:NetConnection = ne ...
- java处理excel-xlsx格式大文件的解决方案
1.第一次读取7M左右的ecxel文件,使用poi 库实现,参考了下面的博文. http://www.cnblogs.com/chenfool/p/3632642.html 使用上面的方法在 下面Wo ...
- centos的 / ~ - 的意思
. 当前目录 .. 上一层目录 - 前一个工作目录,上一次操作的目录 cd - 会切换都上次你操作的目录 ~ 当前[用户]所在的家目录/ root的根目录
- HashSet存储过程中如何排除不同的自定义对象?
HashSet HashSet存储过程中如何排除不同的自定义对象? 先看一个小demo public class Demo1 { public static void main(String[] ar ...
- [转] AKKA简介
[From] https://blog.csdn.net/linuxarmsummary/article/details/79399602 Akka in JAVA(一) AKKA简介 什么是AKKA ...