nltk模块
1. nltk简介
http://www.nltk.org
2. nltk能做什么?
2.1 搜索文本
- 单词搜索
- 相似词搜索
- 相似关键词识别
- 词汇分布图
- 生成文本
from nltk.book import * # 词语搜索
print('搜索词monstrous->')
text1.concordance('monstrous') print('上下文相似词->')
# 上下文相似词, 没有返回值
text2.similar('monstrous') # 共同上下文
print('monstrous, very共同上下文')
text2.common_contexts(['monstrous', 'very']) # 词汇分布表
text4.dispersion_plot(['citizens', 'democracy', 'freedom', 'duties', 'America']) # 词数统计
len(text3) # 出现的不重复词语的词数
len(set(text3)) # 排序
sorted(set(text3)) # 重复词密度
from __future__ import division
len(text3) / len(set(text3)) # 关键词密度
text3.count('smote')
100 * text4.count('a') / len(text4) # 平均词密度, 平均每个词出现的词数
def lexical_diversity(text):
return len(text) / len(set(text)) lexical_diversity(text1)
2.2 计数词汇
3. 词链表
print(sent1) # ['Call', 'me', 'Ishmael', '.']
print(sent1[1:3])
3.1 词频分布
nltk内置的统计类:FeDist
fdist = FreqDist(text1)
print(fdist)

# 频率累计分布图
fdist.plot(50, cumulative=True)
频率累计分布图:

丢弃高频且没有意义的词,或者是抽取具有P特性(例如词的长度大于15)的词汇。
# 细粒度的选择词
V = set(text5)
long_words = [w for w in V if len(w) >= 15]
sorted(long_words) # 综合词的长度和词频,进行筛选
sorted([w for w in set(text5) if len(w) > 7 and fdist[w] > 7])

词语搭配:
from nltk.util import bigrams # 二元语法, trigrams 三元语法
list(bigrams(['more', 'is', 'said', 'than', 'done'])) # [('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')]
# 经常出现的双联次
text1.collocations()
词长分布,对作者的文章也是有影响的:
# 词长分布
fdist = FreqDist([len(w) for w in text1]) fdist.items()
# dict_items([(1, 47933), (4, 42345), (2, 38513), (6, 17111), (8, 9966), (9, 6428), (11, 1873), (5, 26597), (7, 14399), (3, 50223), (10, 3528), (12, 1053), (
# 13, 567), (14, 177), (16, 22), (15, 70), (17, 12), (18, 1), (20, 1)])
4. 自然语言处理(NLP)
自然语言:自然的随着文化演化的语言,就是人们日常使用的语言。
自然语言处理:用计算机对自然语言进行操作。
自然语言研究的内容:
- 此意消岐
- 指代理解
- 自动生成语言
- 机器翻译
- 人机对话系统
- 文本含义识别
5. nltk语料库
end
nltk模块的更多相关文章
- nltk模块基础操作
几个基础函数 (1)搜索文本:text.concordance(word) 例如,在text1中搜索词”is”在文本中出现的次数以及上下文的词:text1.concordance("is& ...
- 【NLP】Python NLTK 走进大秦帝国
Python NLTK 走进大秦帝国 作者:白宁超 2016年10月17日18:54:10 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公 ...
- 自然语言处理(1)之NLTK与PYTHON
自然语言处理(1)之NLTK与PYTHON 题记: 由于现在的项目是搜索引擎,所以不由的对自然语言处理产生了好奇,再加上一直以来都想学Python,只是没有机会与时间.碰巧这几天在亚马逊上找书时发现了 ...
- NLTK 3.2.2 安装经验
NLTK 3.2.2 安装经验 Nltk 3.2.2要求Python版本是Python2.7 或者Python3.4+. Nltk 3.2.3 如果是从网站上直接下载程序进行安装可能会报错:Pytho ...
- NLP入门(三)词形还原(Lemmatization)
词形还原(Lemmatization)是文本预处理中的重要部分,与词干提取(stemming)很相似. 简单说来,词形还原就是去掉单词的词缀,提取单词的主干部分,通常提取后的单词会是字典中的单 ...
- zwPython,字王集成式python开发平台,比pythonXY更强大、更方便。
zwPython,字王集成式python开发平台,比pythonXY更强大.更方便. 更强大,内置opencv.cuda/opencl.NLTK自然语言.pygame游戏设计等多个重量级模块库. 更方 ...
- 深度学习之 TensorFlow(一):基础库包的安装
1.TensorFlow 简介:TensorFlow 是谷歌公司开发的深度学习框架,也是目前深度学习的主流框架之一. 2.TensorFlow 环境的准备: 本人使用 macOS,Python 版本直 ...
- 词义消除歧义NLP项目实验
词义消除歧义NLP项目实验 本项目主要使用https://github.com/alvations/pywsd 中的pywsd库来实现词义消除歧义 目前,该库一部分已经移植到了nltk中,为了获得更好 ...
- NLP(一)
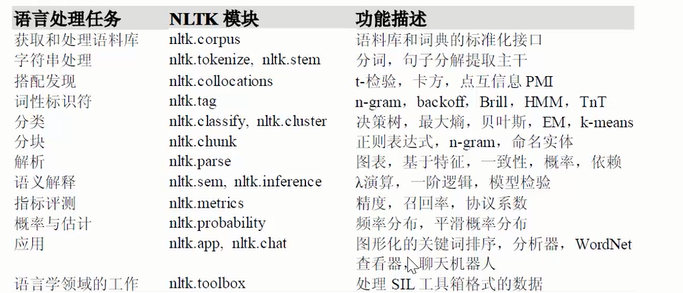
“自然语言处理”(Natural Language Processing 简称 NLP)包含所有用计算机对自然语言进行的操作. 自然语言工具包(NLTK) 语言处理任务与相应 NLTK 模块以及功能描 ...
随机推荐
- “全栈2019”Java第七十四章:内部类与静态内部类相互嵌套
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- myeclipse部署项目到tomcat-custom_location 方式
在想要部署的路径下:1.新建一个在tomcat--->server.xml文件夹下设置的文件名 2.在新建的文件夹下新建一个 ROOT文件夹, 3.在myeclipse里面吧项目部署到 ROO ...
- Java-代理模式的理解
引言 设计模式是语言的表达方式,它能让语言轻便而富有内涵.易读却功能强大.代理模式在Java中十分常见,有为扩展某些类的功能而使用静态代理,也有如Spring实现AOP而使用动态代理,更有RPC实现中 ...
- Linux 内存监控
1.按照内存使用方式排序 top 之后使用 shift + m 那么top按照内存使用从大到小进行排列,使用 shift + P 表示按照CPU进行排序. bigfish 1118m 438m 30m ...
- 用API爬取天气预报数据
1.注册免费API和阅读技术文档: 注册地址:https://console.heweather.com 文档地址:https://www.heweather.com/documents/api-ur ...
- CentOS 7 查看和设置防火墙状态
CentOS7 默认使用的是firewall作为防火墙 查看防火墙状态 firewall-cmd --state 停止firewall systemctl stop firewalld.service ...
- linux的sed(增删改查)使用方法
sed的增删改查的基本操作 参考:https://www.cnblogs.com/0zcl/p/6855740.html 01:增(a) 2个sed命令,分别是:(这些操作都是在内存中进行的,所以不会 ...
- linux ssh 上传 文件
在linux下一般用scp这个命令来通过ssh传输文件. 1.从服务器上下载文件scp username@servername:/path/filename /var/www/local_dir(本地 ...
- 基础篇:3)规范化:3d制图总章
本章目的:明确3d绘图也有相应的准则,遵守者方有相应的进阶之路. 1.建模目标:拥有自己的建模思想 学习完成3d制图,最直接的评价标准就是--拥有自己的建模思想. 其表现为: 1)建模思路明确,能独立 ...
- https迁移实践手记
前言什么是公钥和私钥?使用OpenssL生成私钥.使用Keytool导出私钥.主流数字证书都有哪些格式?SSL证书类型注册SSL证书使用OpenSSL工具生成CSR文件使用keytool工具生成CSR ...