Oracle 行列转换总结
行列转换包括以下六种情况:
*列转行
*行转列
*多列转换成字符串
*多行转换成字符串
*字符串转换成多列
*字符串转换成多行
下面分别进行举例介绍。
首先声明一点,有些例子需要如下10g及以后才有的知识:
a、掌握model子句
b、正则表达式
c、加强的层次查询
讨论的适用范围只包括8i,9i,10g及以后版本。begin:
1、列转行
未列转行之前的效果如下:

列转行的效果如下:

sql代码:
CREATE TABLE t_col_row(
ID INT,
c1 VARCHAR2(10),
c2 VARCHAR2(10),
c3 VARCHAR2(10)
);
INSERT INTO t_col_row VALUES (1, 'v11', 'v21', 'v31');
INSERT INTO t_col_row VALUES (2, 'v12', 'v22', NULL);
INSERT INTO t_col_row VALUES (3, 'v13', NULL, 'v33');
INSERT INTO t_col_row VALUES (4, NULL, 'v24', 'v34');
INSERT INTO t_col_row VALUES (5, 'v15', NULL, NULL);
INSERT INTO t_col_row VALUES (6, NULL, NULL, 'v35');
INSERT INTO t_col_row VALUES (7, NULL, NULL, NULL);
COMMIT;
SELECT * FROM t_col_row;
1).UNION ALL–>适用范围:8i,9i,10g及以后版本
sql代码:
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv FROM t_col_row;
若空行不需要转换,只需加一个where条件,
sql代码:
WHERE COLUMN IS NOT NULL
2).MODEL–>适用范围:10g及以后
SELECT id, cn, cv FROM t_col_row
MODEL
RETURN UPDATED ROWS
PARTITION BY (ID)
DIMENSION BY (0 AS n)
MEASURES ('xx' AS cn,'yyy' AS cv,c1,c2,c3) --xx、yyy表示字段长度
RULES UPSERT ALL
(
cn[] = 'c1',
cn[] = 'c2',
cn[] = 'c3',
cv[] = c1[],
cv[] = c2[],
cv[] = c3[]
)
ORDER BY ID,cn;
现在小分析一下上面这个查询:
partition by (prd_type_id)指定结果是根据prd_type_id分区的。
dimension by (0 AS n)定义数组的长度,这就意味着必须提供数组索引才能访问数组中的单元。
measures ('xx' AS cn)表明数组中的每个单元包含一个数量,同时表明数组名为cn。
3).collection–>适用范围:8i,9i,10g及以后版本
要创建一个对象和一个集合:
sql语句:
CREATE TYPE cv_pair AS OBJECT(cn VARCHAR2(10), cv VARCHAR2(10));
CREATE TYPE cv_varr AS VARRAY(8) OF cv_pair;
SELECT id, t.cn AS cn, t.cv AS cv
FROM t_col_row,
TABLE(cv_varr(cv_pair('c1', t_col_row.c1),
cv_pair('c2', t_col_row.c2),
cv_pair('c3', t_col_row.c3))) t
ORDER BY 1, 2;
2、行转列
未行转列之前的效果如下:
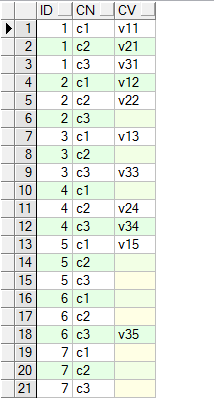
行转列的效果如下:
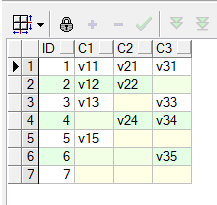
CREATE TABLE t_row_col AS
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv FROM t_col_row;
SELECT * FROM t_row_col ORDER BY 1,2;
1)AGGREGATE FUNCTION–>适用范围:8i,9i,10g及以后版本
SELECT id,
MAX(decode(cn, 'c1', cv, NULL)) AS c1,
MAX(decode(cn, 'c2', cv, NULL)) AS c2,
MAX(decode(cn, 'c3', cv, NULL)) AS c3
FROM t_row_col
GROUP BY id
ORDER BY 1;
max聚集函数也可以用sum、min、avg等其他聚集函数替代。
被指定的转置列只能有一列,但固定的列可以有多列,请看下面的例子:
SELECT mgr, deptno, empno, ename FROM scott.emp ORDER BY 1, 2;
SELECT mgr,
deptno,
MAX(decode(empno, '', ename, NULL)) "7788",
MAX(decode(empno, '', ename, NULL)) "7902",
MAX(decode(empno, '', ename, NULL)) "7844",
MAX(decode(empno, '', ename, NULL)) "7521",
MAX(decode(empno, '', ename, NULL)) "7900",
MAX(decode(empno, '', ename, NULL)) "7499",
MAX(decode(empno, '', ename, NULL)) "7654"
FROM scott.emp
WHERE mgr IN (7566, 7698)
AND deptno IN (20, 30)
GROUP BY mgr, deptno
ORDER BY 1, 2;
这里转置列为empno,固定列为mgr,deptno。
还有一种行转列的方式,就是相同组中的行值变为单个列值,但转置的行值不变为列名:
SELECT id,
MAX(decode(rn, 1, cn, NULL)) cn_1,
MAX(decode(rn, 1, cv, NULL)) cv_1,
MAX(decode(rn, 2, cn, NULL)) cn_2,
MAX(decode(rn, 2, cv, NULL)) cv_2,
MAX(decode(rn, 3, cn, NULL)) cn_3,
MAX(decode(rn, 3, cv, NULL)) cv_3
FROM (SELECT id,
cn,
cv,
row_number() over(PARTITION BY id ORDER BY cn, cv) rn
FROM t_row_col)
GROUP BY ID;
结果效果如下:
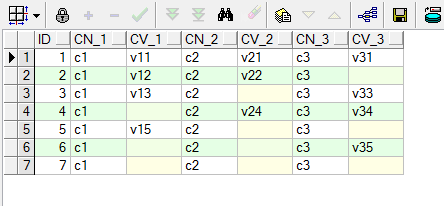
2)PL/SQL
适用范围:8i,9i,10g及以后版本
这种对于行值不固定的情况可以使用。
下面是我写的一个包,包中
p_rows_column_real用于前述的第一种不限定列的转换;
p_rows_column用于前述的第二种不限定列的转换。
CREATE OR REPLACE PACKAGE pkg_dynamic_rows_column AS
TYPE refc IS REF CURSOR;
PROCEDURE p_print_sql(p_txt VARCHAR2);
FUNCTION f_split_str(p_str VARCHAR2, p_division VARCHAR2, p_seq INT)
RETURN VARCHAR2;
PROCEDURE p_rows_column(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_cols IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc);
PROCEDURE p_rows_column_real(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_col IN VARCHAR2,
p_pivot_val IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc);
END;
/
CREATE OR REPLACE PACKAGE BODY pkg_dynamic_rows_column AS
PROCEDURE p_print_sql(p_txt VARCHAR2) IS
v_len INT;
BEGIN
v_len := length(p_txt);
FOR i IN 1 .. v_len / 250 + 1 LOOP
dbms_output.put_line(substrb(p_txt, (i - 1) * 250 + 1, 250));
END LOOP;
END;
FUNCTION f_split_str(p_str VARCHAR2, p_division VARCHAR2, p_seq INT)
RETURN VARCHAR2 IS
v_first INT;
v_last INT;
BEGIN
IF p_seq < 1 THEN
RETURN NULL;
END IF;
IF p_seq = 1 THEN
IF instr(p_str, p_division, 1, p_seq) = 0 THEN
RETURN p_str;
ELSE
RETURN substr(p_str, 1, instr(p_str, p_division, 1) - 1);
END IF;
ELSE
v_first := instr(p_str, p_division, 1, p_seq - 1);
v_last := instr(p_str, p_division, 1, p_seq);
IF (v_last = 0) THEN
IF (v_first > 0) THEN
RETURN substr(p_str, v_first + 1);
ELSE
RETURN NULL;
END IF;
ELSE
RETURN substr(p_str, v_first + 1, v_last - v_first - 1);
END IF;
END IF;
END f_split_str;
PROCEDURE p_rows_column(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_cols IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc) IS
v_sql VARCHAR2(4000);
TYPE v_keep_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY BINARY_INTEGER;
v_keep v_keep_ind_by;
TYPE v_pivot_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY BINARY_INTEGER;
v_pivot v_pivot_ind_by;
v_keep_cnt INT;
v_pivot_cnt INT;
v_max_cols INT;
v_partition VARCHAR2(4000);
v_partition1 VARCHAR2(4000);
v_partition2 VARCHAR2(4000);
BEGIN
v_keep_cnt := length(p_keep_cols) - length(REPLACE(p_keep_cols, ',')) + 1;
v_pivot_cnt := length(p_pivot_cols) -
length(REPLACE(p_pivot_cols, ',')) + 1;
FOR i IN 1 .. v_keep_cnt LOOP
v_keep(i) := f_split_str(p_keep_cols, ',', i);
END LOOP;
FOR j IN 1 .. v_pivot_cnt LOOP
v_pivot(j) := f_split_str(p_pivot_cols, ',', j);
END LOOP;
v_sql := 'select max(count(*)) from ' || p_table || ' group by ';
FOR i IN 1 .. v_keep.LAST LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
v_sql := rtrim(v_sql, ',');
EXECUTE IMMEDIATE v_sql
INTO v_max_cols;
v_partition := 'select ';
FOR x IN 1 .. v_keep.COUNT LOOP
v_partition1 := v_partition1 || v_keep(x) || ',';
END LOOP;
FOR y IN 1 .. v_pivot.COUNT LOOP
v_partition2 := v_partition2 || v_pivot(y) || ',';
END LOOP;
v_partition1 := rtrim(v_partition1, ',');
v_partition2 := rtrim(v_partition2, ',');
v_partition := v_partition || v_partition1 || ',' || v_partition2 ||
', row_number() over (partition by ' || v_partition1 ||
' order by ' || v_partition2 || ') rn from ' || p_table;
v_partition := rtrim(v_partition, ',');
v_sql := 'select ';
FOR i IN 1 .. v_keep.COUNT LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
FOR i IN 1 .. v_max_cols LOOP
FOR j IN 1 .. v_pivot.COUNT LOOP
v_sql := v_sql || ' max(decode(rn,' || i || ',' || v_pivot(j) ||
',null))' || v_pivot(j) || '_' || i || ',';
END LOOP;
END LOOP;
IF p_where IS NOT NULL THEN
v_sql := rtrim(v_sql, ',') || ' from (' || v_partition || ' ' ||
p_where || ') group by ';
ELSE
v_sql := rtrim(v_sql, ',') || ' from (' || v_partition ||
') group by ';
END IF;
FOR i IN 1 .. v_keep.COUNT LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
v_sql := rtrim(v_sql, ',');
p_print_sql(v_sql);
OPEN p_refc FOR v_sql;
EXCEPTION
WHEN OTHERS THEN
OPEN p_refc FOR
SELECT 'x' FROM dual WHERE 0 = 1;
END;
PROCEDURE p_rows_column_real(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_col IN VARCHAR2,
p_pivot_val IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc) IS
v_sql VARCHAR2(4000);
TYPE v_keep_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY BINARY_INTEGER;
v_keep v_keep_ind_by;
TYPE v_pivot_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY BINARY_INTEGER;
v_pivot v_pivot_ind_by;
v_keep_cnt INT;
v_group_by VARCHAR2(2000);
BEGIN
v_keep_cnt := length(p_keep_cols) - length(REPLACE(p_keep_cols, ',')) + 1;
FOR i IN 1 .. v_keep_cnt LOOP
v_keep(i) := f_split_str(p_keep_cols, ',', i);
END LOOP;
v_sql := 'select ' || 'cast(' || p_pivot_col ||
' as varchar2(200)) as ' || p_pivot_col || ' from ' || p_table ||
' group by ' || p_pivot_col;
EXECUTE IMMEDIATE v_sql BULK COLLECT
INTO v_pivot;
FOR i IN 1 .. v_keep.COUNT LOOP
v_group_by := v_group_by || v_keep(i) || ',';
END LOOP;
v_group_by := rtrim(v_group_by, ',');
v_sql := 'select ' || v_group_by || ',';
FOR x IN 1 .. v_pivot.COUNT LOOP
v_sql := v_sql || ' max(decode(' || p_pivot_col || ',' || chr(39) ||
v_pivot(x) || chr(39) || ',' || p_pivot_val ||
',null)) as "' || v_pivot(x) || '",';
END LOOP;
v_sql := rtrim(v_sql, ',');
IF p_where IS NOT NULL THEN
v_sql := v_sql || ' from ' || p_table || p_where || ' group by ' ||
v_group_by;
ELSE
v_sql := v_sql || ' from ' || p_table || ' group by ' || v_group_by;
END IF;
p_print_sql(v_sql);
OPEN p_refc FOR v_sql;
EXCEPTION
WHEN OTHERS THEN
OPEN p_refc FOR
SELECT 'x' FROM dual WHERE 0 = 1;
END;
END;
/
3、多列转换成字符串
sql代码
CREATE TABLE t_col_str AS SELECT * FROM t_col_row;
SELECT * FROM t_col_str;
用||或concat函数可以实现
SELECT * FROM t_col_str;
SELECT ID, c1||','||c2||','||c3 AS c123 FROM t_col_str;
4、多行转换成字符串
未多行转换成字符串的效果:
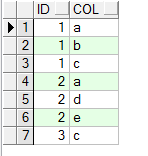
多行转换成字符串的效果:

CREATE TABLE t_row_str(
ID INT,
col VARCHAR2(10));
INSERT INTO t_row_str VALUES(1,'a');
INSERT INTO t_row_str VALUES(1,'b');
INSERT INTO t_row_str VALUES(1,'c');
INSERT INTO t_row_str VALUES(2,'a');
INSERT INTO t_row_str VALUES(2,'d');
INSERT INTO t_row_str VALUES(2,'e');
INSERT INTO t_row_str VALUES(3,'c');
COMMIT;
SELECT * FROM t_row_str;
1)MAX + decode–>适用范围:8i,9i,10g及以后版本
SELECT id,
MAX(decode(rn, 1, col, NULL)) ||
MAX(decode(rn, 2, ',' || col, NULL)) ||
MAX(decode(rn, 3, ',' || col, NULL)) str
FROM (SELECT id,
col,
row_number() over(PARTITION BY id ORDER BY col) AS rn
FROM t_row_str) t
GROUP BY id
ORDER BY 1;
2)row_number + lead–>适用范围:8i,9i,10g及以后版本
SELECT id, str
FROM (SELECT id,
row_number() over(PARTITION BY id ORDER BY col) AS rn,
col || lead(',' || col, 1) over(PARTITION BY id ORDER BY col) ||
lead(',' || col, 2) over(PARTITION BY id ORDER BY col) ||
lead(',' || col, 3) over(PARTITION BY id ORDER BY col) AS str
FROM t_row_str)
WHERE rn = 1
ORDER BY 1;
3)MODEL–>适用范围:10g及以后版本
SELECT id, substr(str, 2) str FROM t_row_str
MODEL
RETURN UPDATED ROWS
PARTITION BY(ID)
DIMENSION BY(row_number() over(PARTITION BY ID ORDER BY col) AS rn)
MEASURES (CAST(col AS VARCHAR2(20)) AS str)
RULES UPSERT
ITERATE(3) UNTIL( presentv(str[iteration_number+2],1,0)=0)
(str[] = str[] || ',' || str[iteration_number+1])
ORDER BY 1;
4)sys_connect_by_path–>适用范围:8i,9i,10g及以后版本
SELECT t.id id, MAX(substr(sys_connect_by_path(t.col, ','), 2)) str
FROM (SELECT id, col, row_number() over(PARTITION BY id ORDER BY col) rn
FROM t_row_str) t
START WITH rn = 1
CONNECT BY rn = PRIOR rn + 1
AND id = PRIOR id
GROUP BY t.id;
5)wmsys.wm_concat–>适用范围:10g及以后版本
这个函数预定义按','分隔字符串,若要用其他符号分隔可以用,replace将','替换。
SELECT id, REPLACE(wmsys.wm_concat(col), ',', '/')
FROM t_row_str
GROUP BY id;
5、字符串转换成多列
其实际上就是一个字符串拆分的问题。
CREATE TABLE t_str_col AS
SELECT ID, c1||','||c2||','||c3 AS c123
FROM t_col_str;
SELECT * FROM t_str_col;
1)substr + instr–>适用范围:8i,9i,10g及以后版本
SELECT id,
c123,
substr(c123, 1, instr(c123 || ',', ',', 1, 1) - 1) c1,
substr(c123,
instr(c123 || ',', ',', 1, 1) + 1,
instr(c123 || ',', ',', 1, 2) - instr(c123 || ',', ',', 1, 1) - 1) c2,
substr(c123,
instr(c123 || ',', ',', 1, 2) + 1,
instr(c123 || ',', ',', 1, 3) - instr(c123 || ',', ',', 1, 2) - 1) c3
FROM t_str_col
ORDER BY 1;
2)regexp_substr–>正则表达式
适用范围:10g及以后版本
SELECT id,
c123,
rtrim(regexp_substr(c123 || ',', '.*?' || ',', 1, 1), ',') AS c1,
rtrim(regexp_substr(c123 || ',', '.*?' || ',', 1, 2), ',') AS c2,
rtrim(regexp_substr(c123 || ',', '.*?' || ',', 1, 3), ',') AS c3
FROM t_str_col
ORDER BY 1;
6.字符串转换成多行
CREATE TABLE t_str_row AS
SELECT id,
MAX(decode(rn, 1, col, NULL)) ||
MAX(decode(rn, 2, ',' || col, NULL)) ||
MAX(decode(rn, 3, ',' || col, NULL)) str
FROM (SELECT id,
col,
row_number() over(PARTITION BY id ORDER BY col) AS rn
FROM t_row_str) t
GROUP BY id
ORDER BY 1;
SELECT * FROM t_str_row;
1)UNION ALL
适用范围:8i,9i,10g及以后版本
SELECT id, 1 AS p, substr(str, 1, instr(str || ',', ',', 1, 1) - 1) AS cv
FROM t_str_row
UNION ALL
SELECT id,
2 AS p,
substr(str,
instr(str || ',', ',', 1, 1) + 1,
instr(str || ',', ',', 1, 2) - instr(str || ',', ',', 1, 1) - 1) AS cv
FROM t_str_row
UNION ALL
SELECT id,
3 AS p,
substr(str,
instr(str || ',', ',', 1, 1) + 1,
instr(str || ',', ',', 1, 2) - instr(str || ',', ',', 1, 1) - 1) AS cv
FROM t_str_row
ORDER BY 1, 2;
适用范围:10g及以后版本
SELECT id, 1 AS p, rtrim(regexp_substr(str||',', '.*?' || ',', 1, 1), ',') AS cv
FROM t_str_row
UNION ALL
SELECT id, 2 AS p, rtrim(regexp_substr(str||',', '.*?' || ',', 1, 2), ',') AS cv
FROM t_str_row
UNION ALL
SELECT id, 3 AS p, rtrim(regexp_substr(str||',', '.*?' || ',',1,3), ',') AS cv
FROM t_str_row
ORDER BY 1, 2;
适用范围:10g及以后版本
SELECT t.id,
c.lv AS p,
rtrim(regexp_substr(t.str || ',', '.*?' || ',', 1, c.lv), ',') AS cv
FROM (SELECT id,
str,
length(regexp_replace(str || ',', '[^' || ',' || ']', NULL)) AS cnt
FROM t_str_row) t
INNER JOIN (SELECT LEVEL lv FROM dual CONNECT BY LEVEL <= 5) c ON c.lv <= t.cnt
ORDER BY 1, 2;
4)Hierarchical + DBMS_RANDOM
适用范围:10g及以后版本
SELECT id,
LEVEL AS p,
rtrim(regexp_substr(str || ',', '.*?' || ',', 1, LEVEL), ',') AS cv
FROM t_str_row
CONNECT BY id = PRIOR id
AND PRIOR dbms_random.VALUE IS NOT NULL
AND LEVEL <=
length(regexp_replace(str || ',', '[^' || ',' || ']', NULL))
ORDER BY 1, 2;
5)Hierarchical + CONNECT_BY_ROOT
适用范围:10g及以后版本
SELECT id,
LEVEL AS p,
rtrim(regexp_substr(str || ',', '.*?' || ',', 1, LEVEL), ',') AS cv
FROM t_str_row
CONNECT BY id = connect_by_root id
AND LEVEL <=
length(regexp_replace(str || ',', '[^' || ',' || ']', NULL))
ORDER BY 1, 2;
6)MODEL
适用范围:10g及以后版本
SELECT id, p, cv FROM t_str_row
MODEL
RETURN UPDATED ROWS
PARTITION BY(ID)
DIMENSION BY( 0 AS p)
MEASURES( str||',' AS cv)
RULES UPSERT
(cv
[ FOR p
FROM 1 TO length(regexp_replace(cv[0],'[^'||','||']',null))
INCREMENT 1
] = rtrim(regexp_substr( cv[],'.*?'||',',1,cv(p)),','))
ORDER BY 1,2;
Oracle 行列转换总结的更多相关文章
- oracle 行列转换
oracle 行列转换列名如果是数字,用双引号包住 如下: -- 建表 create table workinfo(wid integer primary key,sid integer ,CON ...
- oracle行列转换函数的使用
oracle 10g wmsys.wm_concat行列转换函数的使用: 首先让我们来看看这个神奇的函数wm_concat(列名),该函数可以把列值以","号分隔起来,并显示成一行 ...
- Oracle行列转换的思考与总结
最近几天一直在弄Oracle-SQL的问题,涉及到了一些平时没有用到的东西,也因此而在这里郁闷了好久.现在问题得到了解决虽说不算完美.但是还是和大家一起分享一下. 行列转换之一:sum(case wh ...
- Oracle行列转换
一.建表与插入数据 1.1.建表 create table kecheng ( id NUMBER, name ), course ), score NUMBER ); insert into kec ...
- oracle行列转换总结-转载自ITPUB
原贴地址:http://www.itpub.net/thread-1017026-1-1.html 谢谢原贴大人 最近论坛很多人提的问题都与行列转换有关系,所以我对行列转换的相关知识做了一个总结, 希 ...
- oracle 行列转换函数之WM_CONCAT和LISTAGG的使用(一)
一.wm_concat函数 wm_concat能够实现同样的功能,但是有时在11g中使用需要用to_char()进行转换,否则会出现不兼容现象(WMSYS.WM_CONCAT: 依赖WMSYS 用户, ...
- [Oracle]行列转换(行合并与拆分)
使用wmsys.wm_concat 实现行合并 在 Oracle 中, 将某一个栏位的多行数据转换成使用逗号风格的一行显示.能够使用函数 wmsys.wm_concat 达成. 这个在上一篇 or ...
- oracle 行列转换的运用
问题: 员工表: A(E_ID,NAME,) 部门表: B(D_ID,D_NAME) 员工与部门关系:C(ID,E_ID,D_ID) SELECT A.E_ID,A.NAME ,B.D_NAME ...
- Oracle行列转换case when then方法案例
select (select name from t_area where id=areaid) 区域, end) 一月, end) 二月, end) 三月, end) 四月, end) 五月, en ...
随机推荐
- Django进阶(转载)
Django进阶地址 来自为知笔记(Wiz)
- [CentOS]使用yum命令报出Error: Cannot retrieve repository metadata (repomd.xml) for repository的解决方法
在一次错误的repo文件rpm -i 之后,执行yum就开始报出 Error: Cannot retrieve repository metadata (repomd.xml) for reposit ...
- winfrom 右下角弹窗(渐渐消失)
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- C#图片缩放平移 —— 从功能分析到编码实现
序 一直都是在看别人的博客,查到想要的,看完后把页面一关就万事大吉了,没啥感觉:直到后来遇到了同样的问题,总想不起来咋弄,关键是还查不到以前看过的,郁闷!现在想想,还是“好记性不如烂笔头”啊,自己弄过 ...
- 从哈希结构去理解PHP数组
php的数组实际上就是hash_table,无论是 数字索引数组array(1, 2, 3) 还是关联数组array(1 => 2, 2=> 4)等等. 一,这里的hash_table有几 ...
- mysqli扩展库---------预处理技术
1, PHP程序与mysql之间处理sql语句流程如下,减少执行时间方式有三种: ① 减少php发送sql次数: ② 减少php与mysql之间网络传输时间: ③ 减少mysql的编译时间: 2, 预 ...
- [Flex] 组件Tree系列 —— 支持元素的拖放排序
mxml: <?xml version="1.0" encoding="utf-8"?> <!--功能描述:支持元素拖放排序--> &l ...
- [Flex] FlashBuilder 4.6运用标签嵌入字体方法
<?xml version="1.0" encoding="utf-8"?> <s:Application xmlns:fx="ht ...
- Windows下磁盘无损重新分配
打开百度(www.baidu.com),找到我们的分区助手.exe 单击“普通下载”,会下载一个安装包. 这时候,我们进行安装.安装完成如下. 对着那个盘容量较大的盘右键,分配空闲空间. 服务器多次重 ...
- this指向的一个小总结
凡是在函数内部调用的函数的this的指向都是window 定时器,延时器this的指向都是window 在事件中一般情况下this的指向都指向当前的DOM对象 在对象函数中this的指向一般情况下都指 ...