云HBase备份恢复,为云HBase数据安全保驾护航
摘要: 介绍了阿里云HBase自研备份恢复功能的基本背景以及基本原理架构和基本使用方法。
云HBase发布备份恢复功能,为用户数据保驾护航。对大多数公司来说数据的安全性以及可靠性是非常重要的,如何保障数据的安全以及数据的可靠是大多数数据库必须考虑的。2016 IDC的报告表示数据的备份(data-protection)和数据恢复(retention)是Nosql的最基础的需求之一。
为什么需要云HBase备份恢复?
我们希望云HBase支持备份和恢复功能,主要原因:
- 用户直接访问操作数据库,可能存在安全风险;
- 项目存在合规以及监管的强需求;
- 对数据库恢复数据到任意时间点(归档到任意时间点)需求;
- HBase社区至今没有release备份恢复功能。
1、用户直接访问数据库,存在安全风险
用户通过接口直接访问HBase数据库,这种情况下存在安全隐患的概率会比较大。一种可能性是黑客会通过黑客技术入侵数据库,对用户的数据进行肆意的“操作”,造成用户数据无法访问,然后进行勒索,参考前段时间的某某某数据库勒索事件。当然这种case 在阿里云相关数据库上是不会发生的,我们的数据库有一些安全机制进行守护,且云HBase自己也有自己的安全机制进行保障。
另外一种潜在的安全隐患就是:由于用户自己的误操作造成的数据丢失或者数据库不可访问,比如我们之前经常听到的“某某DBA由于误操作,造成数据库数据被物理删除,无法恢复,造成公司损失”等等等消息。
上述两种情况如果数据有备份的话,可以把备份的数据恢复回来,即可避免以上风险。
2、合规以及监管需求
这种情况主要存在于一些特殊的项目中。由于数据的重要性或其他原因,会有监管的部门对数据是否做备份进行合规检查。比如我们曾经遇到的汽车行业的某公司,因为其每辆汽车数据的重要性,需要对这些车辆数据做实时备份,且这些数据如果存在大面积丢失则会直接带来监管审查问题。对于这种有监管需求的项目,备份恢复是必不可少的。
3、数据库恢复到任意时间点需求
对数据库的数据归档到过去某一时间点也是对备份恢复的一个比较强烈的需求。假如测试脚本意外写入生产环境下的云HBase表中,那么会造成很多无效的数据产生,对于这种过去一段时间存在无效数据,不仅占用存储空间且不方便删除的情况,使用数据库的PITR能力可以将数据库数据做一种“清洗”,将数据恢复到产生无效数据之前。这里需要说一下,云HBase的恢复暂时只能支持恢复到过去10天内的时间点,且时间点的精确度是小时级别,暂时不能很精确的细化。
4、HBase社区至今没有release备份恢复功能
HBase社区官方到现在没有对外发布过稳定的备份恢复功能,官方建议的备份操作的方式在生产环境是不适合执行的。所以云HBase提供一个稳定的备份恢复功能弥补了HBase社区在该方面的欠缺,也为广大HBase用户提供了一个选择。
云HBase备份恢复:赋能HBase备份恢复能力
云HBase备份恢复的设计之初的目的就是:赋能云HBase备份恢复的能力、百T级别(起)数据量备份恢复支持、低用户使用门槛、高性能、低备份成本、支持冷热分离、兼容HBase2.0/1.x、备份集备份、恢复以及增量备份、时间点恢复等。
传统数据库备份恢复的能力都是TB级别,在交易等场景下面是足够的,但面向大数据场景就捉襟见肘了。云HBase通过垂直整合高压缩、内核级优化等能力,将备份恢复的量级成功推高百倍以上,做到 百TB级别甚至更高 ,让客户在大数据量场景下也无后顾之忧。
我们最终给出如下架构:一种包含了全量(备份集)备份、全量(备份集)恢复、增量(实时)备份、增量(时间点)恢复几个模块,接下来就这几个模块进行介绍;
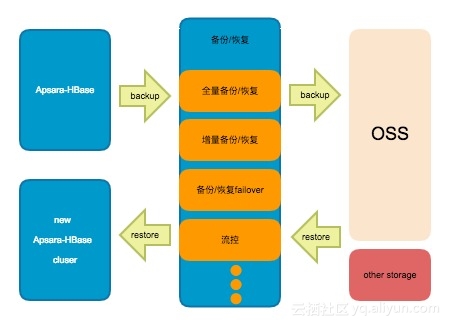
备份数据
备份数据分为2部分:开启备份动作时间点前的存量数据,通过Hfile的形式进行读取以及备份到目的端;时间点以及以后写入的实时数据,会以Hlog的形式被读取以及备份到远端。这里备份的远端默认选择是OSS,因为其具有11个9的数据可靠性,以及低成本等特点。上述存量数据的备份(备份集备份)会周期性的触发,暂定周期是一周;实时产生的数据(实时备份)会及时的备份到远端OSS。OSS上的数据,我们会相应保留2个周期,这样做主要是为了清理冗余数据。
备份数据过程中,通过调整流量控制,可以将备份带来的影响降低到极低的一个程度。无论是备份集备份还是实时备份,通过failover、takeover等机制,可以保证即使某些备份进程异常,数据依旧可以被备份到远端,这里可以承诺做到小时级别的备份精确度。此外备份过程中,通过将备份数据备份流量均匀分摊到集群中的各个机器,可以保证最高的备份效率,通过分布式的备份进而支持备份规模达到百T甚至更高级别,即只要你敢存,我们就敢备份。
恢复数据
从产品层面来看,如果用户执行恢复集群操作的话,云HBase会将数据恢复到一个全新的集群。这么做的目的是,尽可能的保证不侵入用户数据,守护最后一道数据底线,如果数据恢复完成,对于原的集群,用户可以自行处理。
数据恢复主要是将用户的数据,从远端(默认OSS)进行下载,其中包括存量的Hfile 数据以及增量的Hlog数据两部分。那么存量的Hfile数据,通过各个机器均衡下载,并各个机器执行bulkload,保证较快速的将存量数据恢复。对于Hlog 数据,同样做到分布式下载,各个机器回放相关的Hlog。通过充分利用各个机器的资源,将恢复速度做到最优。
恢复支持备份集恢复以及时间点恢复,如果用户想恢复到过去某一个具体时间段的数据,那么在页面选择一下相应时间段,点击恢复即可。
一些指标
经过我们的理论分析以及实际测试(8C32G,8Tx10),给出下列数据指标:
1. 备份数据量可以达到百T级别甚至更高;
2. 备份集备份最长4天,正常情况远小于4天;
3. 备份集恢复最长1天半;
4. 日志恢复数据精确度:1hour,最长容忍一小时的数据不准确;
上述第4点解释下:所谓的恢复精确度是如果用户想要将数据恢复到最新的一个时间点,恢复到的数据存在与需求的最新时间点数据最多一小时的误差,其他的恢复是没问题的,但是实际我们测试的情况远小于这个时间。
由于分布式备份,同等数据量下备份以及恢复速度是传统数据库的数倍。备份数据量、备份/恢复速度会随着机器数量的扩容而不断的增大。举个例子同样备份2T数据,传统数据库如果需要24小时,那么我们可以保证备份速度可以保证小于等于12小时。
云HBase和自建的区别
HBase社区到目前为止没有release备份恢复功能,官网只介绍了如果要做备份需要的操作流程参考link,可以通过export做备份;此外社区有一个分支包含备份恢复功能,见link,但该分支开发好几年,release时间未知,且版本不稳定;在这里大概列一下云HBase备份恢复和自建的区别;
| 云HBase | 自建HBase | |
|---|---|---|
| 备份恢复操作 | 操作简单,点击按钮即可 | 操作复杂,需要手工触发命令执行 |
| 备份过程是否依赖别的组件 | 依赖产品化组件,但是用户无感知,无需用户操作 | 依赖MapReduce,需要用户搭建或者部署 |
| 最长备份精确度时间保证 | 1小时 | 不确定 |
| 是否保证备份进程异常情况下的数据备份 | 有 | 没有 |
| 稳定性 | 多种数据量下反复测试,保证稳定性 | 社区方案,稳定性未知 |
| 流量控制 | 有 | export方案无、分支未release方案有 |
| 备份目的端数据冗余 | 会有一定少量冗余数据 | 存在较多冗余数据 |
| 备份时间保证 | 有最长时间保证 | 未知 |
如何进行备份以及恢复
备份恢复整个操作流程都是非常简单的界面化操作,一路点点点既可以完成整个操作。
执行备份
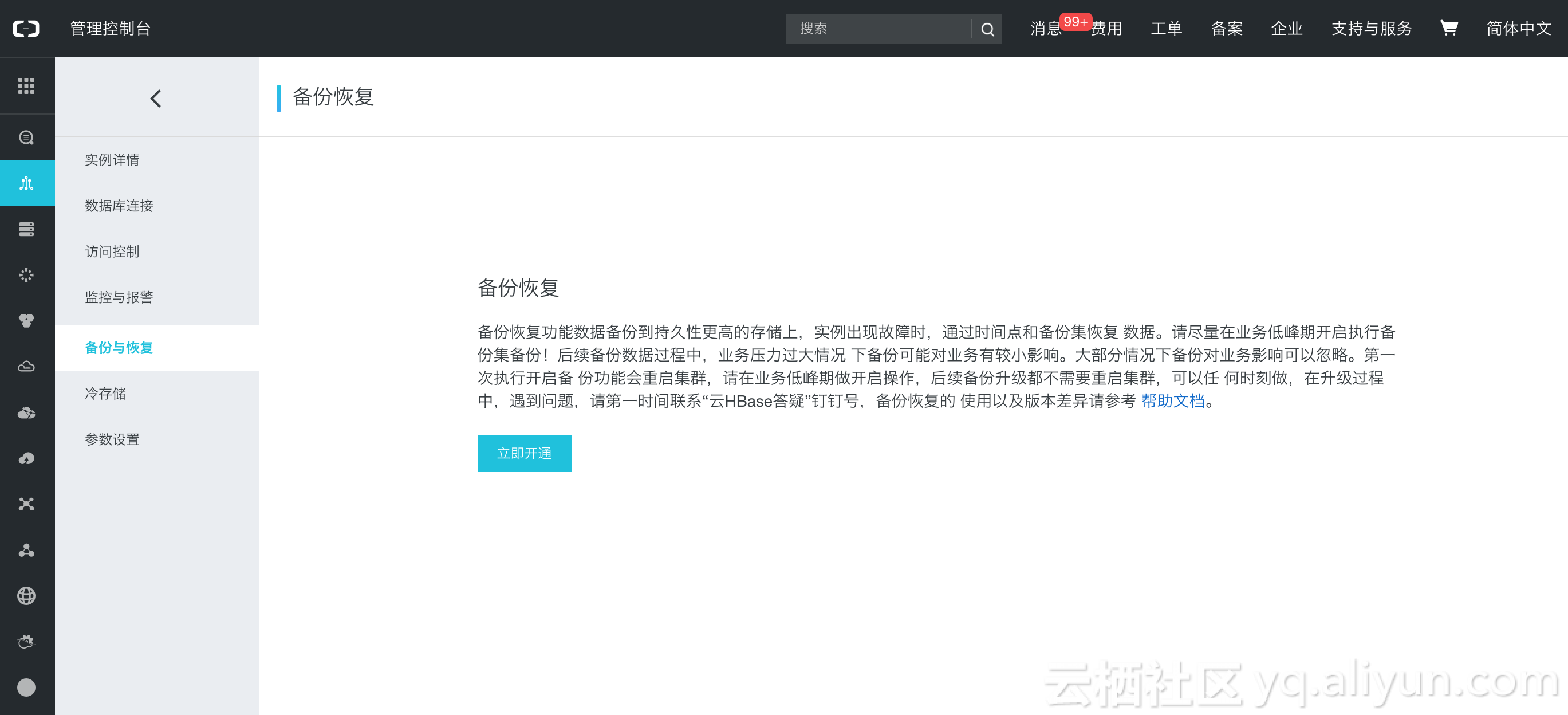
用户购买完成云HBase集群以后在自己的控制台左侧栏会看到“备份与恢复”选项栏,选择该栏目,然后出现备份恢复相关的选项,第一次执行备份会需要重启集群,建议用户在一个低峰期进行开启操作,开启备份操作可能需要几分钟,请用户耐心等待。点击开启备份恢复以后,按照对应的选项指导 用户可以选择备份集备份的时间点,选择完成以后,就会周期性的在这个时刻触发一次备份集备份,至于实时数据备份在第一次开启备份的时候就触发了。
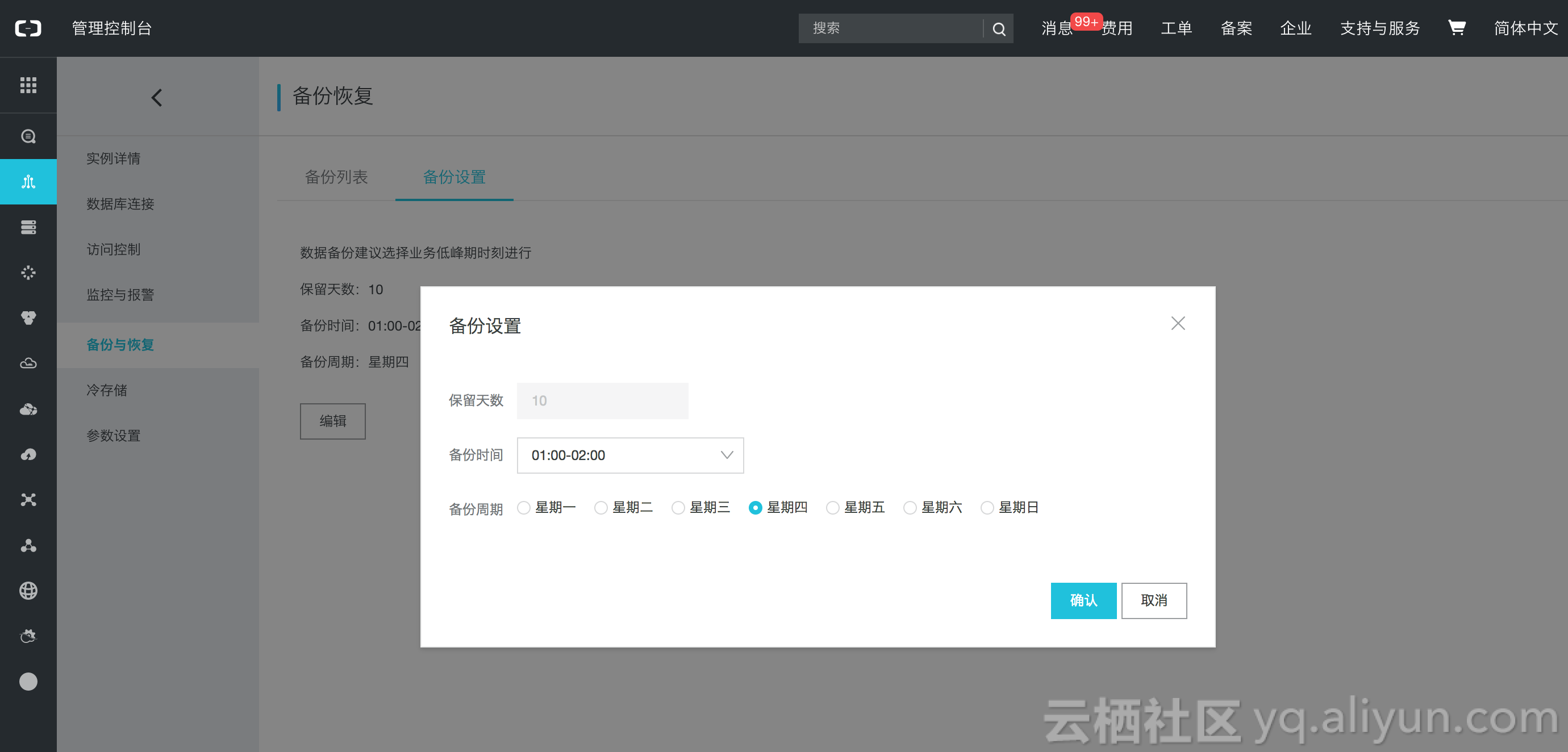
完成上述设置以后,我们整个备份操作即可正常开启以及执行了。
执行恢复
云HBase的恢复包括备份集恢复以及时间点恢复。备份集恢复即恢复到过去执行的某一次备份集备份的数据,而时间点恢复即用户可以选择某一个特定的时间段(小时级别),然后云HBase的恢复程序即可将数据恢复到对应的时间点。无论是备份集恢复还是时间点恢复都是将数据恢复到一个新的集群。
选择是备份集恢复还是时间点恢复主要是在控制台页面选择:
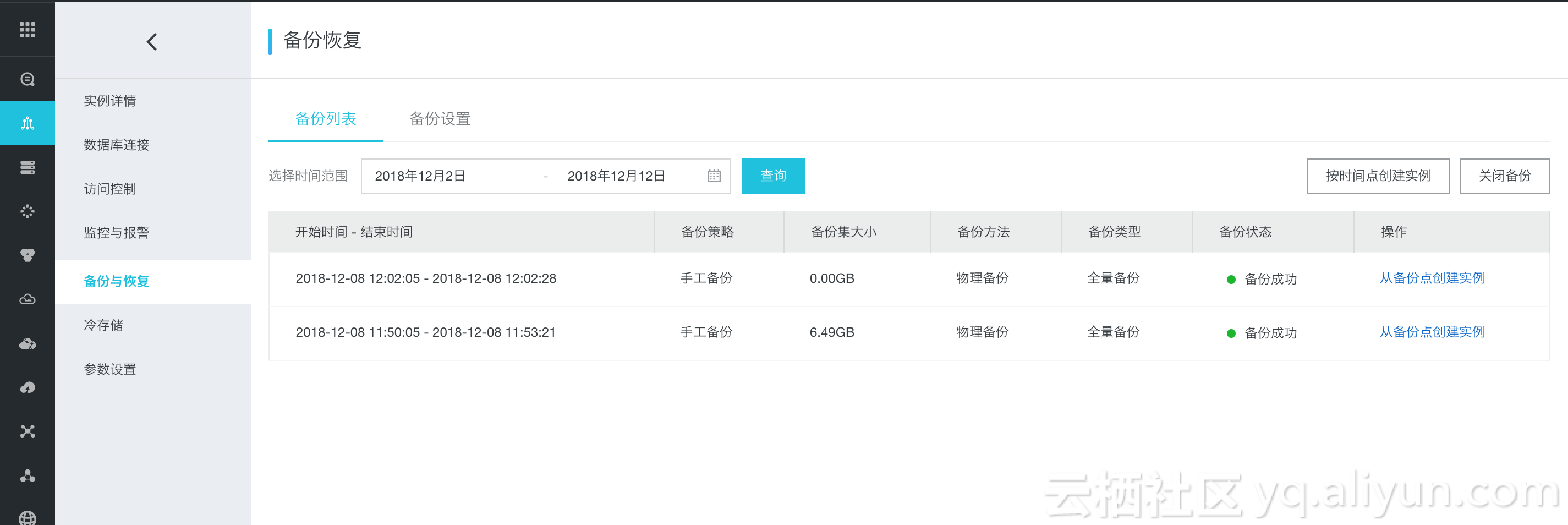
上述页面可以选择”备份点创建实列“,最后可以在下述页面选择具体的备份情况:
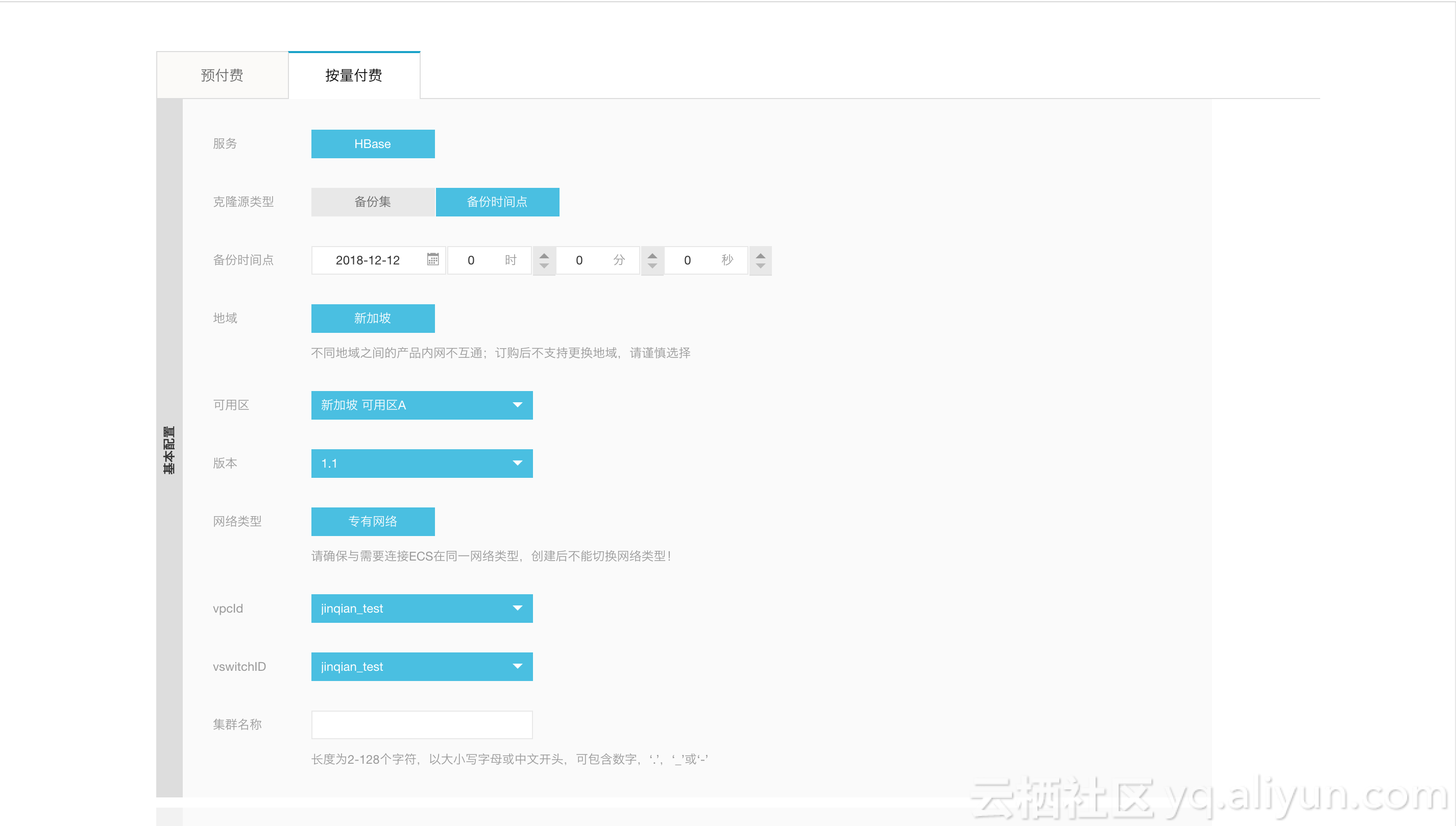
完成如上操作以后,恢复程序开始执行恢复,等数据恢复完成即可。
展望
后期我们的备份恢复会进一步深耕,继续做的更细致,由于现阶段我们的备份恢复只能达到集群级别的备份,那么接下来需要支持更细粒度的备份和恢复,暂定细化到表级别;此外,我们还希望备份恢复的精确度可以降低到秒级别,这个事情也是需要投入精力的;再次对应备份恢复的速度我们希望可以再进行优化。
产品入口:
链接:https://cn.aliyun.com/product/hbase
云HBase备份恢复使用文档
链接:https://help.aliyun.com/document_detail/68358.html?spm=a2c4g.11174283.6.585.5f113c2epivA3S
云HBase备份恢复,为云HBase数据安全保驾护航的更多相关文章
- HBase备份恢复练习
一.冷备 1.创建测试表并插入测试数据 [root@weekend05 ~]# hbase shell hbase(main):005:0> create 'scores','grade','c ...
- 阿里云RDS备份 恢复到本地
目录 一.恢复准备 二.具体操作 一.恢复准备 阿里云RDS默认配置了全备份+binlog,可以精准恢复到某个时间点上. 可以下载备份的包到本地,进行本地恢复,要预留好本地的数据库容量和cpu等规格, ...
- 云与备份之(1):VMware虚机备份和恢复
本系列文章会介绍云与备份之间的关系,包括: (1)VMware 虚机备份和恢复 (2)KVM 虚机备份和恢复 (3)云与备份 (4)OpenStack 与备份 (5)公有云与备份 1. 与备份有关的V ...
- 阿里云数据库备份DBS商业化发布,数据库实时备份到OSS
数据库备份DBS已于2018年5月17日正式商业化发布. 数据库备份(Database Backup,简称DBS)是为数据库提供连续数据保护.低成本的备份服务. 它可以为多种环境的数据提供强有力的保护 ...
- 混合云存储组合拳:基于云存储网关与混合云备份的OSS数据备份方案
前言 阿里云对象存储(OSS)用户众多.很多用户因为业务或者合规性需求,需要对OSS内的数据做备份,无论是线上备份,还是线下备份.用户可以选择使用OSS的开放API,按照业务需求,做数据的备份,也可以 ...
- 阿里云mysql数据库恢复总结,mysql binlog日志解析
由于意外..阿里云mysql中有一张表被全部删除了,深吸三口气候,开始解决. 首先用凌晨的自动备份的,进行全量恢复,然后找binlog日志(见下文),查找从全量备份到数据删除之间的记录 这导致了一个问 ...
- 阿里云rds实例恢复到本地
摘要: 前提: 1,阿里云数据库备份实例,恢复数据的时候需要将数据恢复到本地数据库,是不能直接恢复到RDS上的. 2,需要在本地服务器上下载一个数据库,尽量和RDS数据库版本保持一致.(我现在用的是5 ...
- 阿里云rds 备份和还原
阿里云rds 备份和还原 转发:https://www.cnblogs.com/lin1/p/8617764.html 转发:https://help.aliyun.com/knowledge_det ...
- HBase(六)HBase整合Hive,数据的备份与MR操作HBase
一.数据的备份与恢复 1. 备份 停止 HBase 服务后,使用 distcp 命令运行 MapReduce 任务进行备份,将数据备份到另一个地方,可以是同一个集群,也可以是专用的备份集群. 即,把数 ...
随机推荐
- 【POJ】1287 Networking
题目链接:http://poj.org/problem?id=1287 题意:n个点,m条网线长度.求构成网络的最小网线长度. 题解:最小生成树裸题.套板子. 代码: #include<iost ...
- ArrayList、Vector、LinkedList的区别
ArrayList.Vector.LinkedList的区别 1.底层数据结构: ArrayList底层实现是动态数组 Vector底层实现是动态数组 LinkedList底层实现是双链表 2.扩容 ...
- 逻辑右移函数 srl()与算术右移函数 sra() (转)
比如一个有符号位的8位二进制数11001101,逻辑右移就不管符号位,如果移一位就变成01100110.算术右移要管符号位,右移一位变成10100110. 逻辑左移=算数左移,右边统一添0 逻辑右移, ...
- ./vimrc代码解析全
""""""""""""""""&quo ...
- python操作redis数据
一.环境安装 1.redispy安装 (automatic) C:\Users\Administrator>pip install redis 2.检测是否安装成功 (automatic) C: ...
- on windows in superset sql lab error "module object has no attribute sigalrm"
改下 utils.py 文件 It works after doing the following change (sorry for the massed up alignment, prob ...
- CF 398 E(动态规划)
传送门: http://codeforces.com/problemset/problem/398/E 题解: 首先答案不超过2. 最长环=1时,ans=0 最长环=2时,ans=1 否则,ans=2 ...
- (转)JAVA国际化
转:http://www.cnblogs.com/jjtech/archive/2011/02/14/1954291.html 国际化英文单词为:Internationalization,又称I18N ...
- (转)The connection to adb is down, and a severe error has occured. .
转:http://blog.csdn.net/yu413854285/article/details/7559333 启动android模拟器时.有时会报The connection to adb i ...
- Python-爬虫-requests库用语post登录
requests库很强大,支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的URL和POST数据自动编码. 可以发送无参数的get请求, ...