性能压测中的SLA,你知道吗?
本文是《Performance Test Together》(简称PTT)系列专题分享的第6期,该专题将从性能压测的设计、实现、执行、监控、问题定位和分析、应用场景等多个纬度对性能压测的全过程进行拆解,以帮助大家构建完整的性能压测的理论体系,并提供有例可依的实战。
该系列专题分享由阿里巴巴 PTS 团队出品,欢迎在文末处加入性能压测交流群,参与该系列的线上分享。
本文主要介绍如何正确的使用SLA来确定备容的目标,同时提高压测效率。主要分为理论和实践两个部分。
SLA无处不在
在云计算时代,越来越多企业的服务迁移到云上,各大云服务厂商有自己服务发布的SLA,比如阿里云的ECS服务器/RDS服务/REDIS服务等,都有对应的SLA,SLA是服务提供商与客户之间定义的正式承诺。
除了云服务厂商,提供各种服务的APP/网站,如果在客户在购物时无法下单/或者在周末刷着小视频的视频打不开了,这个会严重影响用户的体验,如果故障出现的时间比较久,会流失一大批的客户,给业务带来损失。那么,如何衡量给客户提供的服务质量呢?进而如何衡量系统的稳定性呢?毋庸置疑,也需要统一的语言SLA。那么,具体什么是SLA呢?
在新系统上线,大促以及系统面临大的架构调整等各种场景中,架构组以及开发人员,需要提前为系统进行备容,对系统进行性能压测,在压测过程中,与SLA又有什么联系呢?
SLA定义
服务级别协议(英语:service-level agreement,缩写SLA)也称服务等级协议、服务水平协议,是服务提供商与客户之间定义的正式承诺[维基百科定义]。SLA的概念,对互联网公司来说就是网站服务可用性的一个保证。
SLA包括两个要素,一个是SLI,一个是SLO,其中SLI定义的是测量指标;SLO定义的是服务提供的一种状态。
SLI:SLI是经过仔细定义的测量指标,它根据不同系统特点确定要测量什么,SLI的确定是一个非常复杂的过程。SLI确定测量的具体指标,在确定具体指标的时候,需要做到该指标能否准确描述服务质量以及该指标是否可靠。
SLO:SLO(服务等级目标)指定了服务所提供功能的一种期望状态,包含所有能够描述服务应该提供什么样功能的信息。一般描述为:每分钟平均qps > 100k/s;99% 访问延迟 < 500ms;99% 每分钟带宽 > 200MB/s。
设置SLO时的几个最佳实践:
- 指定计算的时间窗口
- 使用一致的时间窗口(XX小时滚动窗口、季度滚动窗口)
- 要有一个免责条款,比如:95%的时间要能够达到SLO
SLA以面向人员的维度区分,可以划分为以下两个维度。
第一:业务维度:客户对这部分的指标最有体感,直接与用户的体验好坏挂钩。
- 例如,响应时间,错误率等。有统计数据显示,如果响应时间大于1s,80%的用户就会流失掉;错误率指标,是对功能正确性的保障,如果开始有业务错误,那么客户都无法直接完成期望的操作,流失也是避免不了的。这部分的指标直接影响用户的体验。
第二:服务侧维度:描述的是服务端的指标,这部分指标主要是面向开发以及测试人员的,为了在发生问题的时候,可以快速定位问题。 - 比如,ECS/RDS等的系统指标,包括 CPU/LOAD等。
压测中的SLA
在进行性能压测设计阶段,有一个重要的环节是确定“性能压测通过标准”。缺少了这个标准,意味着压测可能是没完没了的,谁都不知道什么时候该结束,影响性能压测效果,浪费人力财力。所以需要通过“性能压测通过标准”中一系列量化下来的指标来确定,压测结果是否符合预期,可以停止了。这个"标准"的来源,可能是来自业务方的期望,研发组对系统的性能期望等等,最终整理汇总下来的我们称为压测中的SLA。这个SLA与产品对外的SLA有紧密联系,但是又存在区别。联系就是,系统对外的SLA是压测中的SLA的重要来源,而区别就是,压测中的SLA可能会涵盖更多更细的指标,而对外的SLA并不关心这么多细节。
在正确压测吗?
在压测中,看似一个简单的业务请求,实则后端是复杂的系统架构,比如统一接入层/容器层/存储层,即使容器层,也涉及到了很多不同应用/不同服务,面对纷繁复杂的架构,如何快速判断压测结果是否满足了业务需求?如何快速判断是否达到了系统的水位不能再往上施压了呢?
作为备容的一份子(开发或者测试),可以想象一下,常态是怎样的?
一声号令,开始压测!好了,A开发看A系统,B开发看B系统,C开发看网络层,D测试看压测结果等。大家手忙脚乱,这个时候,有人在群里一声喊,我的系统扛不住了,停止吧(当然还有一种风险,是不是这位同学的误判呢)。好的,这个时候压测停止。当然这种还是比较好的情况,而有些压测场景,就只有一个测试同学,他怎么分工呢?一会看看压测结果,一会看看A系统,一会看看B系统,忙得不亦乐乎。
这样压测能否达到效果,当然能。但是这样的状态是最好的一种状态吗?当然不是!这个时候SLA就派上用场了。
- 首先,开发/测试/业务同学在压测之前,对齐SLA指标,即意味着明确系统需要持续提供的服务能力,以及系统的整体水位,减少后续的沟通流程,大家都以此目标备容。
- 其次,配置好SLA之后,压测的负责人则只需要重点关注是否存在SLA告警,如果连续告警则说明系统已经扛不住了,直接停止压测或者由SLA直接停止压测。对于压测的小伙伴来说,省时省力,既不会漏掉一些指标,同时也不会浪费压测时间。
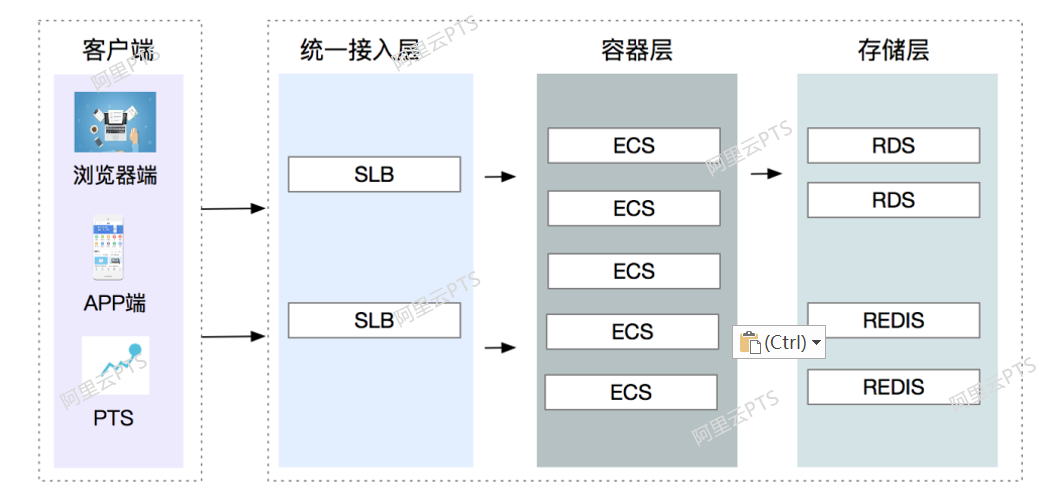
如何在PTS中正确使用SLA
想象一下,开发同学都在忙,只有“我”一个测试人员有时间全盘盯着压测。压测起来之后,直接把不合格的业务维度数据以及系统维度数据,统统通知给“我”,“我”只是决策要不要停止压测,同时直接产出系统容量水位报告,这样是不是爽歪歪?PTS就提供了这样的功能,即设置SLA。设置SLA需要基于采集到的各种指标,采集的指标越丰富,则SLA越丰富,越能满足不同业务的需求。
在具体使用中,首先了解PTS提供的指标,然后选取与自己业务相契合的指标并设置对应的阈值,最后进行压测。
首先,了解一揽子指标
监控指标,可以分为客户端相关指标,即业务维度指标;另一个是服务端相关指标。
- 客户端监控指标,是最直观的判断系统提供的服务是否满足了业务的诉求,PTS提供了RPS/请求失败RPS/响应时间等指标。
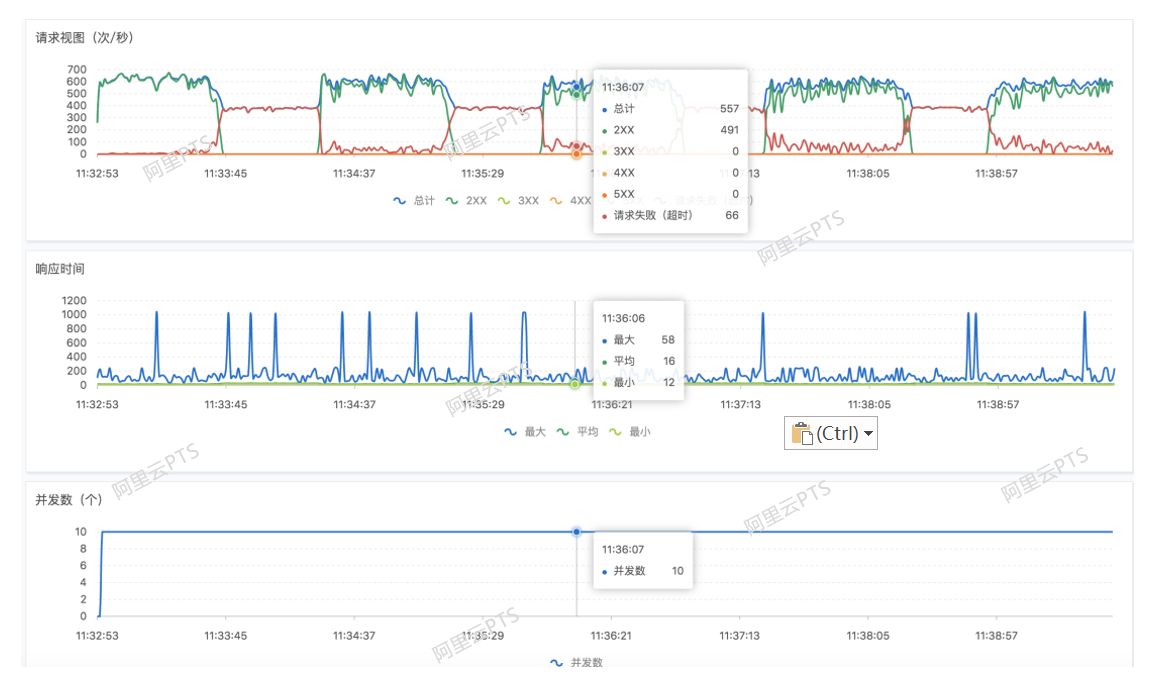
- 服务端相关指标,则是从研发人员角度区分的,一方面服务端系统的表现会直接影响客户端的各个指标,是联动的。另一方面,在客户端或者服务端出现问题的时候,可以更加方便的定位到问题。PTS服务端指标,包含了SLB/ECS/RDS等相关组件的监控数据。

第二,选取核心指标并设置阈值
- 首先,客户端的SLA指标包含了 RT/RPS/成功率三个指标,分别从 响应时间/可用性以及访问负载 描述了客户端的访问是否正常,直接反映了客户的使用体感,以及提供的核心服务是否在提供可持续性可用的服务;客户端的指标通常需要测试人员与业务方根据具体的业务具体设定。
- 成功率是一个衡量系统是否可用的核心指标。同时成功率优先考虑的是业务成功率,若未设置业务成功率,则是code码等默认的成功率。
- RT反映了客户访问网站的速度,一般情况下,互联网用户都不是特别有耐心。KissMetrics 的研究结果显示,“1 秒的网页响应延迟可能会导致转化次数减少 7%”,“47% 的消费者都希望网页能够在 2 秒内加载完毕”。
- RPS则是系统能承载的最大的RPS,也即系统容量最大水位。

- 其次,服务端的指标,包括了 SLB/ECS/RDS 三个层面的指标,每个层面的指标,由具体组件提供服务的特点决定。例如ECS指标包括 CPU/内存利用率/LOAD ;SLB指标包括 丢弃连接数/异常后端server数;RDS指标包括 CPU/内存利用率/IOPS/连接利用率;这部分的指标大部分情况下由开发人员确定,有个大的规则,比如CPU一般不超过80%,LOAD不超过核数的1.5倍等,具体情况具体分析。
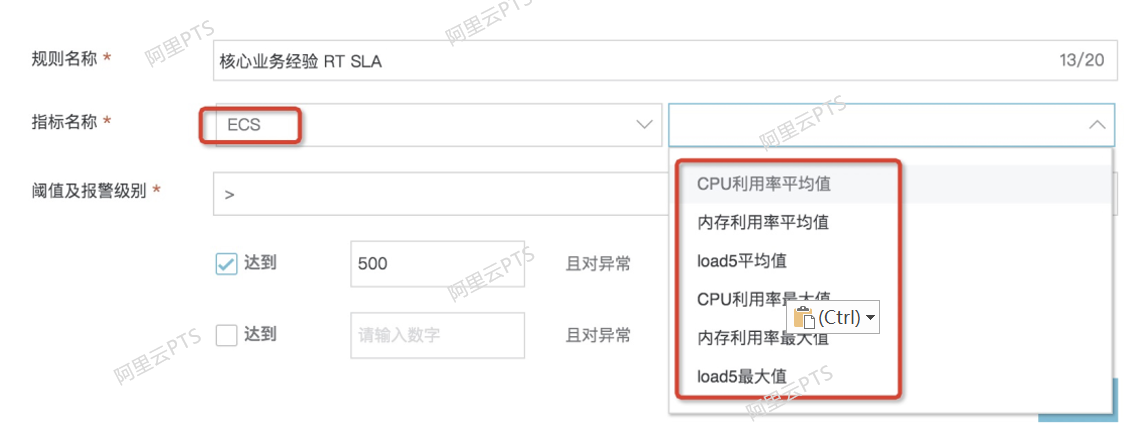
第三,选择好指标,以及为指标设置好对应的阈值之后,就可以放心的压测了。在压测中,如果触发了设定的SLA则进行报警,或者直接停止压测。同时还会有事件的汇总信息。

这样,通过前期各方对齐相应的SLA指标,并且在PTS中设置SLA,既可以对齐目标,又可以解放压测过程中的人力,很直观的看到哪些指标达到了阈值。未设置SLA之前,大家手忙脚乱的观看各种指标数据,生怕漏掉,而加了SLA之后,就可以喝着茶把压测做完。同时,除了通过设置SLA帮助小伙伴们更好的提高压测效率外,我们还会将SLA与智能压测相结合,大家敬请期待。
小结
SLA无处不在,本文主要从SLA是什么,压测过程中设置SLA的意义,以及如何正确使用SLA进行了简述。正确利用并设置SLA,让压测不再手忙脚乱。有不同意见处请指正,谢谢!
本文作者:中间件小哥
本文为云栖社区原创内容,未经允许不得转载。
性能压测中的SLA,你知道吗?的更多相关文章
- 并发模式与 RPS 模式之争,性能压测领域的星球大战
本文是<如何做好性能压测>系列专题分享的第四期,该专题将从性能压测的设计.实现.执行.监控.问题定位和分析.应用场景等多个纬度对性能压测的全过程进行拆解,以帮助大家构建完整的性能压测的理论 ...
- 性能压测诡异的Requests/second 响应刺尖问题
最近一段时间都在忙着转java项目最后的冲刺,前期的coding翻代码.debug.fixbug都逐渐收尾,进入上线前的性能压测. 虽然不是大促前的性能压测要求,但是为了安全起见,需要摸个底心里有个数 ...
- jmeter系列-如何实现像loadrunner一样,多个并发用户先通过登录初始化,然后做并发的接口性能压测
自动转开发后,就很少关注性能测试方面的东西,最近在帮朋友做一个性能压测,由于朋友那边的公司比较小,环境比较简单,而且是对http服务进行的压测,所以最终 选用了jmeter来实现这个压测. 如下就是我 ...
- 消息服务dubbo接口性能压测性能优化案例
最近项目中的消息服务做了运营商的改动,导致这个服务做了重新开发 压测脚本如下: 开启200线程压测: tps只有200-300之间,平均耗时在700ms左右 开启500线程压测 500并发压测,发现平 ...
- [SCF+wetest+jmeter]简单云性能压测工具使用方案
前言 压测太难?局域网压力无法判断服务器网络指标?无法产生非常大的并发量?云性能太贵? 也许我们可以把各种简单的工具拼起来进行压力测试! 准备 https://cloud.tencent.com/pr ...
- 软件性能测试分析与调优实践之路-JMeter对RPC服务的性能压测分析与调优-手稿节选
一.JMeter 如何通过自定义Sample来压测RPC服务 RPC(Remote Procedure Call)俗称远程过程调用,是常用的一种高效的服务调用方式,也是性能压测时经常遇到的一种服务调用 ...
- 性能测试:压测中TPS上不去的几种原因分析(就是思路要说清楚)
转https://www.cnblogs.com/imyalost/p/8309468.html 先来解释下什么叫TPS: TPS(Transaction Per Second):每秒事务数,指服务器 ...
- 性能压测,SQL查询异常
早上测试对性能压测,发现取sequence服务大量超时报错,查询线上的监控SQL: 大量这个查询,我在DeviceID和Isdelete上建有复合索引,应该很快,而且我测试了一下,取值,执行效率很高, ...
- jmeter性能压测瓶颈排查-网络带宽
问题: 有一台机器做性能压测的时候,无论开多少个线程,QPS一直压不上去,而服务器和数据库的性能指标(主要是CPU和内存)一直维持在很低的水平. 希望帮忙排查一下原因. 过去看了下进行压测的接口代码, ...
随机推荐
- 解析Spring第二天
目的:使用spring中纯注解的方式 前言:同样是使用idea创建一个普通的maven工程(如何创建一个普通的Maven工程可以参考mybatis入门第一天的详解). bean管理类常用的4个注解(作 ...
- QueryList 来做采集
示例代码 先来感受一下使用 QueryList 来做采集是什么样子. 1 采集百度搜索结果列表的标题和链接.大理石平台价格 采集代码: $data = QueryList::get('https:// ...
- pycharm中使用配置好的virtualenv环境,自动生成和安装requirements.txt依赖
1.手动建立: 第一步 建立虚拟环境 Windows cmd: pip install virtualenv 创建虚拟环境目录 env 激活虚拟环境 C:\Python27\Scripts\env\S ...
- (转)详解HttpURLConnection
请求响应流程 设置连接参数的方法 setAllowUserInteraction setDoInput setDoOutput setIfModifiedSince setUseCaches setD ...
- Linux课程---13、linux中任务计划介绍(任务计划分类)
Linux课程---13.linux中任务计划介绍(任务计划分类) 一.总结 一句话总结: 1.一次性任务计划:at 2.周期性任务计划:crontab 1.linux中如何添加一次性任务计划? at ...
- Visual Studio 2010 error C2065: '_In_opt_z_' : undeclared identifier 编译错误
当用Visual Studio 2010 编译时 发生如下编译错误: 2>C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\inclu ...
- HDU-6375-度度熊学队列-双端队列deque/list
度度熊正在学习双端队列,他对其翻转和合并产生了很大的兴趣. 初始时有 NN 个空的双端队列(编号为 11 到 NN ),你要支持度度熊的 QQ 次操作. ①11 uu ww valval 在编号为 u ...
- StringUtils工具
ppublic class StringUtils { private StringUtils() { } /** * 文本左边补零 * * @param maxLength 文本长度 * @para ...
- winform 旋转图片
//img.RotateFlip(RotateFlipType.Rotate90FlipNone); //顺时针旋转90度 RotateFlipType.Rotate90FlipNone //逆时针旋 ...
- Python全栈开发:基本数据类型
1.数字 int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位系统上,整数的位数为64位,取值范围为-2 ...