Apriori算法详解
一、Apriori 算法概述
Apriori 算法是一种最有影响力的挖掘布尔关联规则的频繁项集的 算法,它是由Rakesh Agrawal 和RamakrishnanSkrikant 提出的。它使用一种称作逐层搜索的迭代方法,k- 项集用于探索(k+1)- 项集。首先,找出频繁 1- 项集的集合。该集合记作L1。L1 用于找频繁2- 项集的集合 L2,而L2 用于找L2,如此下去,直到不能找到 k- 项集。每找一个 Lk 需要一次数据库扫描。为提高频繁项集逐层产生的效率,一种称作Apriori 性质的重 要性质 用于压缩搜索空间。其运行定理在于一是频繁项集的所有非空子集都必须也是频繁的,二是非频繁项集的所有父集都是非频繁的。
二、问题的引入
购物篮分析:引发性例子
Question:哪组商品顾客可能会在一次购物时同时购买?
关联分析
Solutions:
1:经常同时购买的商品可以摆近一点,以便进一步刺激这些商品一起销售。
2:规划哪些附属商品可以降价销售,以便刺激主体商品的捆绑销售。
三、关联分析的基本概念
1、支持度
关联规则A->B的支持度support=P(AB),指的是事件A和事件B同时发生的概率。
2、置信度
置信度confidence=P(B|A)=P(AB)/P(A),指的是发生事件A的基础上发生事件B的概率。比如说在规则Computer => antivirus_software , 其中 support=2%, confidence=60%中,就表示的意思是所有的商品交易中有2%的顾客同时买了电脑和杀毒软件,并且购买电脑的顾客中有60%也购买了杀毒软件。
3、k项集
如果事件A中包含k个元素,那么称这个事件A为k项集,并且事件A满足最小支持度阈值的事件称为频繁k项集。
4、由频繁项集产生强关联规则
1)K维数据项集LK是频繁项集的必要条件是它所有K-1维子项集也为频繁项集,记为LK-1
2)如果K维数据项集LK的任意一个K-1维子集Lk-1,不是频繁项集,则K维数据项集LK本身也不是最大数据项集。
3)Lk是K维频繁项集,如果所有K-1维频繁项集合Lk-1中包含LK的K-1维子项集的个数小于K,则Lk不可能是K维最大频繁数据项集。
4)同时满足最小支持度阀值和最小置信度阀值的规则称为强规则。
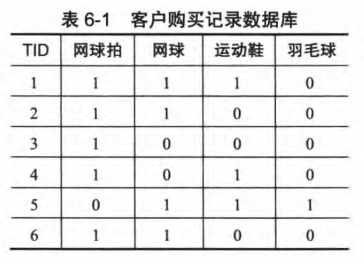
例如:用一个简单的例子说明。表6-1是顾客购买记录的数据库D,包含6个事务。项集I={网球拍,网球,运动鞋,羽毛球}。考虑关联规则:网球拍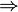 网球,事务1,2,3,4,6包含网球拍,事务1,2,6同时包含网球拍和网球,支持度
网球,事务1,2,3,4,6包含网球拍,事务1,2,6同时包含网球拍和网球,支持度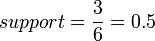 ,置信度
,置信度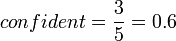 。若给定最小支持度
。若给定最小支持度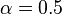 ,最小置信度
,最小置信度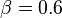 ,关联规则网球拍网球是有趣的,认为购买网球拍和购买网球之间存在强关联。
,关联规则网球拍网球是有趣的,认为购买网球拍和购买网球之间存在强关联。
四、Apriori算法的基本思想:
Apriori算法过程分为两个步骤:
第一步通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;
第二步利用频繁项集构造出满足用户最小信任度的规则。
具体做法就是:
首先找出频繁1-项集,记为L1;然后利用L1来产生候选项集C2,对C2中的项进行判定挖掘出L2,即频繁2-项集;不断如此循环下去直到无法发现更多的频繁k-项集为止。每挖掘一层Lk就需要扫描整个数据库一遍。算法利用了一个性质:
Apriori 性质:任一频繁项集的所有非空子集也必须是频繁的。意思就是说,生成一个k-itemset的候选项时,如果这个候选项有子集不在(k-1)-itemset(已经确定是frequent的)中时,那么这个候选项就不用拿去和支持度判断了,直接删除。具体而言:
1) 连接步
为找出Lk(所有的频繁k项集的集合),通过将Lk-1(所有的频繁k-1项集的集合)与自身连接产生候选k项集的集合。候选集合记作Ck。设l1和l2是Lk-1中的成员。记li[j]表示li中的第j项。假设Apriori算法对事务或项集中的项按字典次序排序,即对于(k-1)项集li,li[1]<li[2]<……….<li[k-1]。将Lk-1与自身连接,如果(l1[1]=l2[1])&&( l1[2]=l2[2])&&……..&& (l1[k-2]=l2[k-2])&&(l1[k-1]<l2[k-1]),那认为l1和l2是可连接。连接l1和l2 产生的结果是{l1[1],l1[2],……,l1[k-1],l2[k-1]}。
2) 剪枝步
CK是LK的超集,也就是说,CK的成员可能是也可能不是频繁的。通过扫描所有的事务(交易),确定CK中每个候选的计数,判断是否小于最小支持度计数,如果不是,则认为该候选是频繁的。为了压缩Ck,可以利用Apriori性质:任一频繁项集的所有非空子集也必须是频繁的,反之,如果某个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从而可以将其从CK中删除。
五、实例说明
实例一:下面以图例的方式说明该算法的运行过程: 假设有一个数据库D,其中有4个事务记录,分别表示为:

这里预定最小支持度minSupport=2,下面用图例说明算法运行的过程:
1、扫描D,对每个候选项进行支持度计数得到表C1:

2、比较候选项支持度计数与最小支持度minSupport,产生1维最大项目集L1:

3、由L1产生候选项集C2:

4、扫描D,对每个候选项集进行支持度计数:

5、比较候选项支持度计数与最小支持度minSupport,产生2维最大项目集L2:

6、由L2产生候选项集C3:

7、比较候选项支持度计数与最小支持度minSupport,产生3维最大项目集L3:

算法终止。
实例二:下图从整体同样的能说明此过程:

此例的分析如下:
PS
从算法的运行过程,我们可以看出该Apriori算法的优点:简单、易理解、数据要求低,然而我们也可以看到Apriori算法的缺点:
(1)在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;
(2)每次计算项集的支持度时,都对数据库D中的全部记录进行了一遍扫描比较,如果是一个大型的数据库的话,这种扫描比较会大大增加计算机系统的I/O开销。而这种代价是随着数据库的记录的增加呈现出几何级数的增加。因此人们开始寻求更好性能的算法。
六、改进Apriori算法的方法
方法1:基于hash表的项集计数
将每个项集通过相应的hash函数映射到hash表中的不同的桶中,这样可以通过将桶中的项集技术跟最小支持计数相比较先淘汰一部分项集。
方法2:事务压缩(压缩进一步迭代的事务数)
不包含任何k-项集的事务不可能包含任何(k+1)-项集,这种事务在下一步的计算中可以加上标记或删除
方法3:划分
挖掘频繁项集只需要两次数据扫描
D中的任何频繁项集必须作为局部频繁项集至少出现在一个部分中。
第一次扫描:将数据划分为多个部分并找到局部频繁项集
第二次扫描:评估每个候选项集的实际支持度,以确定全局频繁项集。
方法4:选样(在给定数据的一个子集挖掘)
基本思想:选择原始数据的一个样本,在这个样本上用Apriori算法挖掘频繁模式
通过牺牲精确度来减少算法开销,为了提高效率,样本大小应该以可以放在内存中为宜,可以适当降低最小支持度来减少遗漏的频繁模式
可以通过一次全局扫描来验证从样本中发现的模式
可以通过第二此全局扫描来找到遗漏的模式
方法5:动态项集计数
在扫描的不同点添加候选项集,这样,如果一个候选项集已经满足最少支持度,则在可以直接将它添加到频繁项集,而不必在这次扫描的以后对比中继续计算。
PS:Apriori算法的优化思路
1、在逐层搜索循环过程的第k步中,根据k-1步生成的k-1维频繁项目集来产生k维候选项目集,由于在产生k-1维频繁项目集时,我们可以实现对该集中出现元素的个数进行计数处理,因此对某元素而言,若它的计数个数不到k-1的话,可以事先删除该元素,从而排除由该元素将引起的大规格所有组合。
这是因为对某一个元素要成为K维项目集的一元素的话,该元素在k-1阶频繁项目集中的计数次数必须达到K-1个,否则不可能生成K维项目集(性质3)。
2、根据以上思路得到了这个候选项目集后,可以对数据库D的每一个事务进行扫描,若该事务中至少含有候选项目集Ck中的一员则保留该项事务,否则把该事物记录与数据库末端没有作删除标记的事务记录对换,并对移到数据库末端的事务记录作删除标一记,整个数据库扫描完毕后为新的事务数据库D’ 中。
因此随着K 的增大,D’中事务记录量大大地减少,对于下一次事务扫描可以大大节约I/0 开销。由于顾客一般可能一次只购买几件商品,因此这种虚拟删除的方法可以实现大量的交易记录在以后的挖掘中被剔除出来,在所剩余的不多的记录中再作更高维的数据挖掘是可以大大地节约时间的。
实例过程如下图:


当然还有很多相应的优化算法,比如针对Apriori算法的性能瓶颈问题-需要产生大量候选项集和需要重复地扫描数据库,2000年Jiawei Han等人提出了基于FP树生成频繁项集的FP-growth算法。该算法只进行2次数据库扫描且它不使用侯选集,直接压缩数据库成一个频繁模式树,最后通过这棵树生成关联规则。研究表明它比Apriori算法大约快一个数量级。
Apriori算法详解的更多相关文章
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
- EM算法详解
EM算法详解 1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成 ...
- Tarjan算法详解
Tarjan算法详解 今天偶然发现了这个算法,看了好久,终于明白了一些表层的知识....在这里和大家分享一下... Tarjan算法是一个求解极大强联通子图的算法,相信这些东西大家都在网络上百度过了, ...
- 安全体系(二)——RSA算法详解
本文主要讲述RSA算法使用的基本数学知识.秘钥的计算过程以及加密和解密的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 1.概述 ...
随机推荐
- shell中的死记硬背
一.shell的引号们 1."" -> 双引号(不保留完整内容,比如遇到$, 反引号, \ 等就会执行相应的shell) echo "Today is `date` ...
- HDOJ:6333-Problem B. Harvest of Apples(组合数学+莫队算法+逆元)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6333 解题心得: 这个题可以说是十分精彩了,首先推组合数学的公式,其中一个很重要的公式是Cnm = C ...
- 【8086汇编-Day7】关于多个段的程序的实验
实验一 实验二 实验三 实验四 实验五 实验六 总结 在集成环境下,内存从0770段开始按照段的先后顺序和内容多少分配,并且分配的都是16的倍数 关于实际占用的空间公式的话其实极容易想到(假设有N个字 ...
- python--模块之time,datetime时间模块
time: 表示时间的三种方式:时间戳.格式化的时间字符串.元组时间戳是计算机能够识别的时间:时间字符串是我们能够看懂的时间:元组是用来操作时间: 导入时间模块import time 1,时间戳(ti ...
- 北京Uber优步司机奖励政策(1月29日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 北京Uber优步司机奖励政策(11月23日~11月29日)
用户组:人民优步"关羽组"(适用于11月23日-11月29日)奖励政策: 滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最 ...
- 成都Uber优步司机奖励政策(3月16日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 厦门Uber优步司机奖励政策(12月14日到12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- (转)Gmail,你必须了解的12个邮件编码问题
转载地址:http://www.maildesign.cn/archives/1537 1.Gmail 不支持style=” display:none”2.Gmail不支持内嵌式CSS样式3.Gmai ...
- PS 给天空添加蓝天白云<转载>
https://jingyan.baidu.com/article/b2c186c8e83b1cc46ef6ffee.html 给图片添加蓝天白云的步骤: 1.打开要加蓝天白云的照片.(如图一) [图 ...